
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
RPN와 앵커박스에 관련되 제가 잘 이해 하고 있는건지 확인을 위해 질문 드립니다.
20.12.23 19:23 작성 조회수 433
1
안녕하세요 선생님
현재 해당 강의를 잘 듣고 있습니다. 현재 YOLO 까지 들었지는 머리속에서 계속 상상만 하고 확신이 없는
앵커 박스의 학습 부분에 대해서 제가 생각하고 있는것이 맞는지 확인을 위해 질문을 드립니다.
질문 만들때 사용한 ppt자료 링크 : https://drive.google.com/file/d/1By2GwX__OACZNL9CPF-D71o3o2G6njXI/view
현재 제가 이해하고 있는 CNN 계산
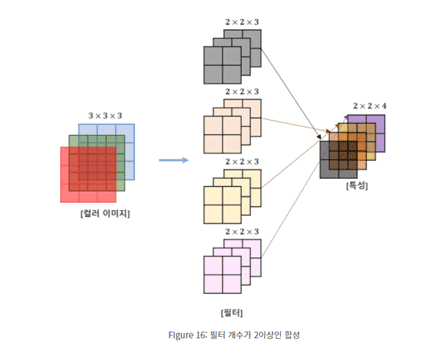
강의 내용중
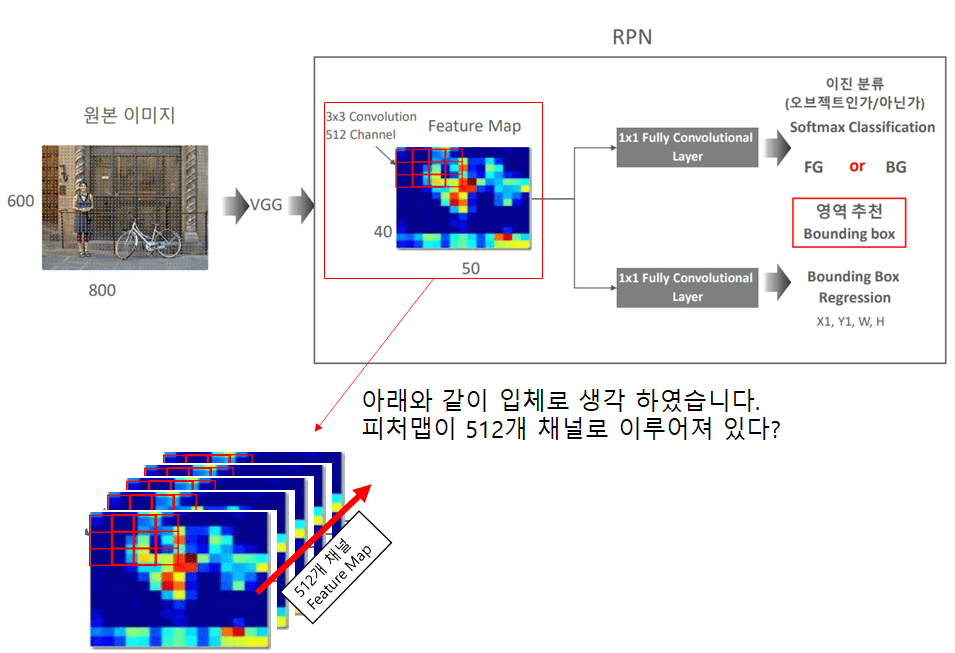
아래 해당 하는 과정을 아래와 같이 이해 하였습니다.
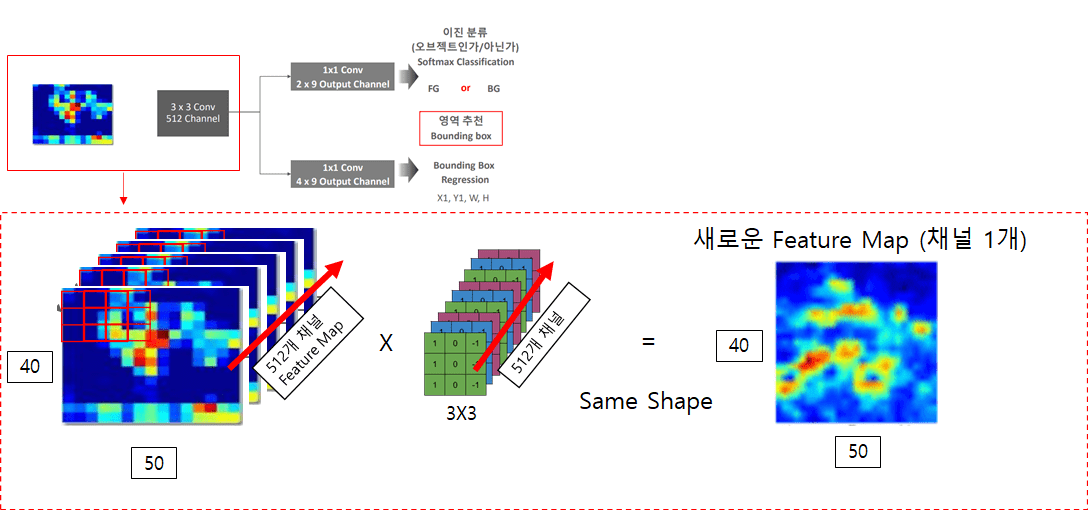
이제 저의 머리속에서 제일 확신이 없는 부분이 아래 부분들 입니다.
1x1 conv 2x9 output 채널
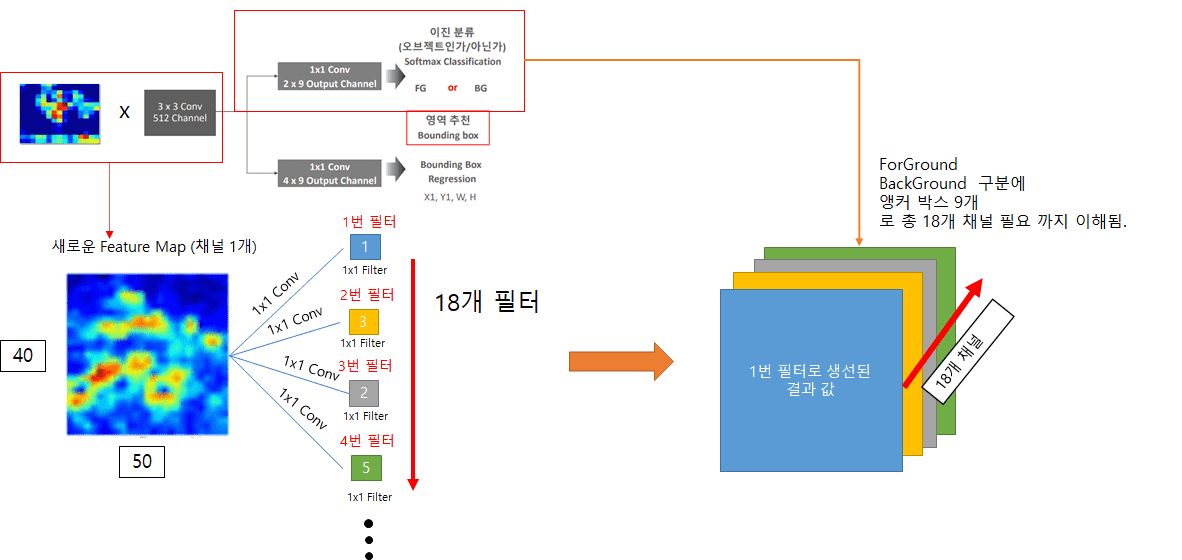
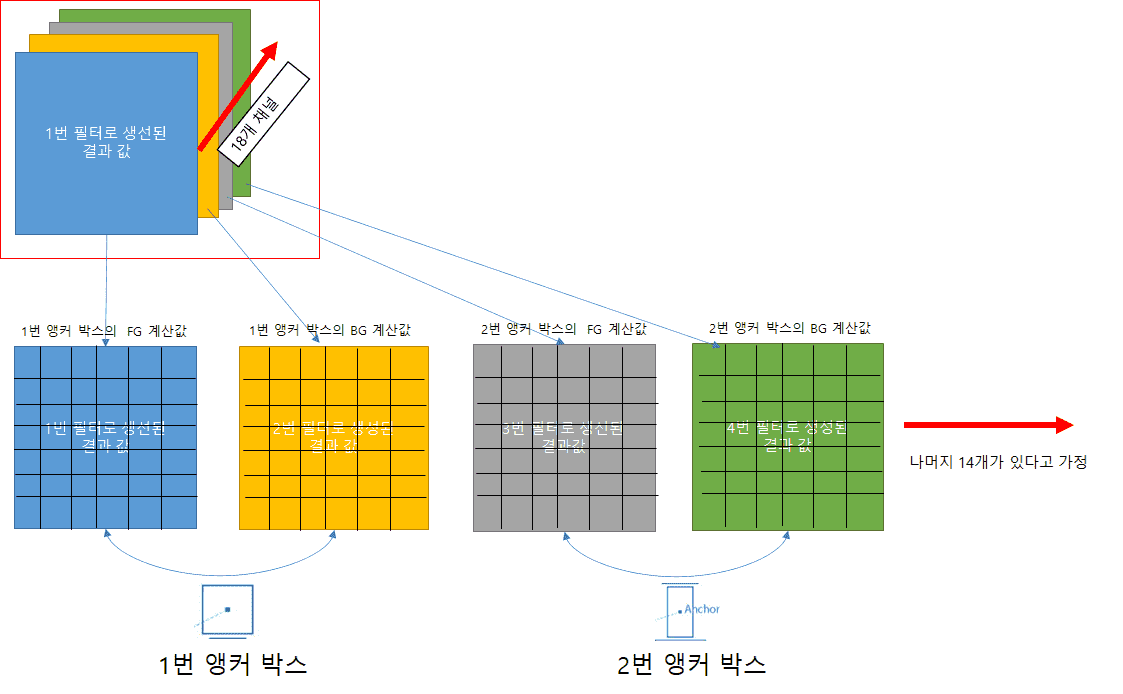
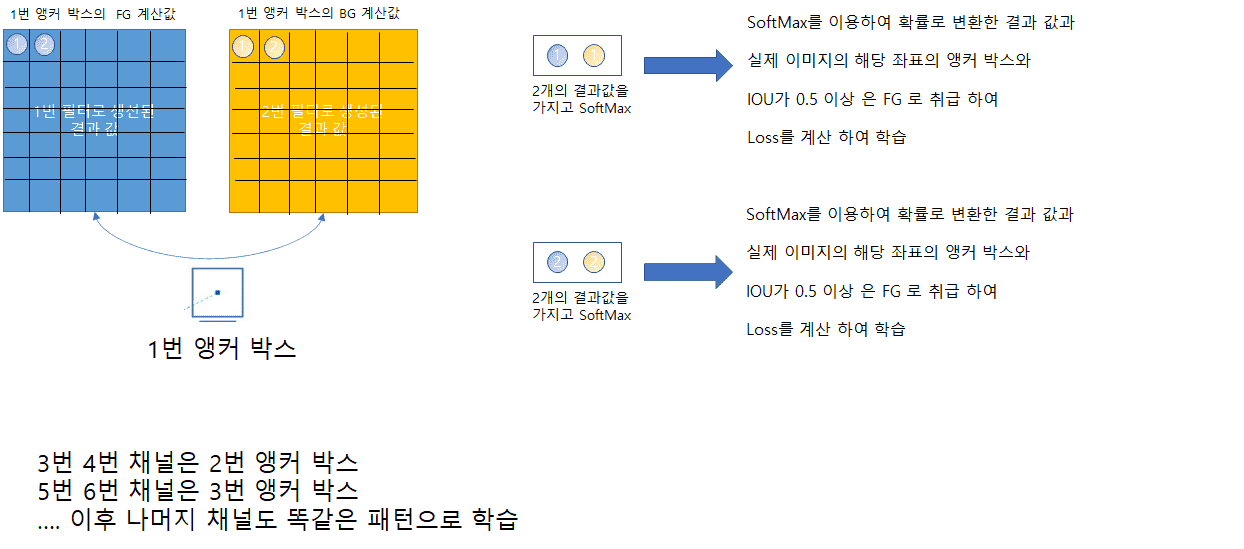
제가 생각한 부분의 오류가 없는지 궁금합니다
왜냐면 이후 SSD YOLO RESNET 등등에서 똑같이 앵커 박스 학습 부분에서 1x1 conv 필터 개수로 채널을
제어 하고 제어할 갯수는 Predict 할 값의 갯수로 조절하기 때문입니다.
제가 잘못 이해 하고 있는 부분이 있다면 말씀해 주시면 감사하겠습니다.
너무 상상만 하니 이 생각 저 생각 어렵네요 ㅜㅜ

답변을 작성해보세요.
1

권 철민
지식공유자2020.12.23
안녕하십니까,
아이고 대단하시군요. 이렇게 풀어서 자세하게 설명을 하실 정도라니, 놀랐습니다...
네, 생각하신것이 맞습니다. 한가지 첨언 드리자면, 논문에는 2x9개(9개는 anchor갯수) channel 갯수로 1x1 convolution하는걸로 되어 있어서, 이 경우는 구현시 softmax로 fg/bg 구분하겠지만, 구현 시에는 9개 channel 갯수로 1x1 convolution 연산하되 activation을 sigmoid로 이진 분류하는 방법으로 더 편리하게 구현할 수 있습니다.
감사합니다.
0
권 철민
지식공유자2020.12.30
Hgyoon 님, 심도 있는 질문의 연속이군요.
1. IOU 값에 따른 학습 여부는 구현하는 소스별로 달라질수 있습니다. 이건 저도 참조해야 겠습니다.
2. 논문에는 Regression Loss + Classification Loss 감소 최적화여서, 이론적으로는 그렇게 계산한다고 생각하셔도 무방합니다만, 실제로 이렇게 Loss값을 더해서 최적 Loss값을 구하기는 고려해야할 사항이 많습니다. 가령 loss값 1 이라도 Regression Loss 0.1, classification loss 0.9 일수 있고, 각각 0.5, 0.5 일 수 있습니다. 더구나 더하기를 하면 classfication loss와 regression loss의 scale을 맞춰야 하는 문제도 있습니다.
일반적으로 이런 경우는 multiple loss를 적용합니다. Keras는 multiple loss를 구현할수 있도록 model.compile()에서 지원합니다. 즉 regression loss reg_loss객체와 classification loss clf_loss 객체가 있다면 model.compile(optimizer='sgd', loss=[reg_loss, clf_loss], ) 와 같이 multiple loss를 적용해서 각각 loss가 최소화되서 전체 loss가 최소화되는 방향성으로 최적화를 할수 있습니다.
감사합니다.
0

BACK HO KIM
질문자2020.12.30
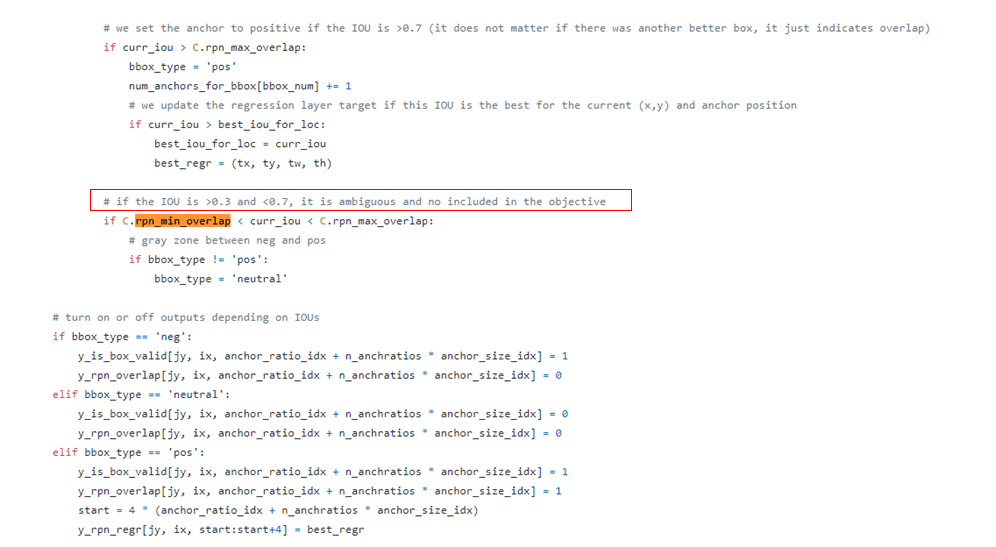
출처: https://github.com/anandhupvr/rpn-tf/blob/master/loader/data.py
실제 오픈소스의 RPN 구현 코드내에 보니 hgyoon 님이 말씀 하신 부분이 들어가 있네요 .
이렇게 또하나 배우네요. 감사합니다. 하지만 계산 부분을 디테일하게 머리속에 잡아 넣기가 쉽지 않네요 .
개괄 적으로 선생님이 말한 부분의 내용을 따라가지만 디테일한 계산 부분에서는 깊이가 있는것 같아 이해하기가 쉽지는 않네요.
그나마 강의를 봐서 해당 관련된 부분을 오픈소스 내에서 찾을수 있었네요 ^^
0
Hgyoon
2020.12.30
저도 Faster RCNN 관련 structure 이해가 부족한 것 같아 계속 고민하고 있던 찰나에 좋은 모식도 감사드립니다.
다만
1) IOU 관련해서, IOU > 0.7인 것을 Positive (Foreground), IOU < 0.3인 것을 Negative (Background)로 labeling하고, IOU 0.3-0.7인 Anchor Box들은 아예 학습을 안 시키는 것이 아닐지요. (위 모식도엔 IOU = 0.5를 기준으로 Positive/Negative를 가르고 모든 Anchor Box를 다 학습에 사용하는 것처럼 나와있는 것 같아서요)
또 Batch 단위로 학습시킬 때 Positive/Negative에서 각각 동일 sample 수만큼 추출을 해서 한 Batch 내에 50%/50% 비율을 맞춰주고요.
2) (이건 강사님께 질문) Faster RCNN 관련해서 처음에 헷갈렸던 부분이 역전파 과정에서 Classification 부분과 Regression 부분의 계산인 것 같습니다. Loss function 공식을 보면 Classification loss와 Regression loss를 합치는 것으로 되어있는데,
그러면 위 모식도에서 (3 x 3) x 512 channel 의 parameter를 갱신할 때는
(1번 anchor box의 classfication을 위한 output node 2개로부터 오는 loss) + (1번 anchor box의 regression을 위한 output node 4개로부터 오는 loss) +
(2번 anchor box의 classfication을 위한 output node 2개로부터 오는 loss) + (2번 anchor box의 regression을 위한 output node 4개로부터 오는 loss) +
....
(9번 anchor box의 classfication을 위한 output node 2개로부터 오는 loss) + (9번 anchor box의 regression을 위한 output node 4개로부터 오는 loss)를 loss function으로 계산한다고 보면 될지요.
즉 위 모식도의 출력층은 classification을 위한 2개 x 9 set의 node와 regression을 위한 4개 x 9 set의 node의 순서대로 정렬되어 있지만, 사실 이건 (2개 + 4개) x 9 set로 실질적으로 구성되어있는게 맞겠지요?
각각의 (2개 + 4개)의 node는 특정 centroid를 중심으로 하는 특정 사이즈의 어떤 anchor box가 들어왔을 때 이 box 내에 물체가 있는지 없는지 (2개)와 box 위치/크기를 regression 할지 (4개)로 이루어지는 거고요. 즉, 예를 들어 128 x 128 anchor box에 대한 (2개 + 4개) node로부터 오는 loss는 256 x 128 anchor box에 대한 (2개 + 4개) node와 서로 영향을 주지 않으면서 독립적으로 역전파 되어오는 것이고, 단지 (3 x 3) x 512 channel 의 parameter를 갱신하는 과정에서 loss가 합쳐진다고 이해하면 될까요?
말로 풀다보니 다소 장황해졌네요.
감사합니다.
0
BACK HO KIM
질문자2020.12.23
선생님 감사합니다. 답변을 해주시니 궁금증이 풀려 시원하네요 ^^
좋은 강의를 제공해 주셔서 감사합니다. 선생님 덕분에 머신러닝 비전의 입문이 한결 편해 진것 같습니다 !

답변 5