
-
질문 & 답변
카테고리
-
세부 분야
데이터 엔지니어링
-
해결 여부
해결됨
제플린을 이용한 실시간 분석 - 스파크 스칼라 코드
21.11.21 04:43 작성 조회수 291
1
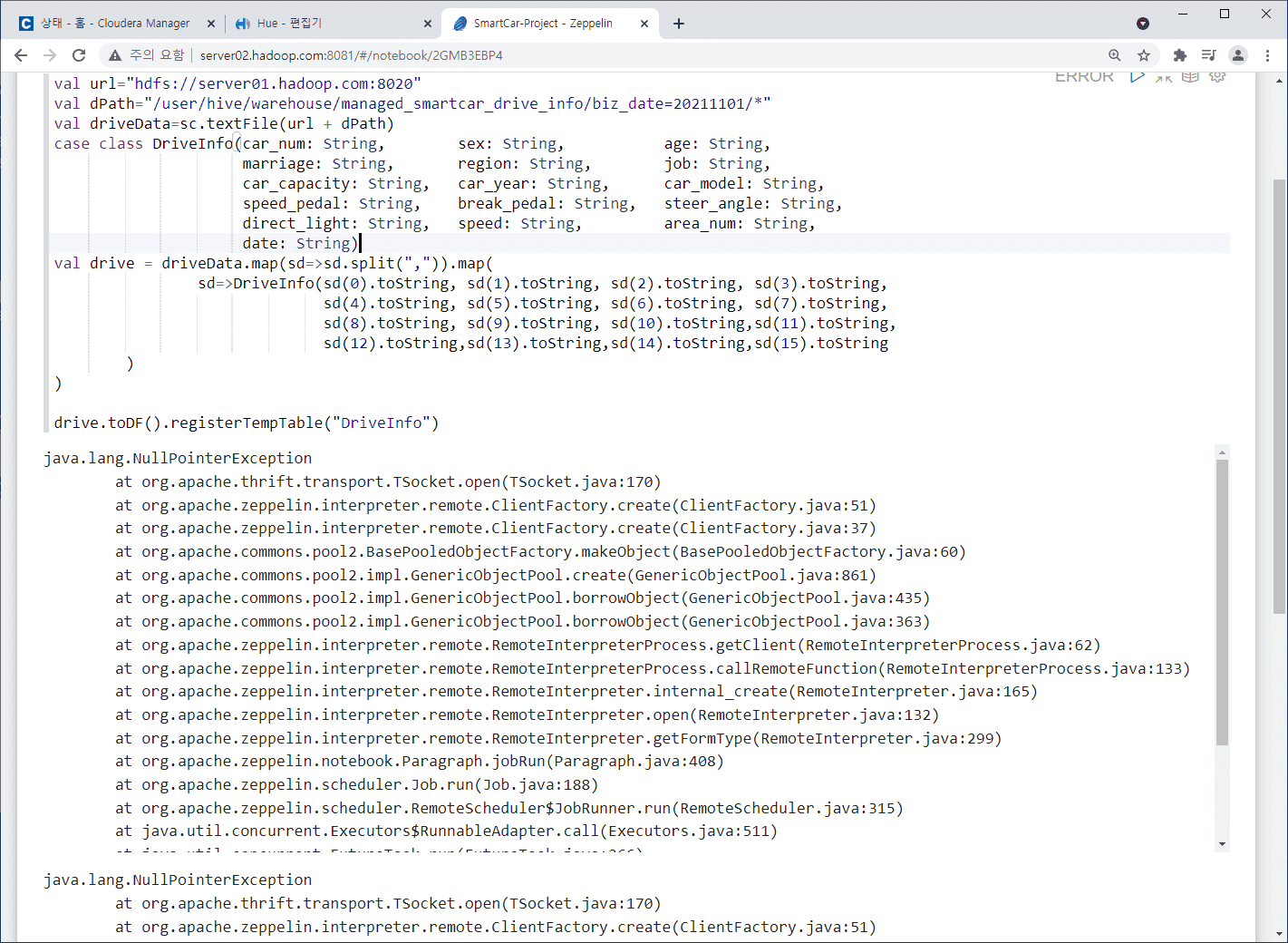
제플린 노트북에서 스파크 데이터를 로드하고 로드한 데이터셋을 스파크에서 활용하기 위해
데이터구조로 만드는 부분에서도 에러가 나타납니다. 제가 무엇을 잘못했을까요?

답변을 작성해보세요.
0

ChangWon Jeong
질문자2021.11.23

제플린 실행 해결되었습니다. 정말 어이없는 실수입니다.
CHD 3개의 영문자가 눈에 정말~~~~ 안들어왔습니다.
모든 설정을 몇번씩 확인하고, 하다 못해 컴퓨터 셋팅을 처음부터 다시해가면서 실습을 진행했는데도 못찾았네요. 저의 손가락을 원망하고 있습니다.
몇일 고생하고 컴퓨터셋팅을 다시 했지만, 복습을 해서 개념은 더 명확히 잡은것 같습니다.

Big.D
지식공유자2021.11.23
네~ ^^*
파일럿 프로젝트를 정확히 따라 하는것도 중요 하지만..
진행 과정에서 트러블슈팅을 경험 하는것이, 이런 미니 프로젝트 기반의 강의에서만 배울수 있는 장점입니다.
좋~은 경험과 지식이 쌓였으니까...괜찮습니다.
- 빅디 드림
0
ChangWon Jeong
질문자2021.11.22
디스크 공간 확보를 위해 파일 삭제후 발생한건 아닙니다.
제가 실습을 진행한 컴퓨터는 처음부터 첫번째 실행에러메시지가 나오고 다음부터는 두번째 실행 에러메시지가 나왔습니다.
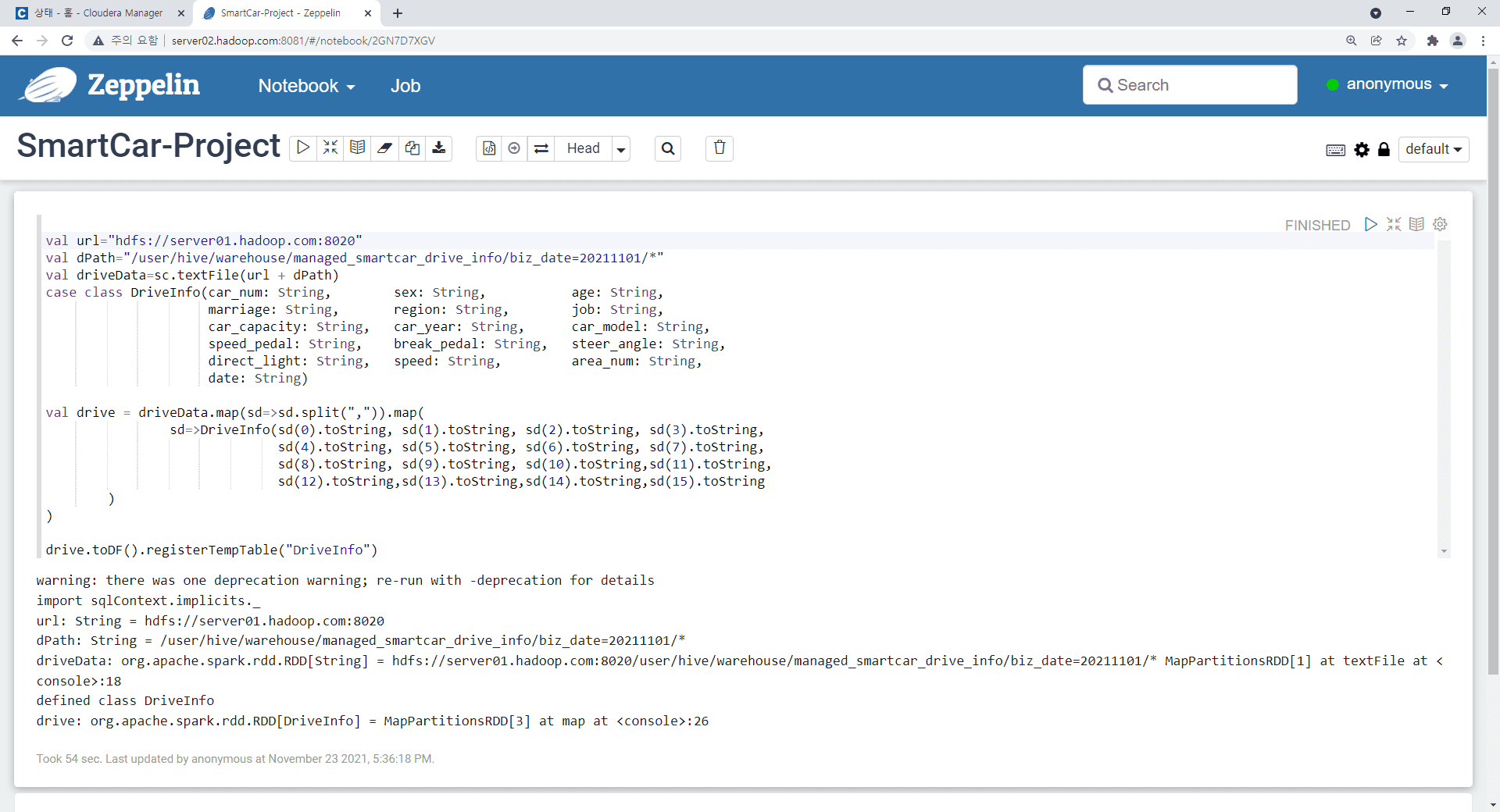
오늘 다른 컴퓨터에서 환경을 다시 구축하고 7장까지 넘어와서 제플린 첫번째 실행에서 예제(그림 7.43)는 실행이 잘 되고, 다음 예제(그림7.45)인 스파크-SQL조회 쿼리에서 동일하게 첫번째 실행했을때(화면) 에러와 첫번째 실행이후에는 두번째 실행했을때(화면) 에러가 발생했습니다.
Big.D
지식공유자2021.11.23
네..이번에도 오타가 문제 인것 같습니다.
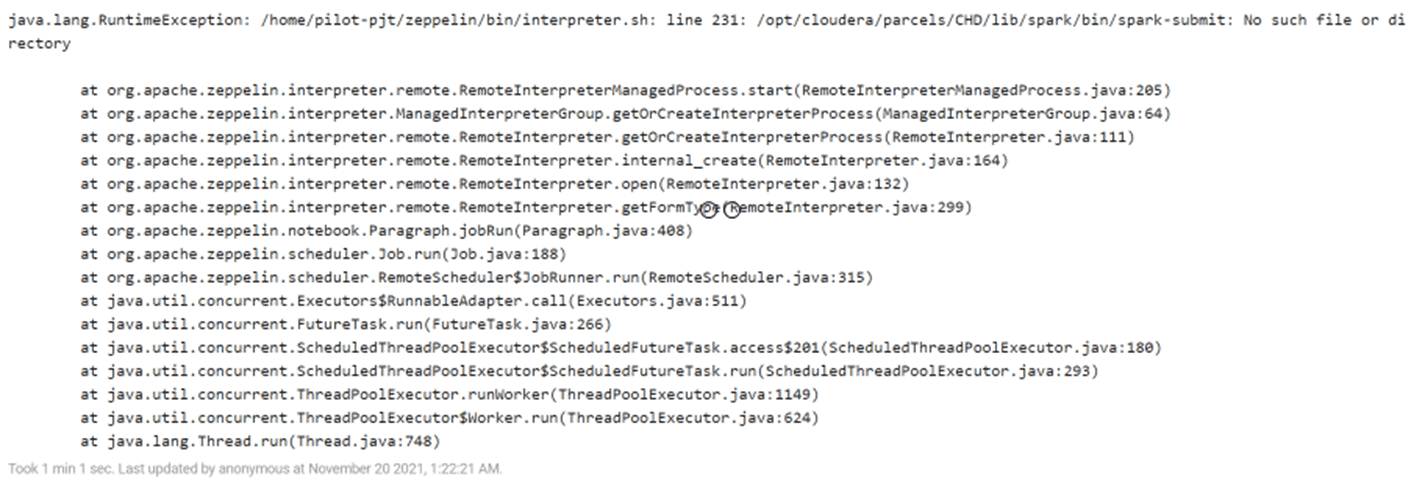
로그상에서 보면 제플린이 SPARK의 경로를 몰라서 나는 에러로 해당 정보는 zeppelin-env.sh에 입력을 합니다.
제플린 설치단계에서 /home/pilot-pjt/zeppelin/conf/zeppelin-env.sh 파일안에 아래와 같이 "SPARK_HOME" 환경변수를 설정 하는게 있었는데요..
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
여기를 CHD --> CDH로 바꾸시면 문제없이 실행 될것으로 보입니다.
제플린에서 스파크를 실행 하려면, 제플린에게 스파크가 설치된 위치를 알려 줘야 하는데, 오타로 해당 경로를 찾지 못해 스파크 실행이 안되는 현상입니다.
- 빅디 드림
0
ChangWon Jeong
질문자2021.11.22
선생님 알려주신대로
1. 파일백업받고
2. 파일삭제 /opt/cloudera/parcel-repo/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el6.parcel
3. Cloudera-scm-server 로그파일 삭제하였습니다.
CM상태는 호전되었습니다.
제플린에서 스파크 스칼라 코드실행은 여전히 동일한 상태입니다.
첨부한 코드를 첫번째 실행했을때 메시지와 두번째부터의 메시지입니다.
실력이 부족하여 질문이 많습니다.
다른 컴퓨터를 이용하여 동일한 실습을 진행하면 이 예제(그림 7.43)는 실행이 잘 되고, 다음 예제(그림7.45)인 스파크-SQL조회 쿼리에서 동일하게 첫번째 실행했을때 에러와 두번째 실행했을때 에러가 발생합니다.
제가 무엇을 잘못하고 있는것인지... 답답합니다. ㅎ

처음실행했을때 메시지
두번째 실행부터의 메시지

Big.D
지식공유자2021.11.22
파일럿 프로젝트를 하면서 이런 어려움에 부딪치고 해결해 보는 경험이 더 중요 합니다. ^^
혹시 첫번째 실행 메지는 언제부터 발생 했나요?!
이번에 디스크 공간 확보를 위해 파일 삭제후 발생 한건가요?!
- 빅디 드림
0
ChangWon Jeong
질문자2021.11.22
제플린을 이용한 실시간 분석에서 그림7.43 스파크 스칼라 코드부분을 실행하지 못하고 있습니다.
연이어서 그림 7.45 스파크-SQL 쿼리실행에도 실행하지 못했습니다.
아래 화면은 그림 7.43 실행후 메시지입니다.

Big.D
지식공유자2021.11.22
네~ 보내주신 캡쳐이미지로 봤을땐...
Server01 로컬 디스크의 용량 부족이 의심스러워 보입니다.
현재 Server01의 디스크 용량이 스왑 영역까지 고려 했을때, 전체 26GB중 25GB 가까이 사용 되고 있어서 추가적인 Job 실행이 어려운 상황같습니다.
Server01의 자원을 좀더 확보할 필요가 있어 보이는데요,
Putty로 Server01에 접속 하셔서, 불필요한 Parcel-Repo 및 로그파일을 삭제해 Disk공간을 확보( 백업후 삭제 )
1. 파일질라로 접속해 해당 파일을 다운로드 받아 백업
- 백업파일경로: /opt/cloudera/parcel-repo/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el6.parcel
2. 아래 명령으로 해당파일 삭제하여 2GB 용량 확보
$ rm -rf /opt/cloudera/parcel-repo/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el6.parcel
3. 로그 양이 많은 Cloudera-scm-server 로그파일 삭제
$ rm -rf /var/log/cloudera-scm-server/*
4. CM에서 클러스터 전체 재시작
위에 절차후 테스트 부탁 드립니다. - 빅디 드림
0
Big.D
지식공유자2021.11.21
안녕하세요! 빅디 입니다.
사용중인 PC 환경(RAM 32GB)은 파일럿 프로젝트 수행에 있어 리소스 문제는 걱정 하지 않으셔도 되는 사양입니다.
다만 파일럿 프로젝트가 분석, 응용 단계로 들어 가면서 많은 서버와 컴포넌트들이 적용 및 사용 되고, CPU/Mem/Disk 등의 임계치 설정값(※ 보통 전체 자원의 70~80% 이상으로 설정 됨)에 가까워져, CM에 표기 되는 경고 메세지들입니다.
보야주신 캡쳐 이미지 상의 경고 메세지에서, 상세를 클릭해 들아가 보시면 Disk 및 Memory 공간의 임계치 도달 메세지들을 확인 하실 수 있습니다.
참고로 서버들의 모니터링 상태가 Red 여도, '셧다운' 및 '정지' 상태가 아닌 이상 실습 하는데 문제 되진 않습니다.
- 빅디 드림
0
ChangWon Jeong
질문자2021.11.21
빅데이터 탐색의 각 주제별 영역 워크플로를 작성하고 실행하는 것까지 잘 실습을 진행하였습니다.
빅데이터 분석으로 단계로 넘어와서 HDFS와 YARN에 문제가 발생하고 있습니다.
선생님 말씀해주신 답변이 저의 상황인것 같습니다. 많은 질문에서 답변 주신것처럼 자원이 부족해서인듯한데....수집에서 사용하는 플럼 카프카 스톰 레디스는 중지한 상태입니다. 가상서버자원을 더 확보할수 있는 방안이 있을까요? 제가 사용하고 있는 시스템은 램32기가, SSD 52O기가입니다.
1.CM상태
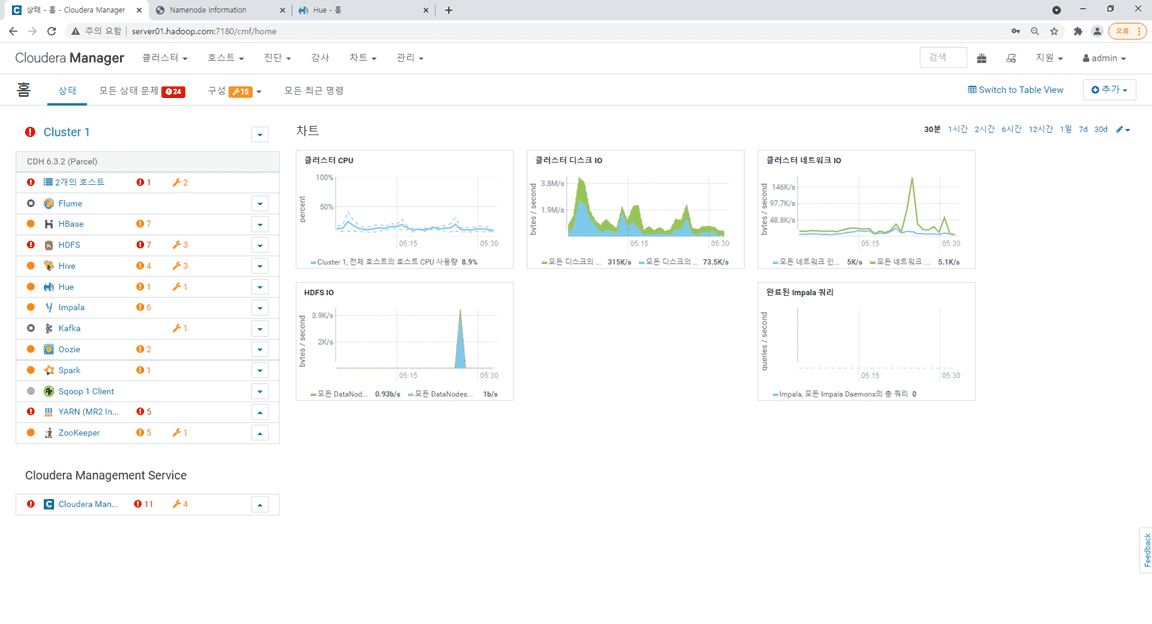
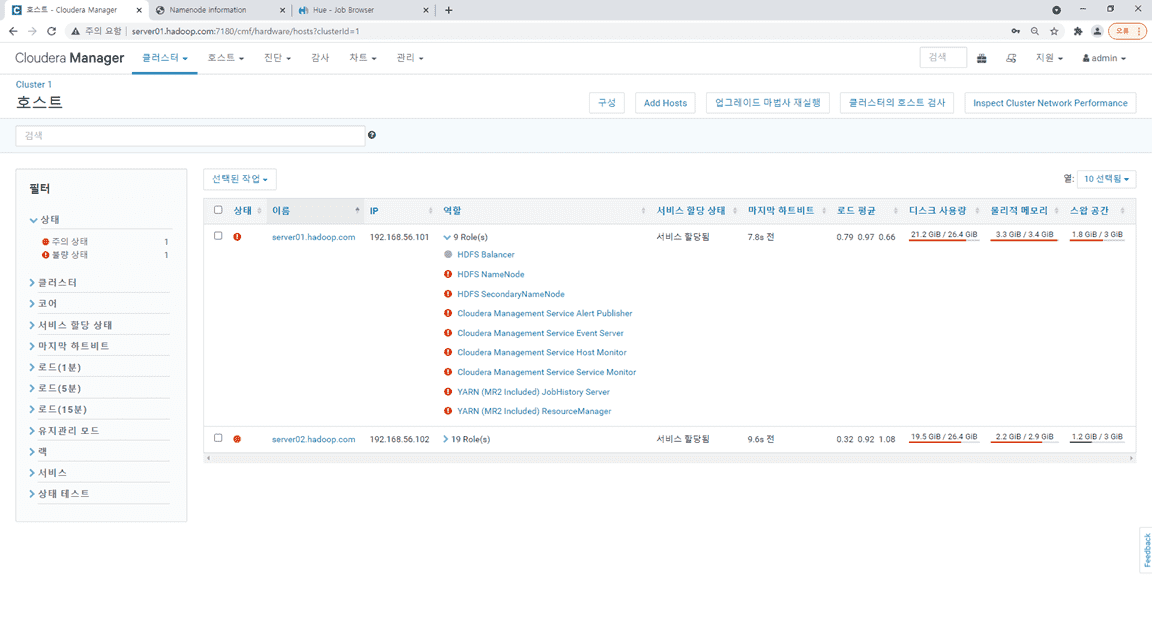
2. 호스트상태
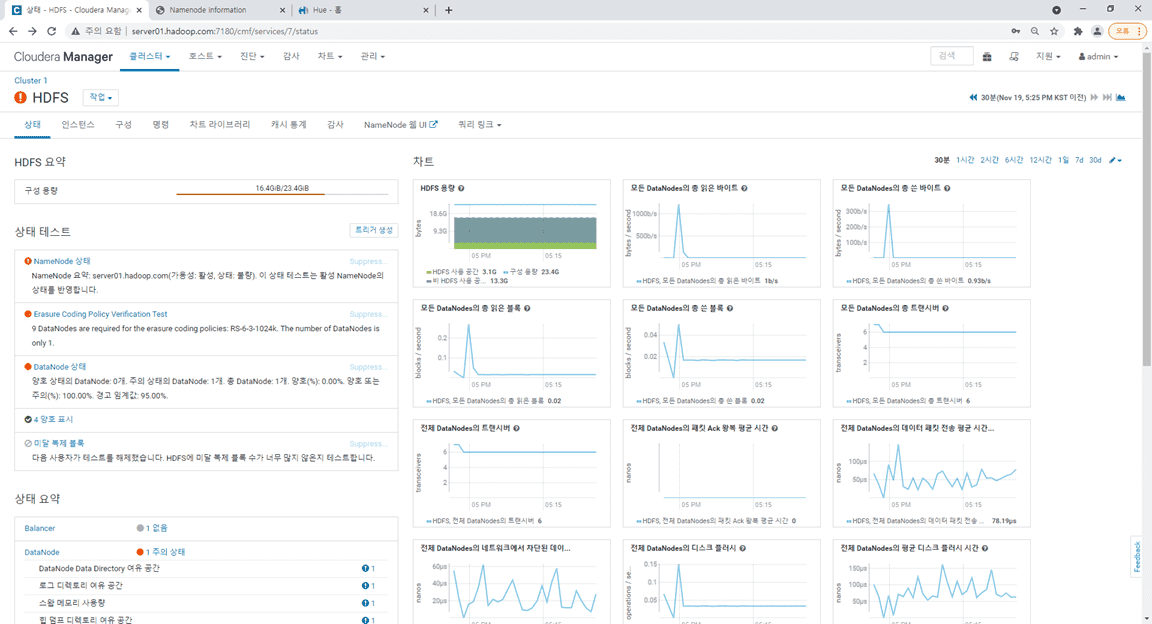
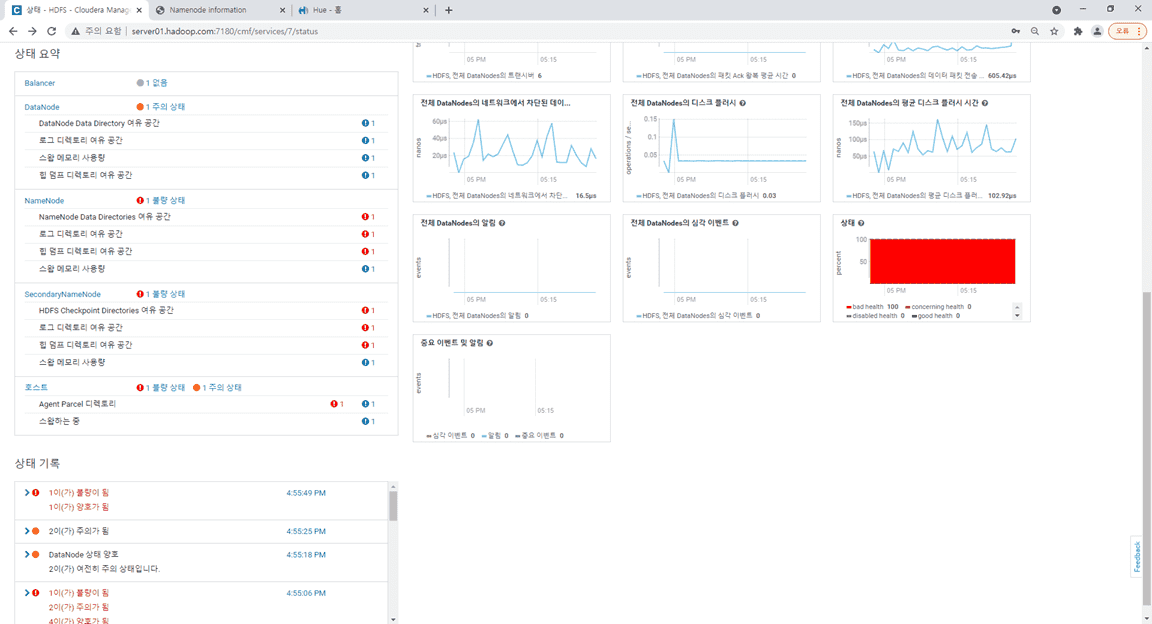
3. HDFS상태
4. YARN상태
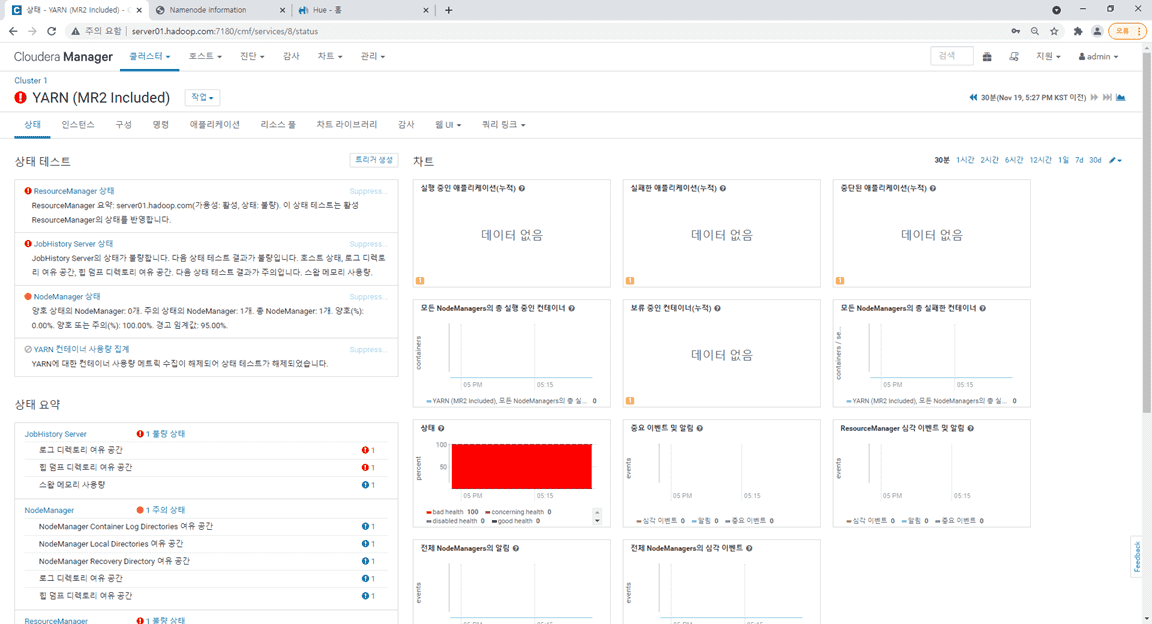
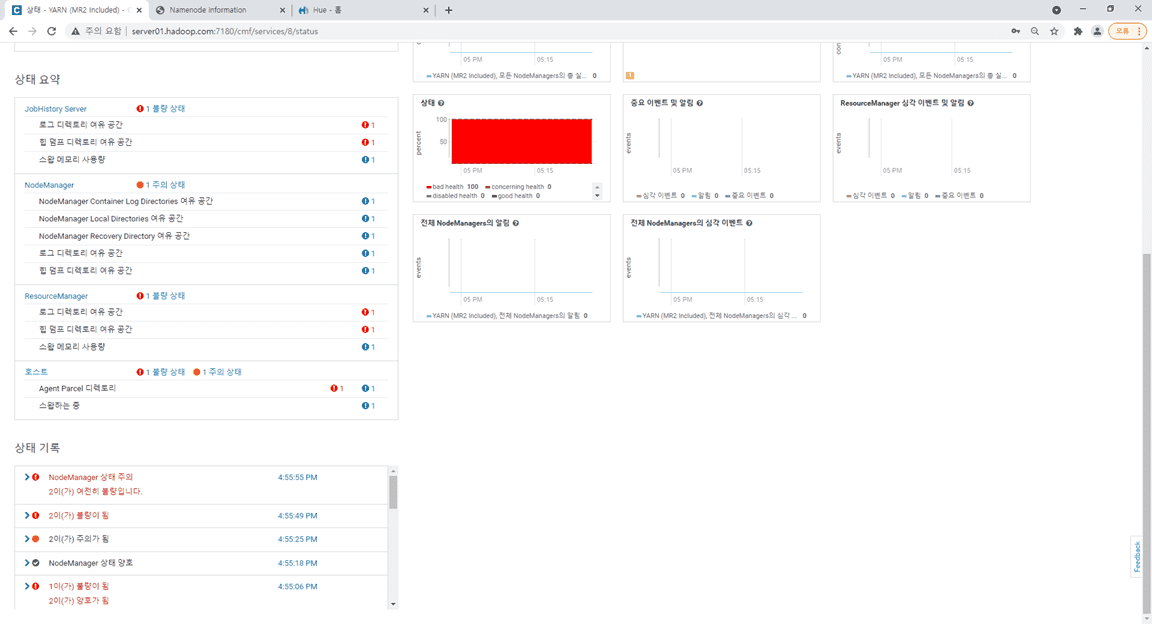
0
Big.D
지식공유자2021.11.21
안녕하세요! 'ChangWon Jeong'님
해당 오류는 데이터 구조를 만들때 나는것이 아니라, 정확히는 데이터 구조를 만들기 전에 데이터를 하둡(HDFS)로 부터 연결해 갖어 오는중에 나는 통신 에러입니다.
즉 하둡의 파일시스템 또는 YARN의 상태를 확인해 봐야 합니다.
그래서 앞의 질문에 아래의 절차대로 확인 요청을 드렸 었는데요..^^;
---------------------------------------------------------------------------------------
안녕하세요! 빅디 입니다.
상단에 코드를 보면 HDFS로 부터 Managed_SmartCar_Drive_Info 데이터를 갖어 오는데요..
이때 HDFS가 Safe모드로 빠져, 데이터를 못갖어와 발생하는 문제가 의심스럽습니다.
아래 내용을 먼저 점검후 테스트 부탁드립니다.
1. HDFS가 Safe 모드로 전환 됐는지 확인
$ hdfs dfsadmin -safemode get
2. 만약 Safe 모드가 On 이라면 아래명령으로 해제
$ hdfs dfsadmin -safemode leave
3. Zeppelin 리스타트
$ zeppelin-daemon.sh restart
-----------------------------------------------------------------
만약 위문제가 아니라면...
CM홈에서 HDFS 와 YARN의 상태를 전체적으로 점검이 필요합니다.
이땐 CM홈에서 Cloudera Manager Service가 정지 되어 있다면 '시작'해 주시고,
HDFS와 YARN도 재시작 해주세요,
Cloudera Manager Service, HDFS, YARN 정상 기동후, 약 1~2분 정도 기다렸다가,
'HDFS'와 'YARN'를 각각 선택해 상세에 들어 가서 '상태요약' 정보 및 로그등을 보시고 문제의 원인을 파악해 봐야 합니다.
- 빅디 드림

답변 7