
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
미해결
여러 샘플마다의 데이터 편차를 수학적으로 정규화할 수 있나요?
21.06.14 18:54 작성 조회수 212
0
안녕하세요. 이물 검사를 하고 있는데, 클래스가 3가지 정도가 있습니다
훈련하고, 모델을 가지고 추론했을 때 score_map이라는 것을 출력으로 갖게 됩니다. 그런데 클래스에 따라서 출력되는 score_map의 범위가 다르게 됩니다. 일단은 score_map의 출력 과정을 수정하기 보다는 후처리를 잘 해보려고 하는데 문제는 score_map을 찍어보면 위에서 말씀드릴 것처럼 출력 범위가 7, 18 등 범위가 클래스마다 다르게 됩니다
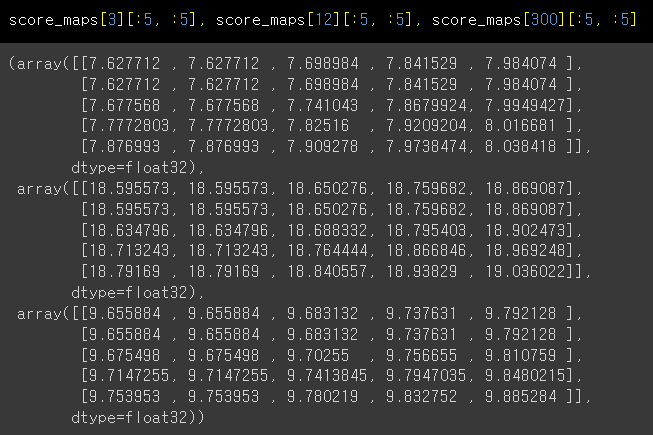
물론 이를 각 score_map 행마다 표준화를 시킨 다음에 roc_auc로 threshold를 구한 후 마스킹을 하는데, 현재 마스크 threshold는 4가 됩니다
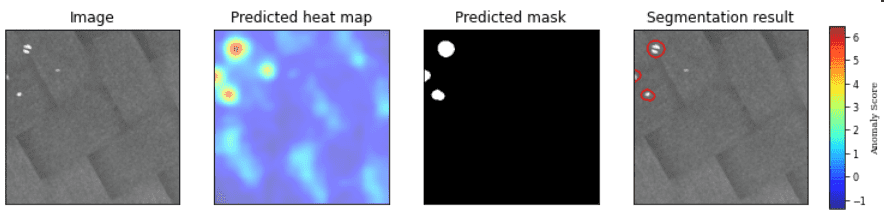
그런데 클래스 마다 표준편차가 차이나다보니까 표준화를 해도 (평균, 분산은 각각 0과 1) 2번째 히트맵에 그려진 에러는 잡지 못하더라구요. 최대 픽셀값이 4정도 됩니다
그래서 곰곰이 생각해보니 결국엔 각 클래스마다 편차가 다르다보니 threshold에 문제가 생겨가지고요. 혹시 편차를 정규화 시킬 수 있나요?

답변을 작성해보세요.
0

권 철민
지식공유자2021.06.14
음, 일단 질문을 잘 이해 못했습니다.
지금 score map이 mask rcnn등으로 예측된 masking 값으로 출력 된건가요?
암튼 질문의도는 정확히 파악하지 못했지만, z 표준화 변환 적용을 해보신건가요?
(각 클래스별 개별 원소들 - 클래스별 평균 값)/ 클래스별 표준 편차
가급적 컴퓨터 비전쪽 질문은 해당 강의에 적어주셨으면 해당 강의를 참조하는 수강생 분들에 더 도움이 될 듯합니다.

답변 1