
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
해결됨
lmplot 연도 표시 문제
20.07.16 08:59 작성 조회수 325
1
안녕하세요? lmplot에서 아래와 같이 연도가 강의에서 보다 여러 개의 나뉘어 나옵니다. 이 문제를 해결했으면 합니다. 감사합니다.
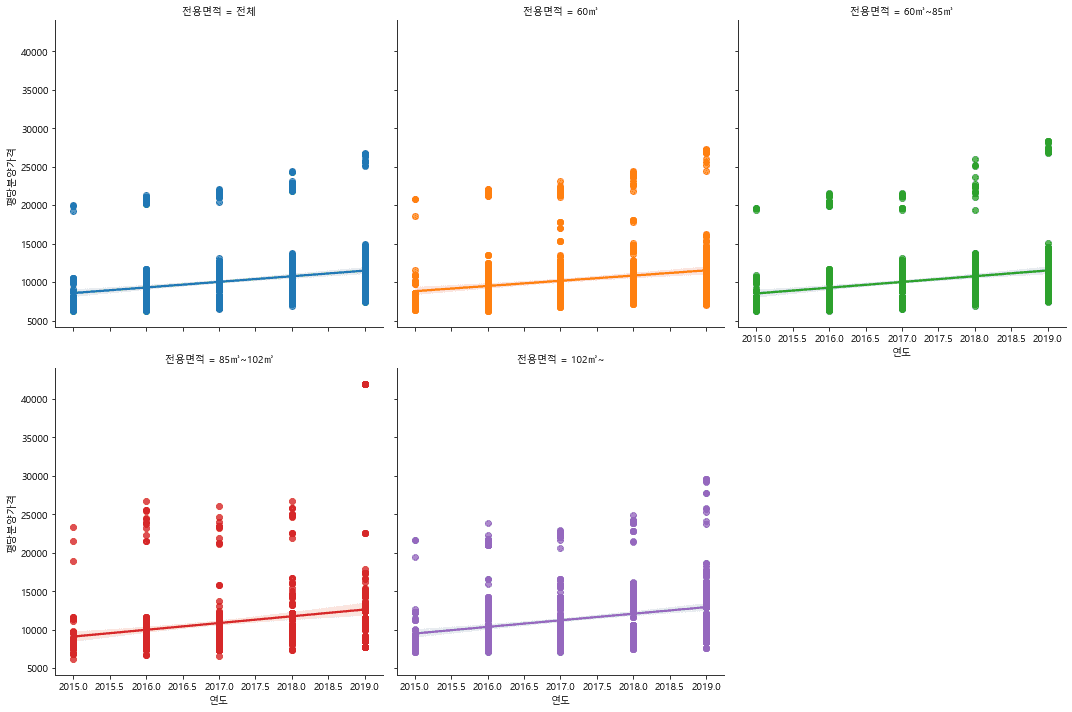

공공데이터로 파이썬 데이터 분석 시작하기
[13/20] scatterplot, regplot, lmplot, swarmplot 의 차이를 분양가 데이터 시각화로 이해하기
강의실 바로가기
답변을 작성해보세요.
1
1

Neo
질문자2020.07.16
답변 감사합니다. 그런데 아직 해결이 되지 않아 다시 질문 합니다. 아래 info결과에 의하면 연도는 int64입니다. 학습을 위한 소스코드에도 lmplot 결과가 같습니다. 이 문제를 해결할 수 있는 코드를 주시면 좋겠습니다. 감사합니다.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 4335 entries, 0 to 4334 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 지역명 4335 non-null object 1 연도 4335 non-null int64 2 월 4335 non-null int64 3 분양가격 3957 non-null float64 4 평당분양가격 3957 non-null float64 5 전용면적 4335 non-null object dtypes: float64(2), int64(2), object(2) memory usage: 203.3+ KB
0
0

박조은
지식공유자2020.07.16
안녕하세요.
영상을 제작했던 버전과 다른 버전의 seaborn 을 설치해서 사용해 봤는데요.
이전과 다르게 올려주신 것처럼 int 형식임에도 소숫점으로 연도가 표기되는것을 확인할 수 있었어요.
버전이 변경되면서 내부 옵션이 변경된 것 같은데요.
lmplot 의 내부는 scatterplot, regplot 으로 되어 있어요.
scatterplot 은 수치vs수치데이터를 표현하는 것을 기본으로 하고요. regplot은 수치vs수치 데이터에 대한 회귀선을 그려줍니다.
lmplot은 regplot의 서브플롯을 그려주는 역할을 하게 됩니다.
그래서 lmplot을 그릴 때 기본 가정은 x, y축이 모두 수치데이터입니다.
하지만 여기에서 "연도"는 숫자로 되어 있지만 "범주형(카테고리)" 형태에 가깝습니다.
그래서 이렇게 범주형 데이터의 scatterplot을 그릴 때는 해당 실습 아래에 있는 swarmplot을 사용합니다.
여기에서 x 축 값에 소숫점이 들어가는 이유는 버전이 변경되면서 x축에 표기되는 값이 변경되었는데요.
소스코드 내부를 보면 x_bins 와 x_estimator 라는 옵션이 있습니다.
x_estimator 옵션을 보면 np.mean으로 label 값을 표현할 때 평균값을 구해서 표현을 하게 되어 있어요.
그런데 평균을 구하다보면 소숫점이 발생하기 때문에 x축에 소숫점이 표현이 된 것이고요.
여기에서 소숫점을 제외하고 그리고자 한다면 가장 간단한 방법은 x_jitter 옵션을 사용하시는 겁니다.
lmplot을 그리게 되면 x 축 값이 같기 때문에 하나의 point 에 여러 점이 찍히게 되는데 그러면 여기에 중복이 되어 점이 찍히기 때문에 점의 갯수가 많은지 적은지 확인이 어렵습니다. 그래서 이걸 조금 흩어지게 그리면 빈도수를 함께 표현할 수 있는게 x_jitter 입니다.
해당 값을 조정해 보시면 몰려있는 값을 흩어지게 표현해서 빈도수를 좀 더 자세히 표현해 보실 수 있습니다.

0
박조은
지식공유자2020.07.16
안녕하세요.
강의에서 보면 연도가 int 형식으로 나오는데 올려주신 스크린샷은 float 형식으로 나오고 있어요.
해당 내용에 대한 질문이 맞다면 연도의 데이터 타입을 변경해 주시면 아래와 같은 형태로 보실 수 있어요.
df_last["연도"].astype(int) <= 이렇게 연도를 변경하실 수 있는데 int가 float 형태로 보여질 때는 보통 결측치가 있는 경우가 많아요.
결측치는 np.nan 으로 type(np.nan) 을 출력해 보면 float 으로 타입이 나옵니다.
그래서 다른 데이터에서 실습을 하실 때도 소숫점이 없어서 int 타입으로 변경하고자 하는데 변경이 안 된다면 결측치가 섰여있을 수 있어요.
결측치가 없다면 위와 같이 df_last["연도"].astype(int) 로 타입 변경시에 소숫점이 없게 표기가 됩니다.


답변 5