
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
미해결
GridSearchCV 관련 질문사항입니다!
22.10.22 07:16 작성 조회수 141
0
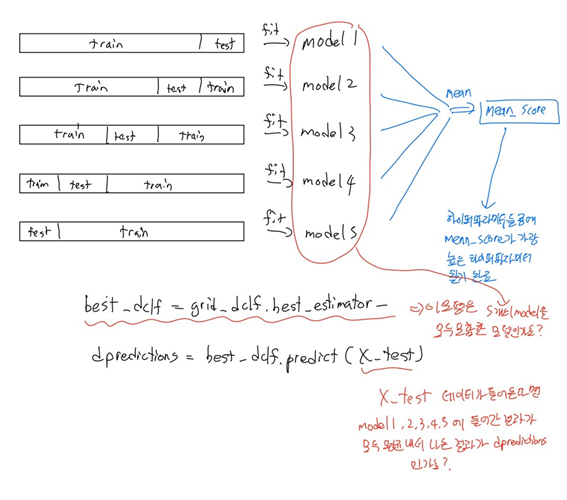
Stratified KFold를 통해서 각각 fold별 train 데이터로 모델을 fit 시키면 model마다 x_test 데이터에 대해서 다른 결과값을 반환할텐데 그렇다면 GridSearchCV를 통해 하이퍼파라미터를 찾고 그 하이퍼파라미터를 적용한 모델 best_estimator_는 어떤 fold로 학습된 모델을 통해 predict을 내는것일까요? 아니면 모든 fold별로 학습된 model 값을 가지고 있다가 x_test 가 그 각각 모델에 들어간후에 평균을 낸 값이 dpredictions으로 나오는걸까요? 단순히 predict을 통해 결과를 내는데 평균을 내서 결과를 내는지 아니면 어떤 한 fold를 기준으로 학습된 모델을 사용하는지 궁금하여 질문 남깁니다!

답변을 작성해보세요.
0

권 철민
지식공유자2022.10.22
안녕하십니까,
질문을 제대로 이해했는지는 모르겠지만,
GridSearchCV는 best_estimator_는 적어주신 두 방식 모두 아닙니다.
GridSearchCV는 특정 하이퍼파라미터를 설정해서 K fold방식으로 학습하고 평가하는데 K Fold가 5이라면 5번 모델을 학습하고 평가하면서 평균 평가값을 계산합니다. 이런 방식으로 반복하면서 기술된 모든 하이퍼 파라미터들을 학습/평가 그리고 평균 평가값을 계산하여, 가장 좋은 평균 평가값을 가진 하이퍼 파라미터를 기반으로 best_estimator_를 학습 데이터로 재 학습 시키는 방식입니다.
혹 원하시는 답변이 아니시면 다시 글 부탁드립니다.
감사합니다.

uiuiui12
질문자2022.10.22
가장 좋은 평가값을 가진 하이퍼파라미터를 기반으로 best_estimator_를 학습데이터로 재학습시킨다고 하셨는데 그렇다면 재학습시킬때는 Kfold를 나눌때처럼 전체 train 데이터를 k가 5일 경우 각각의 fold에는 train을 80프로만 학습에 이용하고 나머지 20프로를 통해 valid로 이용하는 방식이 아닌 전체 100프로 train데이터를 모두 이용해서 학습을 시키는걸까요?

답변 1