
-
질문 & 답변
카테고리
-
세부 분야
프로그래밍 언어
-
해결 여부
해결됨
안녕하세요 질문드립니다!
20.07.24 20:15 작성 조회수 208
1
2020년 1월부로 변경된 구조의 HTML 에 대해 질문드립니다.
왜 변수 writer 는 "td.num.a.author".text 의 형태처럼 a태그가 바로 파싱이되고, 변수 title 은 a태그가 위의 형태처럼 바로 파싱이 되지 않고 "td.title" 을 구한 후에 "a".text 를 구해야하나요? 둘다 a 태그 형식에 class 명을 가지고 있는 자료형태인데 말입니다..
그리고
# td class="title" 태그에서 a, div, br 태그 제거
# extract() 함수는 태그와 태그의 내용까지 모두 제거합니다.
의 이유는 무엇인가요?
답변을 작성해보세요.
1

남박사
지식공유자2020.07.25

1. 이렇게 하던 저렇게 하던 상관은 없는 부분입니다만 먼저 writer 정보는 그냥 작성자 정보만 추출하면 되기 때문에 말씀하신것 처럼 바로 파싱을 한 것이지만...
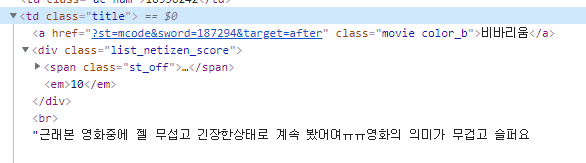
2. 의 경우에는 제목과 점수 2가지의 정보를 얻기 위해서 td > title 을 먼저 구한뒤 이 원소를 갖고 제목과 점수를 구했습니다. 물론 1에서 처럼 점수 따로 td.title > a.text 를 구하고 td.title > div.list_netizen_score > em 를 따로 구해도 됩니다만 이렇게 되면 내부적으로 td.title 까지를 2번 구하게 되는 로직이라 td.title 까지를 1번 구하고 거기서부터 다시 구하는 방식을 취했습니다. 사실 라이브러리가 td.title 까지만 구하는것도 꽤 많은 연산을 해야만 얻을 수 있는 내용입니다. 그렇기 때문에 항상 개발자는 연산량을 예산하여 코딩을 하는 습관을 들이는게 좋습니다. 별거 아닐 수 있겠지만 프로젝트의 규모가 커지게 되면 이런 작은 부분이 성능의 차이를 만들어내게 됩니다.
3. extract() 함수를 쓴 이유는 위의 이미지를 보면 제목이 포함된 td 클래스 안에는 <a>작성자</a> <span></span>등 제목외의 불필요한 정보가 많이 있고 우리가 원하는 깔끔한 제목 텍스트는 특별한 태그로 감싸있지 않기 때문에 td 안의 정보에서 모든 태그를 삭제하는 방식으로 원하는 제목 데이터를 취하는 형태를 갖게 되었습니다.
궁금하신 부분이 해결되셨는지 모르겠습니다. 더 궁금하신 사항이 있다면 언제든 질문 주시기 바랍니다.
0


답변 2