
-
질문 & 답변
카테고리
-
세부 분야
데이터베이스
-
해결 여부
미해결
집계함수(문자열) 사용 시, 행의 데이터 불일치 하는 이유
22.11.11 11:41 작성 조회수 195
0
안녕하세요,강사님
집계함수와 count(distinct) 실습 강의 듣다가 궁금한점이 있어 문의드립니다.
하기 코드를 실행시킨 후, 나오는 값을 보면 하기 이미지와 같습니다.
select deptno, max(job), min(ename), max(hiredate), min(hiredate)
from hr.emp
group by deptno;
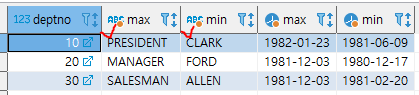
deptno가 10인 부서에서
job은 MAX 집계라 알파벳 순서가 가장 늦은 'PRESIDENT'가 나오는데, ename은 MIN이라서 deptono = 10인 부서에서 ename으로 가장 앞 순서인 'CLARK'가 나오더라고요.
근데 하기 데이터를 보면, job은 president인 사람의 이름은 KING인데...
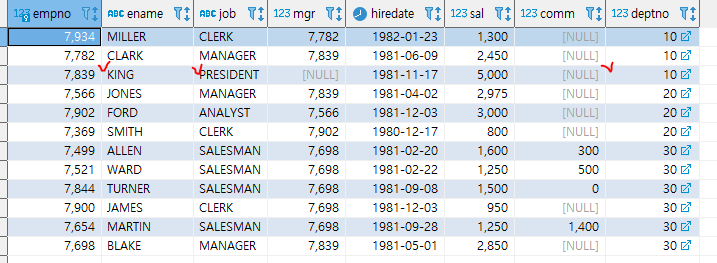
이렇게 문자열에 집계함수를 사용하여 조회한 데이터는 행 정보가 일치하지 않는건가요? 즉, 직업정보,이름 정보는 서로 다 일치하지 않고, 개별 컬럼으로 계산되는 건지? 그 이유가 무엇인지 알고 싶습니다.

답변을 작성해보세요.
1

권 철민
지식공유자2022.11.11
안녕하십니까,
의심하신대로 GROUP BY에 aggregation 함수를 적용하게 되면 Group by 컬럼값 레벨로 aggregation 함수의 개별 컬럼별로 계산이 됩니다. 문자열 이라서가 아니라 Group by의 기본 메커니즘이 그렇습니다.
아래 SQL에서 보면 deptno값 별로, 예를 들어 10이라면, max(job)은 deptno=10에서 job 문자열이 가장 큰 값, min(ename)은 deptno=10에서 ename 문자열이 가장 작은 값을 반환하게 됩니다.
select deptno, max(job), min(ename), max(hiredate), min(hiredate)
from hr.emp
group by deptno;
반면에 위 SQL은 max(job)이 King 일 때의 ename은 반환하지 않습니다. 만약 해당 결과를 원하신다면 이후 강의인 analytic SQL이나 서브쿼리 강의를 들어보시면 쉽게 구하실 수 있을 것입니다.
감사합니다.

답변 1