
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
미해결
랜덤포레스트 배깅방식으로 데이터 샘플링 예제에서
21.02.24 12:06 작성 조회수 247
0
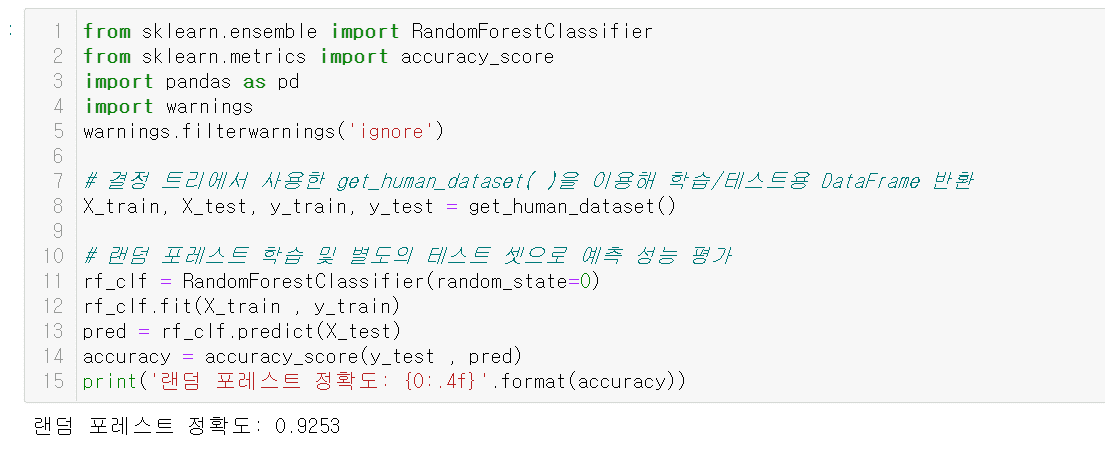
선생님~
랜덤포레스트에서 배깅방식으로 데이터샘플링을 하는 부분을 확인할 수 없어서 질문합니다.
궁금한 점이 X_train 데이터는 총 7352개 행이 있는데(shape(7352, 561))
랜덤포레스트의 n_esitmator의 기본값이 100이므로,
7326개의 데이터를 랜덤하게 샘플링을 하여
각각 다른 샘플링 데이터(중첩되기도하는) 들을 100개의 분류기에 학습을 시킬텐데..
100개 분류기마다 들어가는 각 샘플링 데이터의 수가 가변적이겠지만
대략 평균적으로 몇 개정도 들어가는지는 알 수 없는건가요~?
각 분류기에 들어가는 데이터 수를 지정하는 파라미터로 max_samples라고 알고 있는데,
이게 None으로 기본값이 되어있을 때는 어떻게 랜덤샘플링 데이터 수가 지정이 되는지 궁금합니다.

답변을 작성해보세요.
0

권 철민
지식공유자2021.02.24
max_samples가 None이면 7326개를 모두 사용합니다.
아래 사이킷런 URL 참조 하시면 max_samples가 0일때 값을 알수 있습니다.
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
감사합니다.

freedom07
질문자2021.02.24
그러면 선생님~ max_samples를 지정 안해주면(기본값으로 가면)
여러 개의 학습기들이 원데이터를 쓰는 것에서는 보팅방식과 다른 점이 없는 건가요...?

답변 1