
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
ssd 학습 결과 궁금증
21.10.01 13:59 작성 조회수 240
0
안녕하세요 선생님,
SSD 모델로 학습을 진행하고 있는데 생각보다 오탐지(false positve?)가 너무 많이 잡히고 있습니다.
yolo에서는 이렇게 잡히지 않았는데...
이유가 궁금하여 지금 학습하고 있는 config file을 길지만 올렸습니다..(죄송합니다)
tensorflow의 ssd를 사용했습니다.
mmdetection을 사용하면 결과가 또 다르게 나올까요??
focal loss하고 hard example miner 둘 다 확인해봤습니다.
focal loss도 똑같이 오탐지를 하면서 단지 학습의 확신을 주는 느낌으로 밖에 안 느껴졌습니다.!!

답변을 작성해보세요.
0

권 철민
지식공유자2021.10.05
Detect 하려는 오브젝트가 사람 1개 뿐인데, 보통은 성능이 그렇게 나빠질 이유가 없어 보입니다만,,,,
문제가 뭔지 tensorflow object detection API로는 잡기가 어려워 보입니다. 그냥 Tensorflow object detection API는 좀 다루기가 어렵습니다.
다른 package로 해보시면 어떨지요? mmdetection이나 강의에 있는 ultralytics yolo, efficientdet으로 하면 당연히 좋은 성능이 나올것 같습니다.
만약 tflite나 mobile용 변환이 필요하셔서 tensorflow object detection API를 사용하시는 거라면 강의에 있는 automl efficientdet을 적용해 보심은 어떨지요? efficientdet으로 만들어진 모델을 tflite로 쉽게 변환할 수 있습니다. 성능도 더 뛰어나고요.
0

guentc1
질문자2021.10.04
안녕하세요, 선생님.
제가 너무 설명이 부족했던 것 같습니다.
Tensorflow object detection API를 이용하여 custom data로 학습을 진행하고 있습니다.
(맞습니다.. 개정판 강의에서는 커스텀 데이터로 학습하는 강의가 없습니다..하하..^^;;)
현재 학습된 데이터는 제가 학습을 진행하지 않아서 train 몇 장, val 몇 장인지는 정확하게 모르겠습니다.
들은 바로는 40만장?으로 이미지 수는 충분한 듯 보였습니다.
그리고 person 클래스 1개만 설정하고 학습을 진행했습니다.
사람을 잡고는 있지만 background 또한 사람으로 인식하고 있는데 과하게 background를 많이 잡는 모습을 보여주고 있습니다.
처음에는 단순히 overfitting하게 학습을 진행했거나 아니면 데이터가 제대로 정리되어있지 않거나 또는 모델 파라미터가 잘 못 되었지 않았을까 하고 생각했습니다.
막상 train 1000장 val 250장으로 테스트해본 결과, background를 많이 잡는 것을 볼 수 있었습니다.
yolo 같은 경우에는 데이터가 부족하여도 사람을 인식률이 떨어졌지 background를 계속 사람으로 잡고 있지는 않았던 것으로 기억하고 있습니다.
생각보다 SSD는 이상하게도 사람과 background를 골고루 잡고 있는 모습이 보였습니다.
현재 background를 사람으로 잡는(오탐지)를 후처리 전에 최대한 줄이고자 진행하고 있습니다.
아래 부분은 제가 많이 부족하여 사진(tensorboard 내용)으로 남겼습니다.
mAP, 또는 다른 평가 지표가 클래스 별로 어떻게 되는 건지 자세한 정보 부탁드립니다.
꼭 해답이 아니더라도 첨언을 해주신다면 정말 감사드립니다.
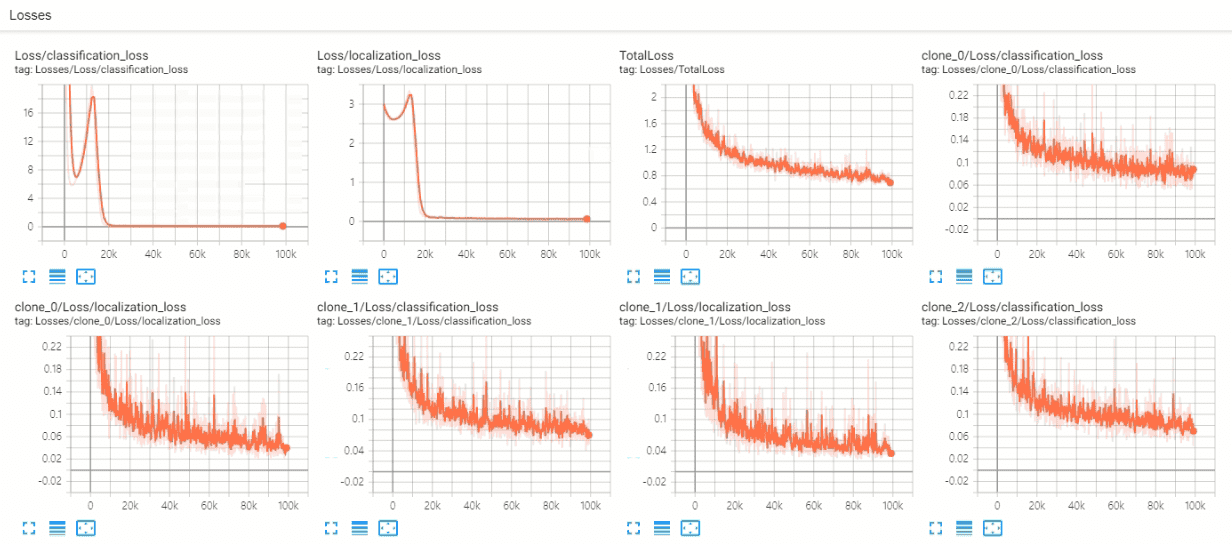
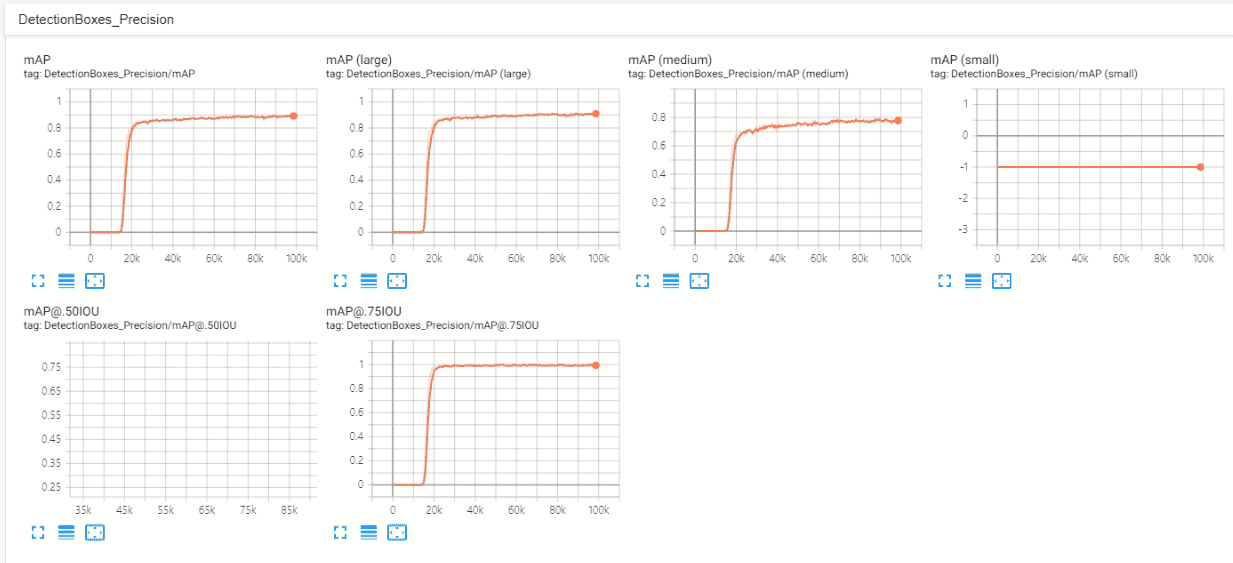
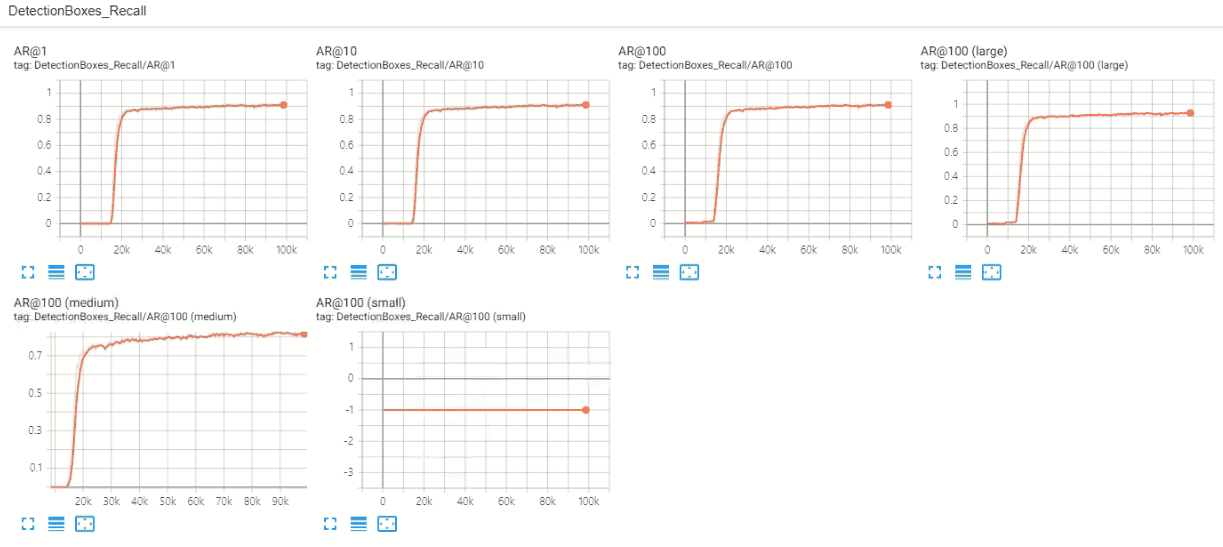
0
권 철민
지식공유자2021.10.01
안녕하십니까,
COCO로 Pretrained 된 모델을 이용하여 inference시에 성능이 잘 안나오는건지 아님 이게 tensorflow object detection API를 이용하여 커스텀 데이터로 학습 한 결과가 잘 안나온다는 건가요? (개정판 강의에서 ssd를 커스텀 데이터로 학습하는 강의가 없습니다만,,,)
false positive가 많이 나온다는데, 어떤 학습 데이터 세트를 구성하였고, mAP가 클래스별로 어떻게 나온다는 것인지요? 좀 더 자세하게 이미지 데이터 건수는 어떻게 되는지, tensorflow object detection api를 사용하신건지, 몇개의 클래스로 되어 있는건지, mAP, 또는 다른 평가 지표가 클래스 별로 어떻게 되는 건지 자세한 정보 부탁드립니다.

답변 3