
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
extracted feature를 통한 clustering 질문드립니다
21.10.20 06:37 작성 조회수 343
0
안녕하세요. 저번에 건축가 관련 classification으로 질문 글 남겼었는데, 추가적으로 진행하다가 막히는 부분이 있어서 질문 드리러 왔습니다~~
저번에는 accuracy를 올리는데에 집중 하였는데, 데이터셋에서 확연하게 특징이 드러나지 않아서 73.5%정도로 정확도는 만족을 하고 결과물을 해석하는 방법에 집중을 해보고 있습니다.
제가 하고 있는 프로젝트는 건축가들 중에 우수한 상을 받은 40명 정도의 건축가가 디자인한 빌딩들의 이미지를 모아서 cnn으로 feature들을 추출하고 여기에서 나타나는 유사성들을 class마다 비교하거나 비슷한 특징을 보이는 건축가들을 clustering하는 등의 작업을 목표하고 있습니다. 조금 더 말씀드리자면 각 건축가마다 '시각적인' 부분에 집중하여 디자인 유사성을 조금 더 객관적인 방법 (through the lens of artificial intelligence)으로 조사해보고자 함입니다. 예를 들면, 모더니즘, 해체주의 등의 스타일을 시대적, 아이디어적 등 다양한 factor들을 고려하여 분류하지만 제 개인적인 생각으로는 이 부분이 주관적인 요소가 많다고 생각이 들어서 조금 객관화시켜 보고 싶었습니다.
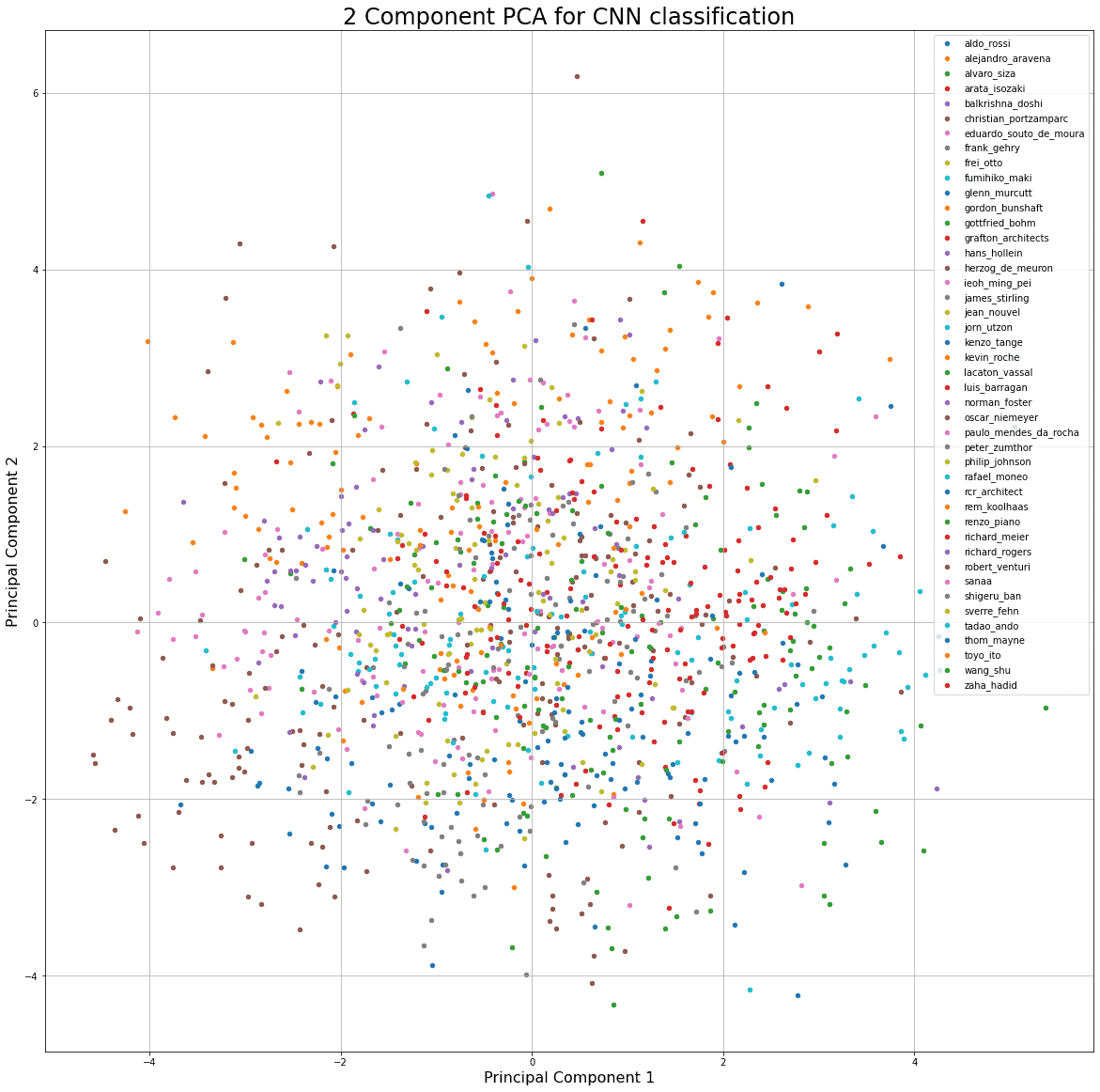
먼저 제가 해본 방법은... 마지막 dense layer의 인풋값들을 pca로 차원축소하고 거기에 나온 값들을 클래스로 평균을 내어서 클래스를 대표하는 포인트를 2차원 좌표값으로 만들어서 클래스간의 유사도 비교(?)를 해보는 것이었습니다.. 하지만 제 도메인 지식으로 당장 직관적으로 와닿는 결과물이 아니라서, 모델이 어떤 특징과 스타일을 추출하긴 했지만 인간의 눈으로 바로 직관적으로 이해할 수 있는 것이 아니다라는 결론을 내리고, 더 좋은 방법이 없을까 찾아보게 되었습니다. (validation 데이터로 pca 후, 평균)
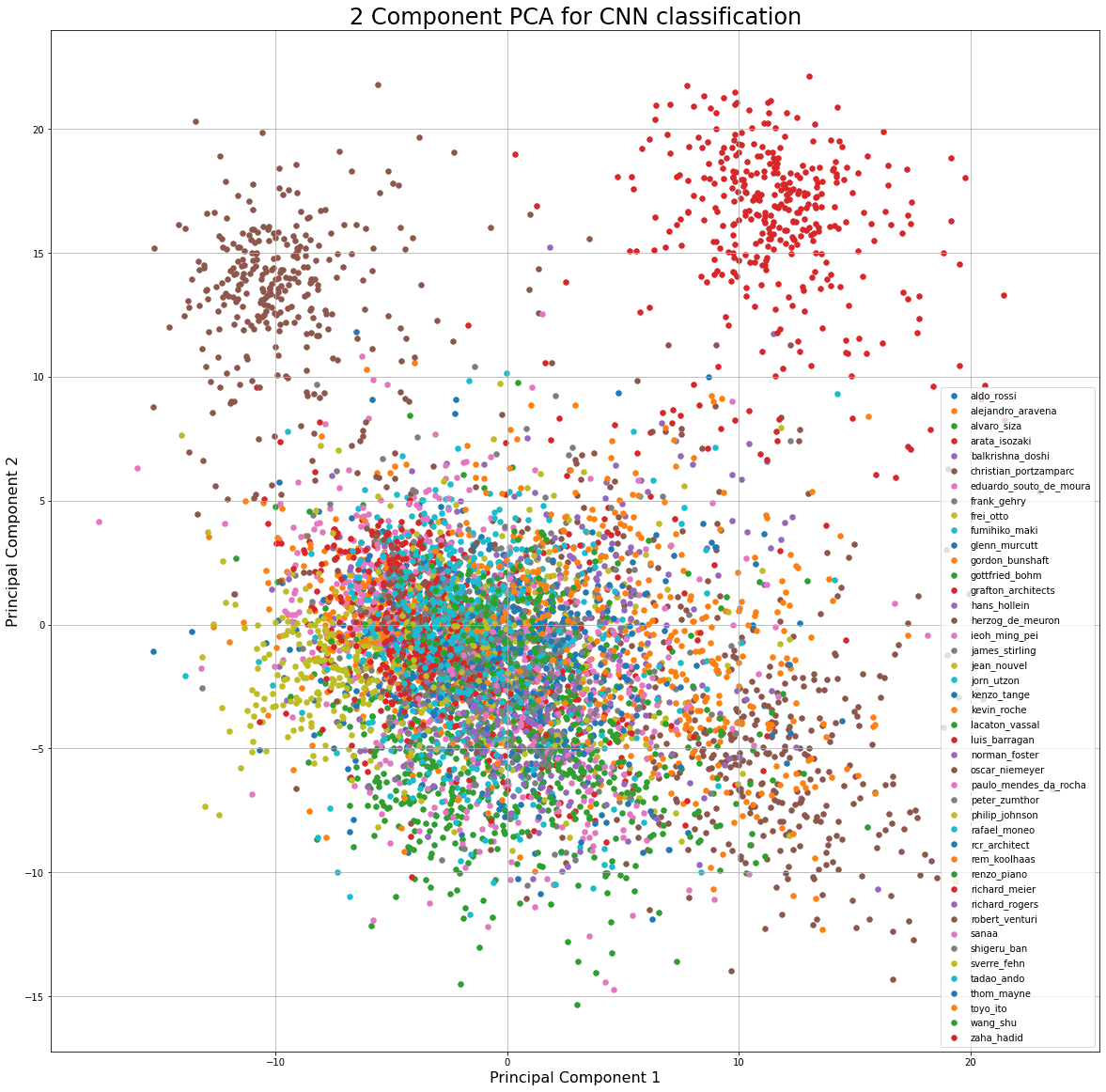
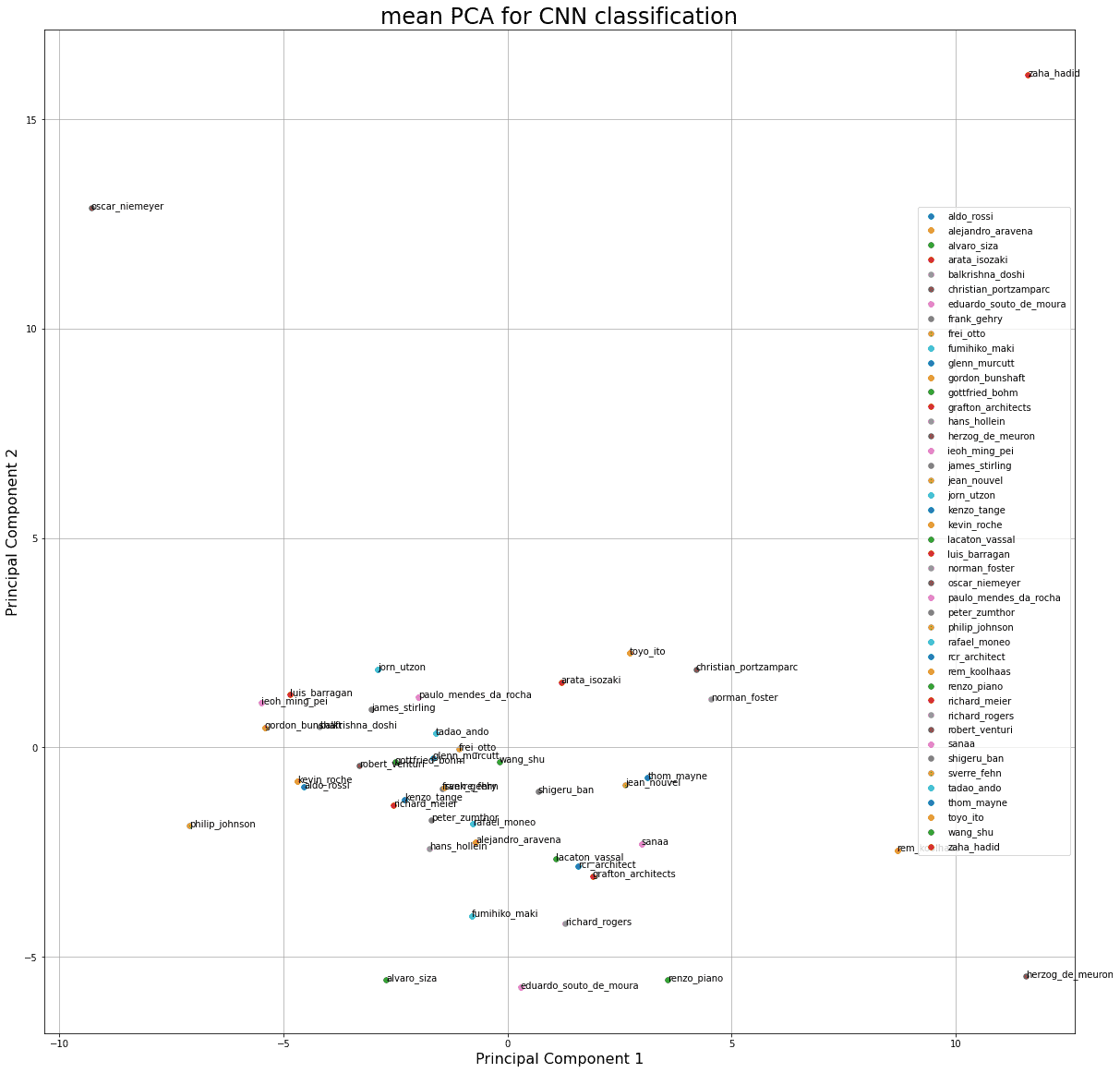
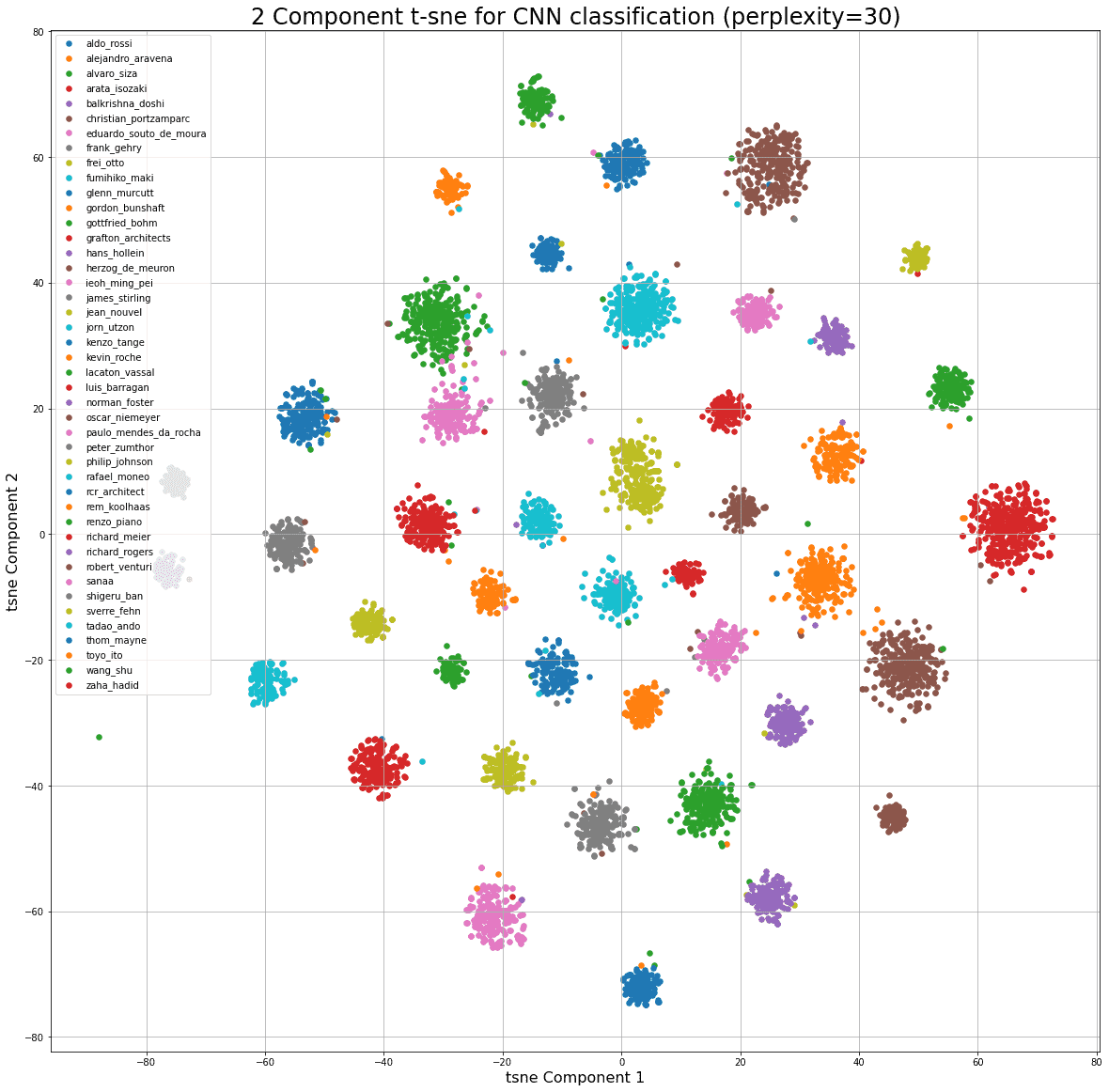
t-sne로 해보았을 때에는 명확하게 뭔가가 나와서 분명 비선형적인 관계가 있는 것 같긴 합니다...
코사인 유사도도 해보았는데, 벡터가 고르게 펼쳐져있는게 아니라서 range가 -1~1을 커버하지 않더라구요... (-1~1로 노멀라이즈는 코사인이 스타일의 반대방향도 의미하는걸 고려해봤을때에 적절해보이지 않는 방법이라고 생각해서 하지 않았습니다.)

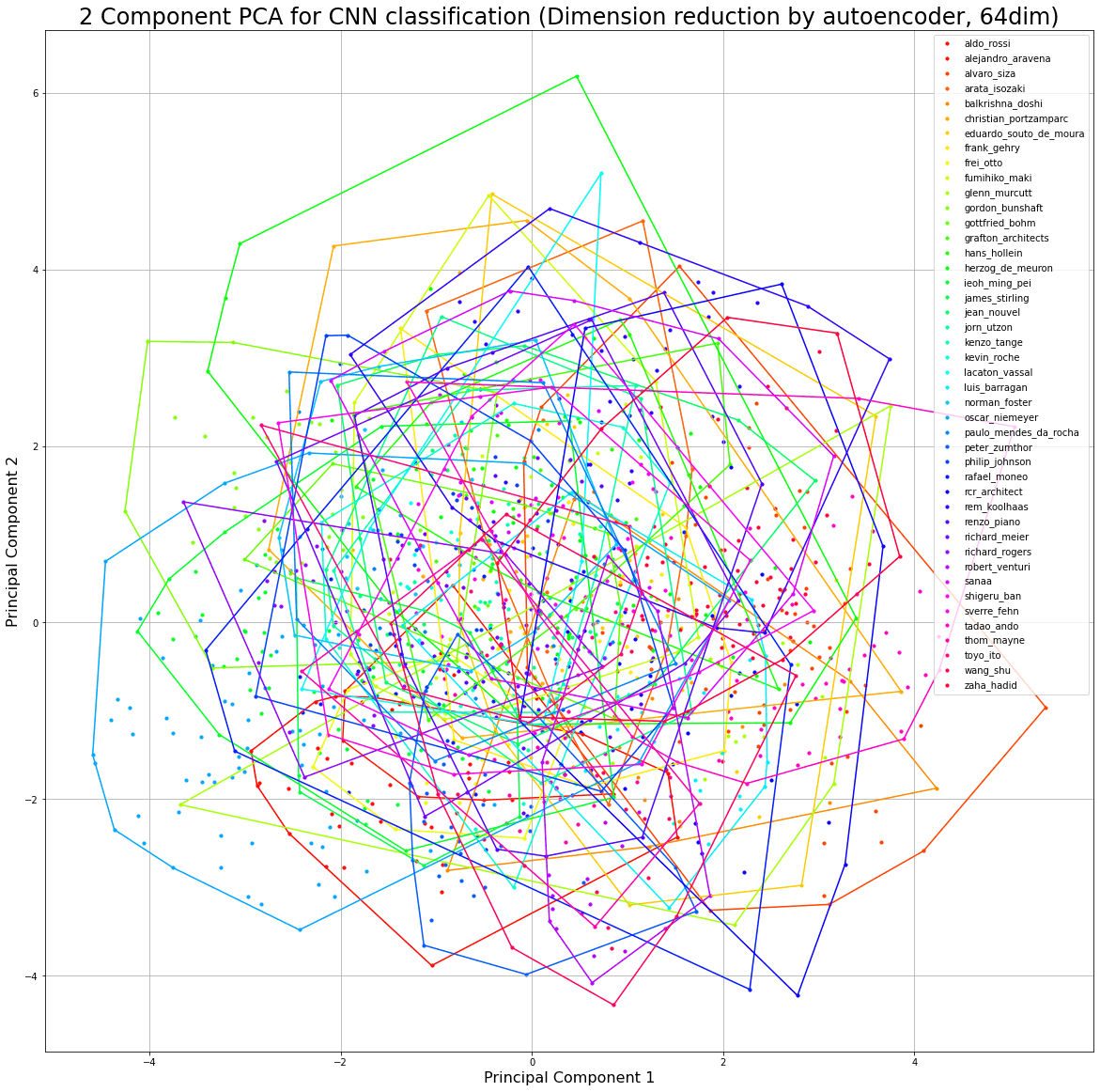
여기에서 dense 레이어에 들어오는 인풋을 pca하면서 손실되는 정보들이 많다는 생각이 들어서... CNN backbone에서 나오는 피쳐값들을 (약 1700dim) 오토인코더의 인풋으로 써서 64차원 정도로 압축하고 (오토인코더를 pca처럼 사용해보았습니다) 이 벡터를 사용해보고자 했습니다. 64차원 벡터들의 코사인유사도 결과입니다
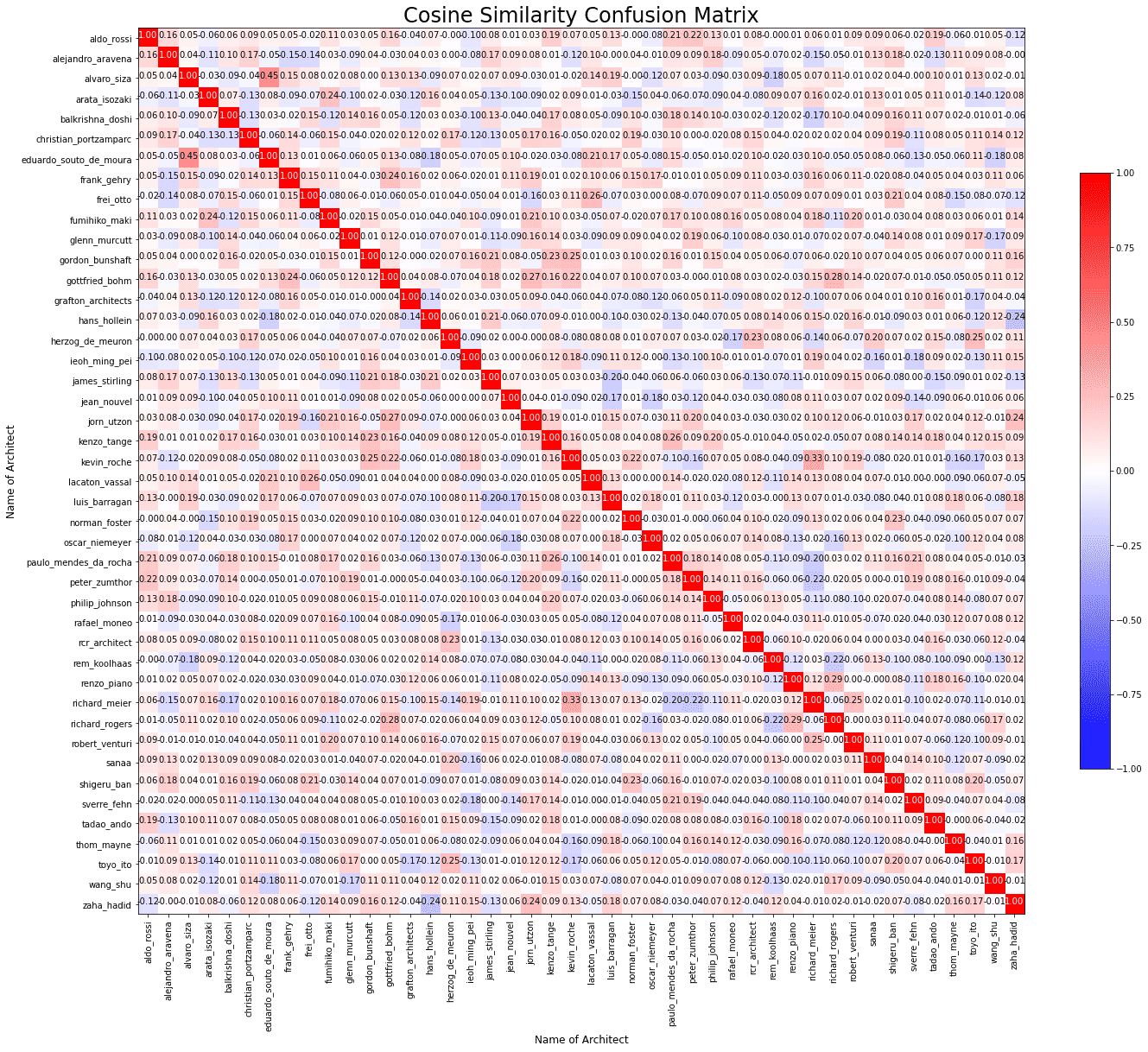
뭔가 클래스마다 비교가 되기는 하는데 1:1 비교에 초점이 맞춰진거 같아서... 조금 더 큰그림을 보고 싶은 상태입니다..
일단 오토인코더가 피쳐들을 정말 피쳐들을 학습하는게 맞을까?라는 생각이 들었습니다. 오토인코더가 정말 피쳐를 학습한다면 같은 클래스끼리는 비슷한 위치의 latent space에 존재해야 한다고 생각했고, 이것을 추상적으로 증명(?)하기 위해서는 클래스마다 벡터들을 모으고 그 벡터들의 convex hull을 구해서 (클래스의 bounding box를 찾는 개념(?), 각 클래스마다 벡터 스페이스에서의 부피값(?)) 이것들의 부피를 구하고 클래스마다 비교하면 어떤 클래스가 sparse하게 존재하고 어떤 클래스는 dense하게 밀집되어 있는지를 비교할 수 있을 것 같은데... 64차원에서 convex hull까지는 구했는데 어떻게 부피(?)를 구할지 기술적(?), 수학적(?)인 한계에 부딪혀서, 일단 64차원이 아닌 pca된 차원에서 해보았는데,... 큰 발견을 하지는 못한거 같습니다.
이것저것 제가 시도할 수 있는 것들은 많이 해보았는데, 조금 막다른길에 부딪힌것 같아서 혹시나 제가 모르고 있는 부분이나 놓치고 있는 부분이 있는지 여쭤보고 싶어서 질문글 남깁니다ㅠㅠ
각각의 인풋들을 오토인코더에서 나온 64차원의 feature들과 그래프로 연결하고 여기서 weight가 낮은 값들의 연결을 끊는 방식(?)으로 하면 연결이 끊겨져 나가면서 자연스럽게 클러스터링 비슷하게 될 것 같지 않을까...하는 추상적인 생각도 떠오르는데 명확하질 않은 것 같네요...

답변을 작성해보세요.
0

권 철민
지식공유자2021.10.20
안녕하십니까,
오, 대단한 수준으로 프로젝트를 수행하고 계시는군요.
일단 제가 이미지의 feature map을 기반으로 clustering을 해본 경험으로는 classification에 비해서 성능이 떨어지는 부분들이 있었습니다.
그런데 수행하시는 부분은 아래와 같이 다양한 factor들을 주관적인 요소에서 보다 객관적인 요소로 분류해 보고 싶으신것 같습니다만, 제 생각은 이 factor들을 객관적인 요소로 할당하기는 어렵습니다.
"예를 들면, 모더니즘, 해체주의 등의 스타일을 시대적, 아이디어적 등 다양한 factor들을 고려하여 분류하지만 제 개인적인 생각으로는 이 부분이 주관적인 요소가 많다고 생각이 들어서 조금 객관화시켜 보고 싶었습니다. "
저도 이런 비슷한걸 수행해 본지 넘 오래되어서 기억이 가물하지만, 거의 수행하신 부분과 유사하게 적용한 것 같습니다.
1. 마지막 feature map의 출력 결과에서 GlobalAveragePooling2D 적용한 결과를 기반으로 함.
2. 이걸 PCA의 n_components를 100으로 설정하여 차원 축소
3. 시각화는 이 PCA 결과를 T-SNE로 표현
4. 클러스터링은 해당 PCA 결과를 K-Means로 적용.
저는 이미지의 classification 대비 clustering 효과를 검증하기 위해서 적용한 방법이어서, 아마 원하시는 조언과는 다르 실 수 있습니다. 다만 앞에서도 말씀드렸듯이 feature map 결과에 대해서 factor 기반으로 clustering을 할 수는 있겠지만, 이걸 객관적인 요소로 변환하기는 어렵습니다.

답변 1