
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
해결됨
Truncated SVD, PCA, NMF 관련 질문 드림
21.07.29 15:23 작성 조회수 343
0
강사님 안녕하세요? 이번단원에서 유독 질문을 많이 드리게 되네요 ^^;;
질문1) Feature engineering 방법론 측면 TSVD-PCA 활용 관련 경우의 수
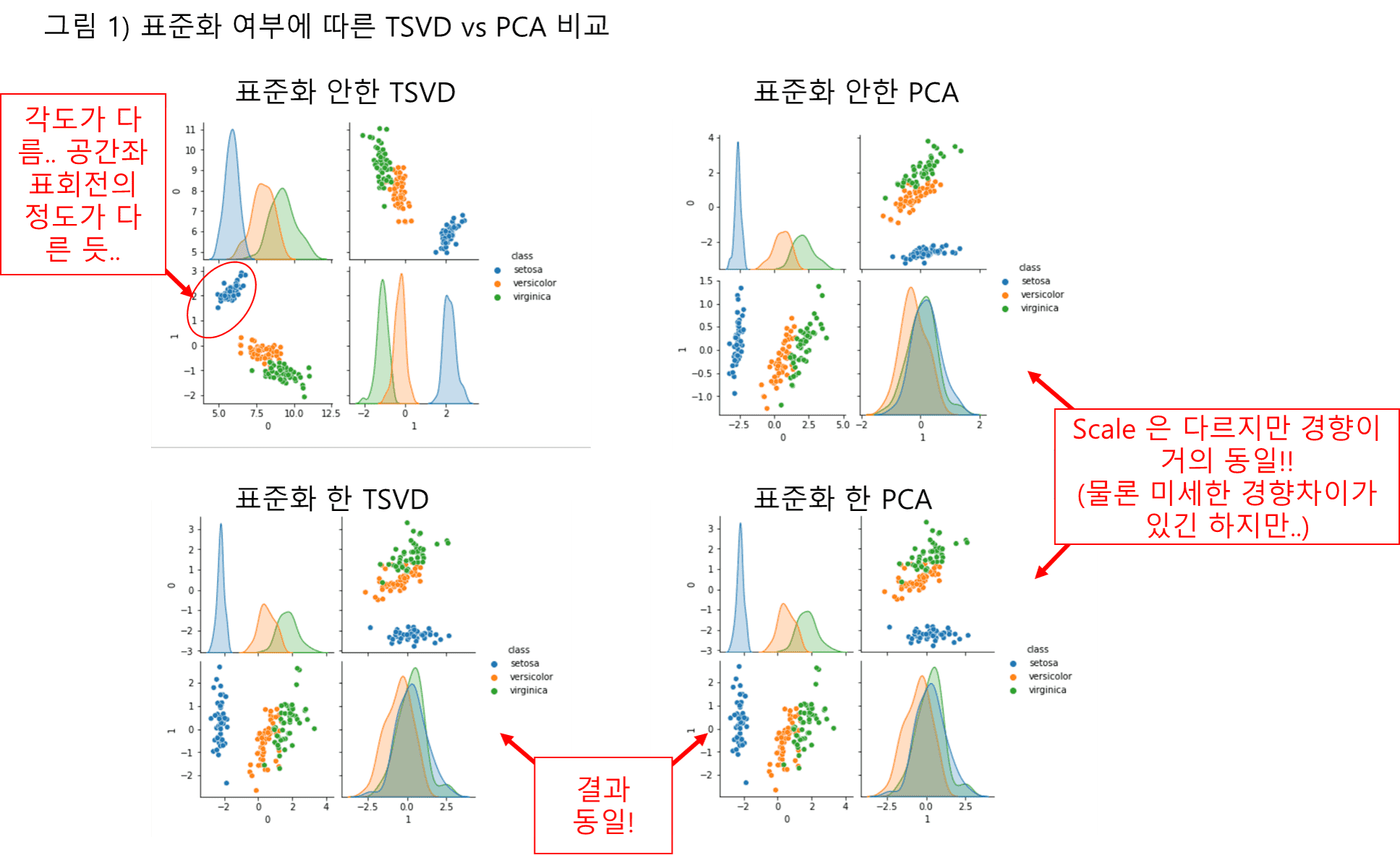
Truncated SVD 의 경우 데이터 표준화를 한 경우는 표준화한 PCA 와 동일해 진다는 부분은 잘 이해하였습니다. 다만 이것저것 돌려 보니, 표준화를 하지 않은 Truncated SVD 는 표준화 한 경우에 비해 데이터 경향도 좀 바뀌는 듯 한데요, 그럼 다양한 feature engineering 방법론 관점에서 아래 3가지 다른 approach 가 가능하다고 정리하면 될지요?
1) 표준화를 하지 않은 Truncated SVD
2) 표준화를 한 Truncated SVD = 표준화를 한 PCA (동일결과)
3) 표준화를 하지 않은 PCA
3)번의 경우도 사실 2)번과 경향은 동일하고 scaling 만 바뀌는 case 이긴 하지만, 원본 변수의 scaling 에 따른 가중치 효과가 있을 것이므로 예측 모델의 성능에도 영향이 있을 듯 하고.... 1) 번은 아래 그래프처럼 경향자체가 많이 달라져서 역시 모델 성능 차이를 줄 수 있을 듯 해서 입니다 (경우에 따라 모델 성능개선을 기대해 볼 수 도 있는)
질문 2) NMF 의 개념 및 componet 개수 가이드라인
NMF 역시 결국은 다변량 변수로 정의되는 초공간에서의 좌표 축을 회전시켜서 새로운 측면의 변수를 뽑아내는 개념이 아닐까... 라고 이해를 해 보았는데요, 인자분석 (Factor Analysis) 과 유사한 개념이라고 이해하면 될지.. 질문 드립니다.
Factor Analys 에서도 차원을 줄이되 합성 feature 를 추출해서 포괄적인 상위개념의 변수를 정의해서 모델링을 하거나, 데이터를 해석하는 개념으로 이해하고 있어서... NMF 도 이와 유사한 개념이 아닐까 (물론 계산 과정이나 결과물 자체는 다르겠지만) 생각이 들어서요~
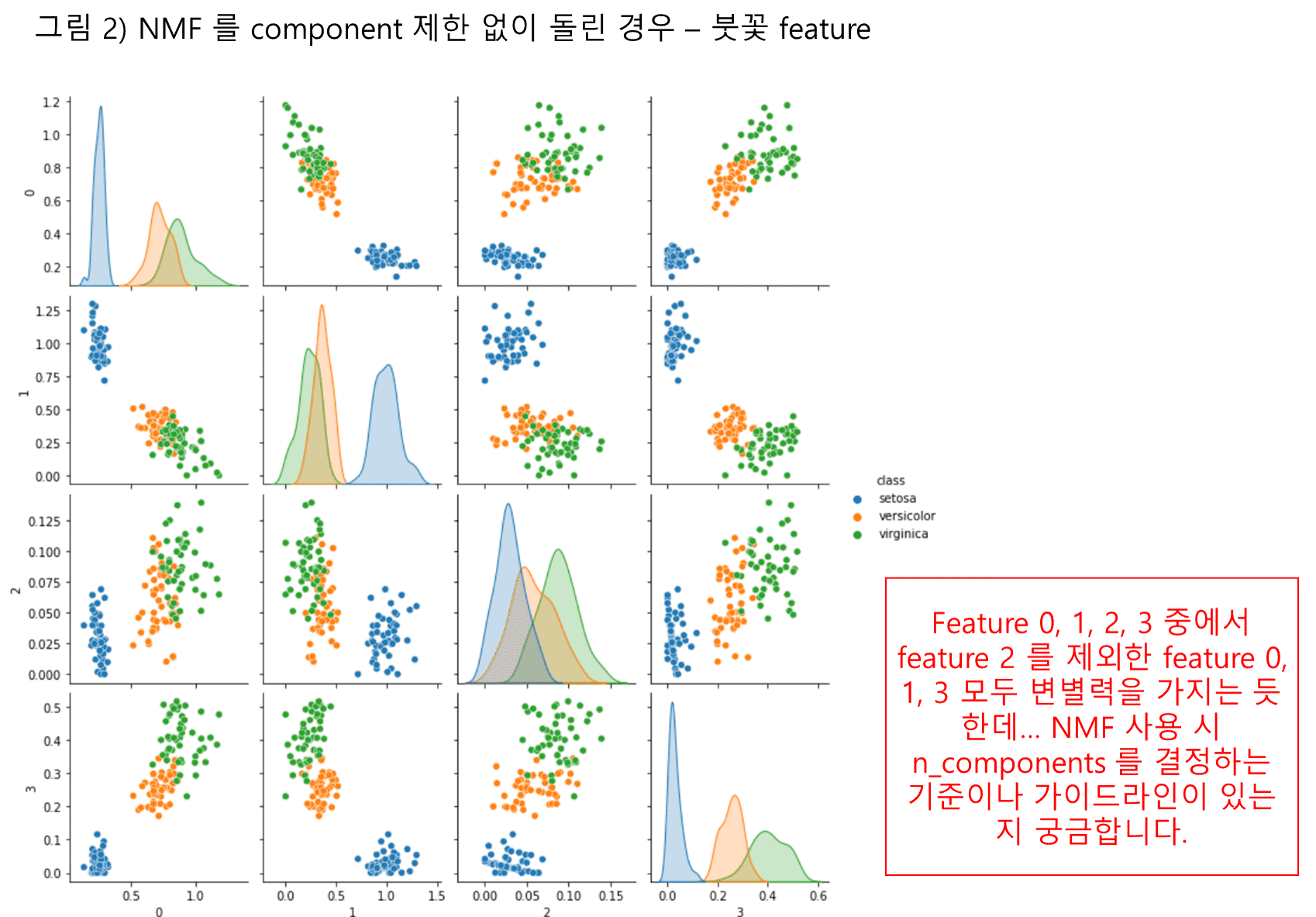
다만 본 단원 실습인 붓꽃의 4개 feature 자료에 대해서 component 개수를 제약두지 않고 NMF 를 돌렸을 때는 4개의 신규 feature 가 나오던데요, 아마도 원본 데이터의 차원 수만큼 new feature 가 나오는 것으로 이해가 됩니다.
PCA 나 인자분석 (FA) 에서는 주성분분산 크기를 가지고 extract 된 feature 의 개수를 가늠하는데, NMF 의 경우 feature 개수를 가늠하는 가이드라인이 있을지.. (예제에서는 두 개로 하셨는데, 그 이유에 대한 설명이 있지는 않아서요~) FA 는 PCA 와 달리 new feature 간 중요도 차이 없이 모두 평등한데, NMF 도 extract 된 new feature 별 중요도가 있을지 혹은 FA 와 같이 모든 변수의 중요도가 동일한지... 도 궁금합니다.

답변을 작성해보세요.
1

권 철민
지식공유자2021.07.30
안녕하십니까,
1. 음, 표준화가 되지 않는 PCA를 Feature Engineering에 추가해볼 생각은 해본적이 별로 없었습니다. 동일한 스케일링이 적용되지 않는 데이터 세트에 PCA를 적용하면 최적 차원 축소가 안되기 때문입니다. 그래서 Feature Engineering도 표준화 적용만 고려하시는 게 좋을 것 같습니다.
그리고 차원 축소로 지도학습의 feature engineering 효과를 크게 얻기는 어려운 부분이 있는 것 같습니다. 캐글같은 컴피티션의 경우 아주 작은 성능향상도 크게 순위에 기여하기 때문에 이 방식을 적용할 수도 있지만 일반적으로는 큰 성능향상 기대는 어렵습니다.
2. NMF의 최적 n_components 값은 저도 잘 모르겠습니다. NMF는 주로 숨겨진 의미, 잠재 요인(Latent Factor)를 찾아내는데 사용됩니다. 가령 토픽 모델링에서 토픽의 갯수등을 n_components로 설정합니다. 그런데 숨겨진 의미가 몇개가 최적이라는 것을 측정하는 메커니즘이라는게 아직까지 없습니다. 물론 기존의 토픽으로 잘 분류된 데이터 세트가 있고, 이걸 토픽이 몇개인지 알려주지 않은 채로 NMF에서 Topic Modeling의 n_components를 바꿔가면서 최적 n_components가 몇개가 가장 좋은지 알 수 있지만, 이 방법외에 데이터의 숨겨진 의미, 몇개가 가장 최적인지를 나타내는 지표는 저도 잘 모르겠습니다
감사합니다.
0


답변 2