
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
미해결
split 옵션 문의.
21.04.29 21:14 작성 조회수 173
1
안녕하세요 강사님.
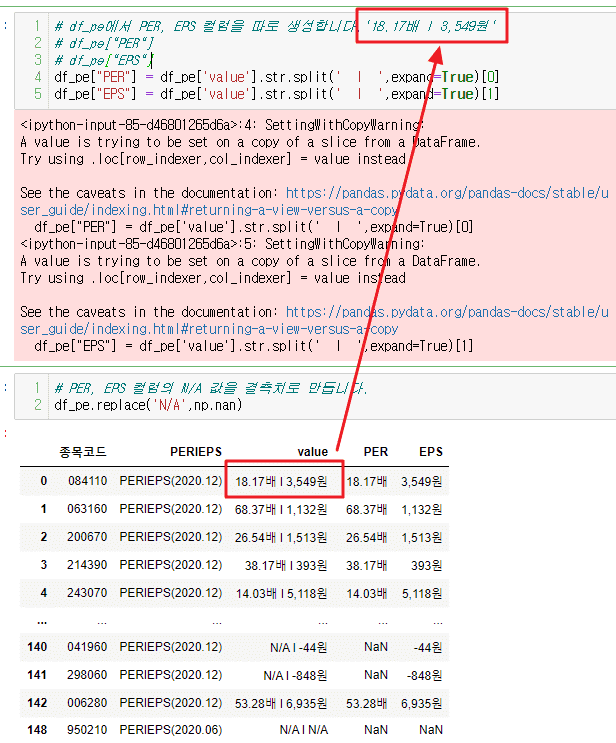
원본데이터에는 공백이 하나인데, split 할때 공백울 2개씩 넣어줘야하는 이유가 있나요?
원본 데이터 '18.17배 l 3,549원'
df_pe["PER"] = df_pe['value'].str.split(' l ',expand=True)[0]제가 복사해서 텍스트 에디터에서 확인하면 공백이 하나입니다. 혹시 복사해서 보면 다르게 보이는건가요?
여기서 공백을 하나만 넣어도 분리는 되지만 다음 결측치 제거에서 공백때문에 공백처리를 한번더 해야합니다.

답변을 작성해보세요.
1

MIKE.aeon
질문자2021.04.29
빠른 답변 감사합니다.
원인을 찾았습니다. 원인이라기 보다는 현상이라고 생각됩니다. 시리얼로 출력하는것과 dataFrame 으로 출력하면 결과가 다릅니다.
다른 분들도 아시면 좋을거 같아서 공유합니다.
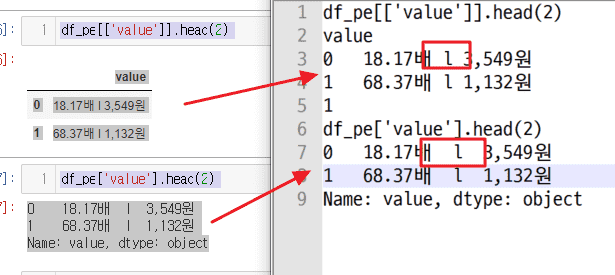
하나는 데이터프레임으로 출력하고 하나는 시리얼 로 출력해 보았습니다. 주피터 내용을 복사해서 텍스트 에디터에 붙여보니 공백이 차이납니다. 데이터 프레임은 공백이 1개로, 시리얼은 공백이 2개로 보여집니다. 그래서 원본 csv 파일을 열어보니, 원본 파일에는 공백이 2개 있는게 맞습니다.
제 환경의 문제일수도 있습니다만, 주피터에서 그렇게 보여주는거 같습니다.

박조은
지식공유자2021.04.29
안녕하세요. 공백 문자가 눈에 잘 보이지 않아 혼란이 될것 같아요.
데이터를 전처리 하다보면 이렇게 잘 보이지 않는 공백 문자 때문에 고생을 할 때가 종종 있는데요.
시리즈 형태이든 데이터프레임이든 내부의 공백이 변경되지는 않아요.
정확하게 확인해 보기 위해 "배" 라는 문자 기준으로 문자열을 잘라서 아래와 같이 확인해 보면 공백문자가 2개 들어 있습니다.

문자열을 가져와서 인덱싱 하는 방법으로 공백문자가 있는지를 알아봤습니다.
1
박조은
지식공유자2021.04.29
안녕하세요.
원본에 공백이 하나라면 공백을 하나만 넣어도 되지만 두 개라면 나중에 다시 공백을 제거해야 하는 수고가 있기 때문에 두 개를 넣어준다면 제거 되지 않은 공백을 다시 제거하지 않아도 되기 때문에 텍스트의 공백을 그대로 복사해서 사용했어요.
질문해 주신대로 공백을 하나만 사용하고 나중에 str.strip() 등으로 제거되지 않은 공백을 제거해도 됩니다.
공백문자는 눈으로 잘 보이지 않기 때문에 복사해서 그대로 사용하는걸 추천해요.

답변 2