
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
GPU, test dataset 질문
22.10.11 10:49 작성 조회수 191
0
코드 실행 후 두가지 여쭤보고 싶은 것이 있어 질문 드려봅니다.
1.먼저 train, validation 데이터셋으로 학습을 시켜보았습니다.
혹시 test dataset은 train, validation 데이터 이외의 학습시키지 않은 데이터로 결과를 확인하면 되나요? test dataset는 말그대로 test의 의미를 가지는 데이터셋 일까요?(loss나 accuracy를 구해볼 수 있을까요?)
2.현재 CPU는 Intel core i9, GPU는 RTX 2080 Ti를 사용중에 있고, 하나의 이미지에서 모델 검출속도가 약 0.08s 나오고 있습니다.
Window에서 사용중에 있고,그래픽카드 4개를 사용하려고 했지만, 멀티 gpu를 사용하게 되면 sh 파일을 사용해야되는 것으로 알고있고,window에서 sh 파일이 실행되지 않는 것을 확인했습니다.
0.05s 이하로 검출시간을 줄이는 것이 목적이고, 그래픽카드 성능을 보면 RTX 3090이 약 2배정도 뛰어난 성능을 나타낸다고 나와있는데 그래픽카드를 바꾸면 속도가 목표 속도까지 향상이 될까요?
혹은 sh 파일을 window에서 실행시켜서 멀티 gpu를 사용할 수 있을까요?
감사합니다.

답변을 작성해보세요.
0

권 철민
지식공유자2022.10.11
안녕하십니까,
네, 말씀하신 대로, test dataset은 train, validation 데이터 이외의 학습시키지 않은 데이터로 결과를 확인하면 되며, test dataset는 말그대로 test의 의미를 가지는 데이터셋 입니다.
그리고 지금 어디 강의를 듣고 계신지 Q&A에 나오지 않아서 모르겠지만, 나중에 bccd 데이터 학습과 예측하는 실습에서 test dataset의 evaluate() 를 통해 test dataset의 성능 평가 결과를 확인할 수 있습니다.
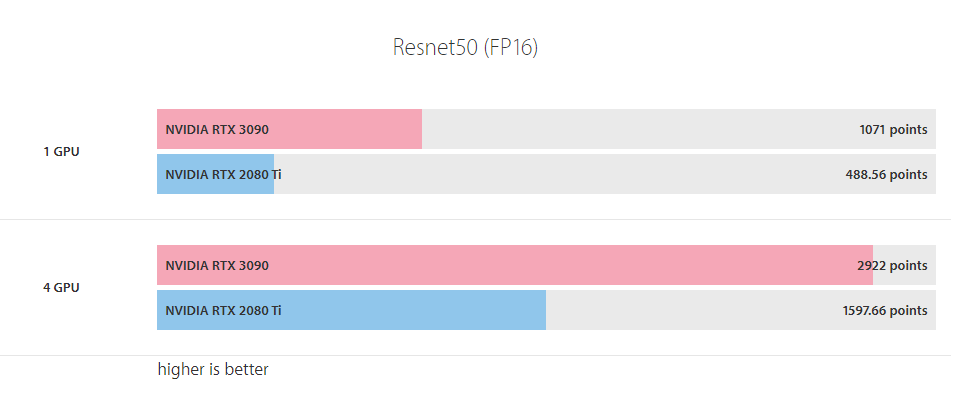
제가 GPU 모델에 따른 성능은 잘 모릅니다. 그리고 올려주신 성능 지표가 학습시 성능 지표인지 Inference시 성능 지표인지 알수가 없어서 검색을 좀 해봤습니다.
아래 URL 결과를 보면 3090 모델이 inference가 벤치마크 결과가 2배정도 빠른 걸로 나오는 군요. 해당 GPU로 변경하시면 속도가 2배까지는 아니더라도 잘하면 원하시는 0.05 sec 정도는 될 것 같습니다. (벤치마크 결과가 2배 빠르다고 inference 속도가 2배까지 빠르지 않을 수 있습니다. 해당 URL을 좀 더 자세히 읽어봐야 겠지만 벤치마크 Point가 반드시 inference 속도와 정비례하지 않을 수 있습니다)
https://www.servethehome.com/zotac-geforce-rtx-3090-trinity-24gb-review-nvidia/7/
제가 mmdetection에서 multi gpu를 돌려 보지 않았습니다. 더구나 mmdection은 windows가 잘 지원되지 않습니다. sh파일은 .bat 파일로 직접 수정해서 windows에서 돌려 보실 수도 있을 것 같습니다만, 방법이 쉽지는 않을 것 같습니다(저도 해보지 않았습니다. 아래 dist_test.sh의 $환경 파라미터를 다 windows에 맞게 수정해 주셔야 하는데, 수정해도 수행이 된다는 보장은 없을 것 같습니다 ^^;; )
https://github.com/open-mmlab/mmdetection/blob/master/tools/dist_test.sh
CONFIG=$1CHECKPOINT=$2GPUS=$3NNODES=${NNODES:-1}NODE_RANK=${NODE_RANK:-0}PORT=${PORT:-29500}MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"} PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \python -m torch.distributed.launch \ --nnodes=$NNODES \ --node_rank=$NODE_RANK \ --master_addr=$MASTER_ADDR \ --nproc_per_node=$GPUS \ --master_port=$PORT \ $(dirname "$0")/test.py \ $CONFIG \ $CHECKPOINT \ --launcher pytorch \ ${@:4}
감사합니다.



답변 1