
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
미해결
[5.2 업종 테마 데이터 전처리] 시가총액 수치형태로 만들기 관련 문의
21.10.24 19:06 작성 조회수 143
1
안녕하세요 강사님!
우선 좋은 강의 만들어 주셔서 대단히 감사 드립니다.
다름이 아니라 강의를 듣던 중 아래와 같이 질문이 있어 문의 남깁니다.
제가 궁금한 부분은 아래에 나와 있는 파트 입니다.
- 강의부분 : (5.2) 업종/테마 전처리, [2/10] 코스피 코스닥 시가총액 전처리 - 정규표현식은 그저 거들 뿐 (10:00 ~ 12:00 사이)
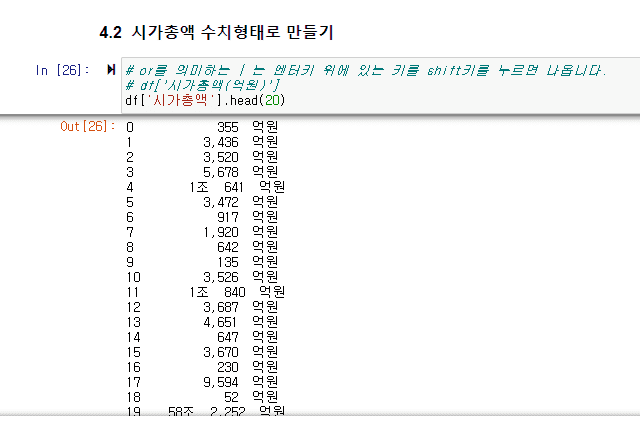
위 이미지와 같이 시가총액을 조회 후 수치형태로 만들어 주기 위해 '억원' 뿐만 아니라 '조'단위 부분도 replace를 통해 없애주게 되는데요.
하지만 인덱스 4번의 경우 시가총액이 1조 641억원인데 아래와 같이 수치가 1641로 바뀌고 있습니다.
(즉, 10641억원이 아닌 1641억원으로 데이터가 반환되는 전처리 오류가 발생합니다.)

이런 경우 데이터 전처리가 잘못되게 될 거 같은데
아직 제가 파이썬 문법을 많이 아는 것이 아니어서 이런 경우엔 어떻게 전처리를 해주면 좋을 지 궁금합니다.
날씨가 갑작스레 많이 쌀쌀해졌는데 건강 유의 하시길 바랍니다!
감사합니다.

답변을 작성해보세요.
1

1

박조은
지식공유자2021.10.24
안녕하세요.
오류로 혼란을 드려서 죄송합니다. 조 단위 이하의 값을 고려하지 못했네요.
아래의 방법으로 조 단위 백자리 값을 채워볼 수 있습니다.
# "시가총액을" 원본을 "시가총액(억원)"에 새로운 컬럼을 만들어 같은 값을 넣습니다.(사본생성)
df["시가총액(억원)"] = df["시가총액"]
# "시가총액"에 "조"가 들어가지만 천단위가 아니라 , 가 들어가지 않는 값에 조 뒤에 0을 추가하도록 합니다.
df.loc[df["시가총액"].str.contains("조") &
~df["시가총액"].str.contains(","), "시가총액(억원)"] = df["시가총액"].str.replace("조", "조 0")
# "시가총액(억원)"이 잘 변경되었는지 확인합니다.
df.loc[df["시가총액"].str.contains("조") &
~df["시가총액"].str.contains(","), "시가총액(억원)"]
# regex=True 는 수업에서는 사용하지 않았지만 경고메시지가 나와 추가했습니다. 없어도 동작합니다.
df["시가총액(억원)"] = df["시가총액(억원)"].str.replace("억원", "", regex=True)
df["시가총액(억원)"] = df["시가총액(억원)"].str.replace("조|,", "", regex=True)
df["시가총액(억원)"] = df["시가총액(억원)"].str.replace(" ", "", regex=True)
df["시가총액(억원)"] = df["시가총액(억원)"].str.strip()
df["시가총액(억원)"] = df["시가총액(억원)"].astype(int)
df["시가총액(억원)"]
# 변경된 값 확인하기
df.loc[df["시가총액"].str.contains("조") & ~df["시가총액"].str.contains(","), ["시가총액", "시가총액(억원)"]]



답변 2