
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
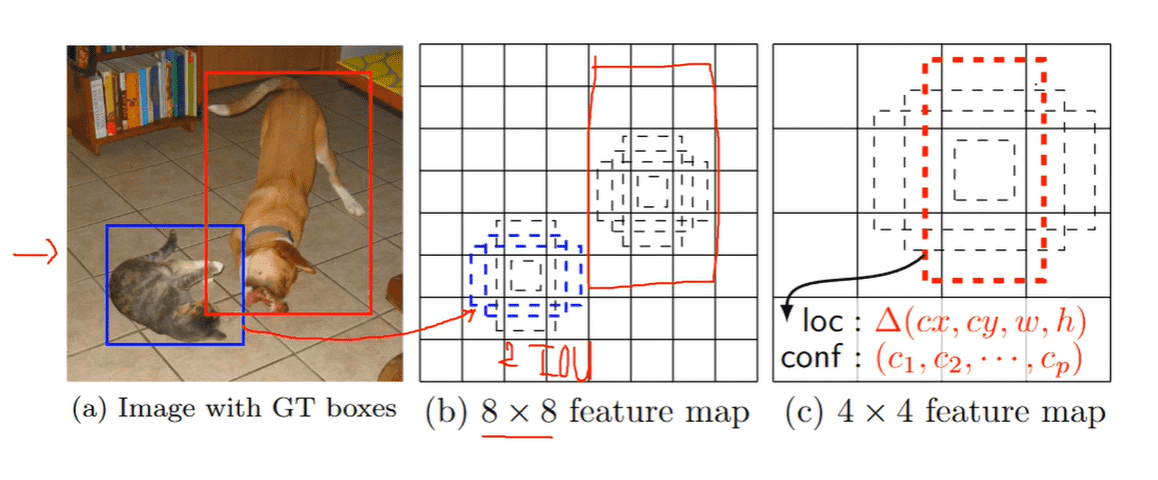
SSD의 이해02 에서 Multi Scale Feature Map의 detection에 대한 질문
21.07.25 17:25 작성 조회수 648
0

답변을 작성해보세요.
0

권 철민
지식공유자2021.07.26
안녕하십니까,
말씀하신 부분이 일견 논리가 있으십니다.
한가지 말씀 드리고 싶은 것은 아래 부분에서 적어주신 '4x4 feature map은 더욱 세밀한 특징을 추출한것이 아니라 보다 추상적이고, 핵심적인 feature를 추출한 것입니다.
왜냐하면 제가 이해하기로 4x4의 feature map은 8x8 feature map보다 더욱 두터운 channel를 가지면서 이미지의 더욱 세밀한 특징들을 추출해낸 feature map이라고 생각하기 때문입니다.
그러니까 Conv 연산을 계속 적용해서 38x38 feature map -> 19x 19 -> 19x19 -> 10x10 -> 5x5 -> 3x3 으로 Conv 연산을 수행해서 최종적으로 만들어진 3X3 Feature map은 매우 추상적이고 핵심적인 feature 위주입니다. 세밀한 edge, 음영, 형태 부분은 많이 사라졌지만, 이미지를 판별하기 위한 핵심 feature를 가지고 있으며, 이미지 판별에 방해가 되는 세밀한 잡음등은 없어지고, 핵심에 집중하는 feature map을 만듭니다.
그런데 3x3 정도로 작은 feature map에 object를 Detection하려면 문제가 생깁니다. 작은 object 들이 아예 feature map에서 특징이 사라지거나, 해당 feature map에 특징이 있더라도, 전체 이미지 대비 object 크기가 작기 때문에 anchor box와 해당 object의 ground truth box가 IOU가 작아서 Detection시에 무시가 되기 쉽습니다.
그래서 object detection은 일반적으로 이미지 크기를 키우거나 최종 feature map 크기를 너무 작게 가져가지 않습니다. 그런데 SSD 는 서로 다른 Feature map에서 서로 다른 scale로 object를 Detection합니다. 가령 19x19에는 작은 object라고 하더라도 상대적으로 3X3 에 비해서는 해당 object와 Ground truth가 겹칠 영역이 크기 때문에 보다 잘 Detect가 될 수 있습니다.
물론 이렇게 상대적으로 큰 feature map을 기반으로 할때도 문제가 있습니다(어떻게 보면 SSD의 치명타이기도 합니다만). Conv 채널 연산이 비교적 덜 적용된 초반의 대형 feature map은 작은 object들은 상대적으로 잘 도출하더라도 많은 conv 채널 연산이 적용된 작은 feature map에 비해서 핵심적인 feature들을 제대로 도출하지 못하기 때문에 예측 성능이 떨어집니다.
나중에 Yolo, Retinanet 설명드릴때 다시 말씀 드릴테지만, 그래서 FPN(Feature Pyramid Network)이 만들어 집니다. FPN은 SSD와 많이 유사하지만, 상위 feature map의 값을 하위 feature map으로 전달하여 하위 feature map의 예측 정확도를 키우게 됩니다.
감사합니다.

답변 1