
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
미해결
지마켓 크롤링 id값 밑에 li마다 아이디 있는 경우
20.07.20 09:35 작성 조회수 321
0

현재 지마켓 크롤링 실습을 하고 있는데요 지마켓 html 값이 변경이 되어서 이런형태로 변경이 되었더라고요 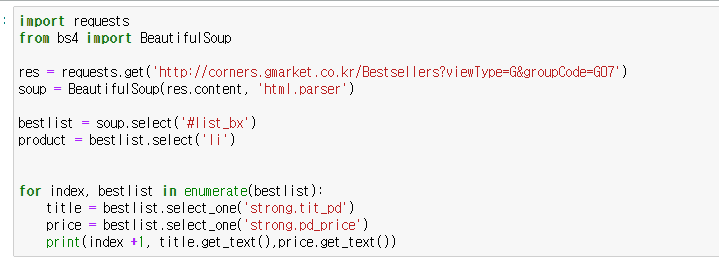
id : list_bx 라는곳에 아래에 li가 베스트 아이템 1번부터라서 이런식으로 코드를 작성했는데 에러가 계속 떠서요 ㅠ li에 아이디값이 다 있는 경우 id 밑 li는 어떻게 선택을 해야하나요??

파이썬입문과 크롤링기초 부트캠프 [파이썬, 웹, 데이터 이해 기본까지] (업데이트)
프로젝트: 크롤링 + 엑셀 보고서까지 자동으로 만들며 익히는 프로그래밍1 (업데이트)
강의실 바로가기
답변을 작성해보세요.
0

chan753
질문자2020.07.21
앗 네네 답변 달아주셔서 감사합니다 ! ㅎㅎ
최강 크롤링 기술 강의 듣고있어서요 selenium 으로 하니까 먼가 더 편하고 잘되는거 같아서 일단 해보고 나중에 다시 해보겠습니다 !
0

잔재미코딩 DaveLee
지식공유자2020.07.20
안녕하세요.
말씀하신 부분을 크롤링을 새로 해봤는데, list_bx 아이디가 찾아지지가 않아서요. 이것이 지마켓에서 ABTest를 해서 각 요청마다 다른 페이지가 보여지는 것인지는 모르겠지만, 일단 새로 제가 지마켓 해봤을 때 기존과 동일했습니다.
다음과 같이 해도 크롤링이 가능하더라고요.
보여주신 코드상에서도 bestlist를 가져와서 그 안에서 product 를 가져온 듯 한데, for 문에는 다시 bestlist 를 써서, 정상적으로 동작하기 어려운 코드로 보여요. product 로 가져왔다면, product 의 각 아이템을 꺼내서, 해당 아이템에 다시 select('li') 와 같이 하시는 것이 맞아보여요.
웹페이지가 변경되는 부분이 의심이 되는 상황으로 보인다면, 이 페이지도 자체적으로 만든 홈페이지 크롤링으로 바꾸겠지만, 이렇게 다 바꿔서 실제 웹페이지를 테스트해볼 수 없는 부분은 아쉬움으로 보여져요.
여하튼 현재 제가 해보기로는 해당 페이지는 변경되지 않았지만, 혹시 모바일 지마켓 페이지를 보셨다면 이 부분은 한번 직접 해당 주소를 웹브라우저에서 오픈해보셔도 좋을듯 하고요. 계속 저런 페이지가 나온다면 웹브라우저 화면을 캡쳐해서 주소와 함께 보여주실래요?
감사합니다.
import requests
from bs4 import BeautifulSoup
res = requests.get('http://corners.gmarket.co.kr/Bestsellers?viewType=G&groupCode=G07')
soup = BeautifulSoup(res.content, 'html.parser')
bestlist = soup.select('div.best-list')
products = bestlist[1].select('li')
print (products)
for index, product in enumerate(products):
title = product.select_one('a.itemname')
price = product.select_one('div.o-price')
print (title.get_text(), price.get_text())

답변 2