
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
미해결
실루엣 스코어
21.05.18 21:50 작성 조회수 383
0
 안녕하세요 교수님 항상 좋은 수업 감사드립니다 :)
안녕하세요 교수님 항상 좋은 수업 감사드립니다 :)
다름이 아니라 실루엣 스코어 시각화 코드를 포탈에 검색해서 보는 중에 이렇게 표현하는 코드가 있길래 해봤는데 이러한 방법은 교수님께서 하신거랑 차이가 큰가요? 단순하게 최적화된 n_clusters만 알 수 있고 라벨들의 군집(?)을 모른다는것 인가요,,,
마지막으로 이렇게 이상치가 많은 데이터에서 roboust scaler을 안쓰시는 이유가 있으신가요?
오늘도 제가 이상한 질문을 하는군요 :(

답변을 작성해보세요.
0

권 철민
지식공유자2021.05.20
강의에서도 말씀 드렸듯이 기계적으로 실루엣 스코어만 높아졌다고, 좋은 클러스터링이 되는것이 아닙니다. 적어 주셨듯이, log함수를 적용하지 않은 경우는 점수는 높게 나왔지만, 제대로 클러스터링 되었다고 보기 힘듭니다.
0

Jaewoo Choi
질문자2021.05.20
###########################log 적용 전 RobustScaler ()###########################

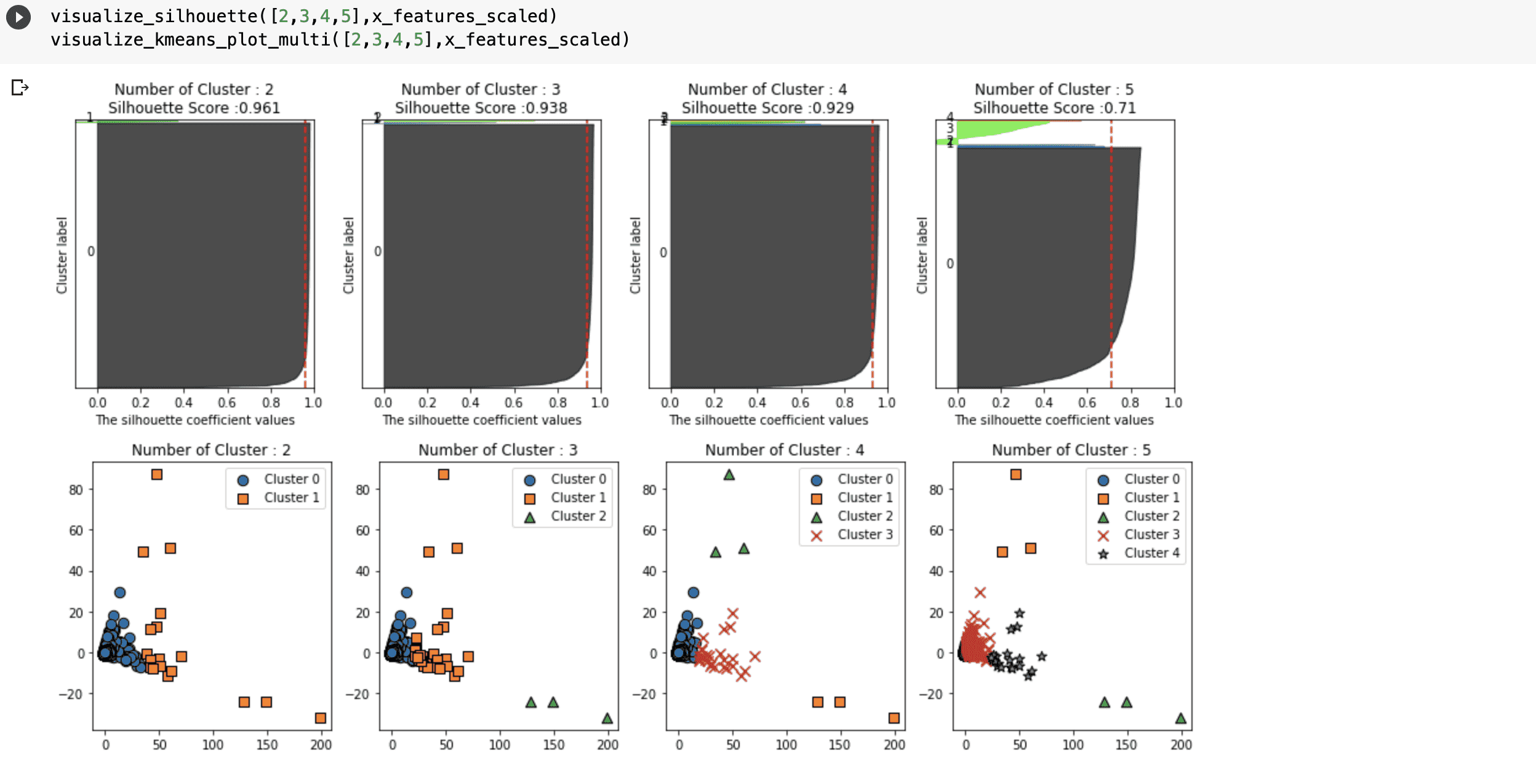
##################log 적용 후 RobustScaler ()###########################

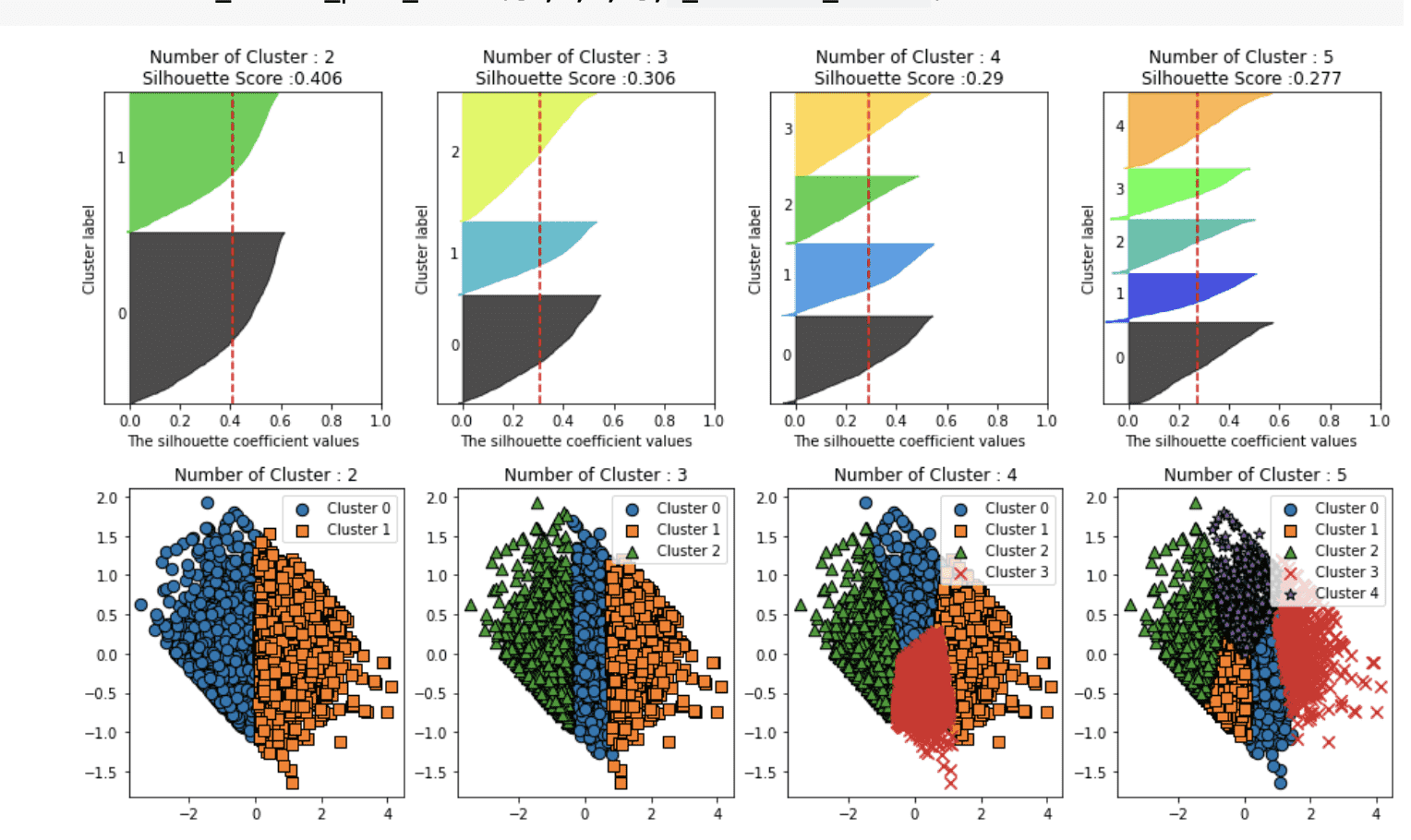
########################################################################### #############################질문###############################
log함수를 적용하기전에 실루엣 스코어가 이전의 StandardScaler (실루엣 스코어 : 0.592) 에 비해 급격하게 올라갔습니다. 대부분이 0 라벨링을 가지고 있는데 이는 과적합(?)이라고 해석할 수 있나요?? 그저 점수만 높게 나온 퀄리티가 낮은 점수로 해석해도 되는 건가요?
0
권 철민
지식공유자2021.05.19
안녕하십니까,
이상한 질문이 전혀 아닙니다만,,,
일단 코드는 제 코드와 비슷합니다. Kmeans 클러스터링의 클러스터 개수를 2에서 부터 10까지 변경하면서 실루엣 스코어를 구한 것입니다. 잘 아시겠지만, 그림에서 보면 클러스터 5개로 최적화 되면 좋은것 같습니다. 최적 클러스터 개수를 실루엣 스코어로 찾는 것만 코드화 되어 있습니다.
그리고 robust scaler는 저도 지금 검색해 보고 알았습니다. 좋은 기능인 것 같습니다. 한번 적용해 보시고, 기존 대비 어떤 차이가 있는지 여기에도 업데이트 해주시면 좋을 것 같습니다.
감사합니다.

답변 3