
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
미해결
산탄데르 데이터의 precision과 recall
21.07.16 13:19 작성 조회수 109
0
안녕하세요 강사님
산탄데르 데이터와 신용카드 데이터를 실습해보며 질문이 생겼습니다
신용카드 데이터는 precision과 recall이 나쁘지 않게 나오는데 산탄데르 데이터에 대한 precision과 recall은 아래의 결과와 같이 굉장히 안좋습니다
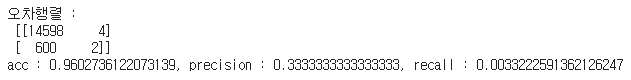
원인이 무엇인가요??
개선할 수 있는 방법이 있나요?

답변을 작성해보세요.
0

권 철민
지식공유자2021.07.16
안녕하십니까,
일단 해당 실습 모델은 최적화된 모델이 아닙니다. 그리고 GridSearchCV도 ROC-AUC를 기준으로 수립된것입니다(이 역시 많은 하이퍼 파라미터 튜닝을 한것이 아닙니다)
고객 불만이 데이터가 전체의 4% 정도로 낮은데, 이 낮은 개수의 고객 불만데이터의 Positive 값 예측이 잘 안되서 그렇습니다.
Precision은 조금 튜닝하면 더 나아집니다. 그런데 Recall이 낮습니다.
precision은 tp/(fp + tp) 인데, confusion matrix를 보시면 tp가 2, fp가 4여서 0.33이 나옵니다.
보시면 fn이 600이나 됩니다. recall은 tp/(fn+tp) 그래서 2/602 가 나오게 됩니다. 여기서 fn을 줄여서 tp로 어떻게든 유도해야 하는데, 이럴려면 좀 더 다양한 성능 기법을 적용해 보아야 합니다.
해당 실습은 성능 튜닝을 목표로 한것 보다는 xgboost, lightgbm의 사용에 익숙해지기 위한 실습 코드입니다.
recall을 높이려면 모델 튜닝을 저도 수행해 봐야 합니다. 해당 건은 Q&A로는 답변 드리기가 어려 울 것 같습니다. 나중에 개정판 계획할 때 Recall 모델 튜닝도 같이 해보도록 하겠습니다.
감사합니다.


답변 1