
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
해결됨
코드 오류 질문입니다!
22.07.08 02:01 작성 조회수 387
1
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!
- 먼저 유사한 질문이 있었는지 검색해
- 먼저 유사한 질문이 있었는지 검색해



계속 저런 오류가 뜨는데 어떻게 해결할 수 있을까요??
그리고 데이터 파일은 어디서 받아볼 수 있을까요??

답변을 작성해보세요.
0

거친코딩
지식공유자2022.07.10
안녕하세요.
보내주신 데이터 잘 받았습니다.
제가 한번 해본 결과를 말씀드리면,
학습자님께서 데이터를 불러오는 과정에서 문제가 있었던 것 같습니다.
<학습자님 코드>
ratings = pd.read_csv('/book_ratings.csv',
names=r_cols,
sep='/t',
encoding='latin-1')
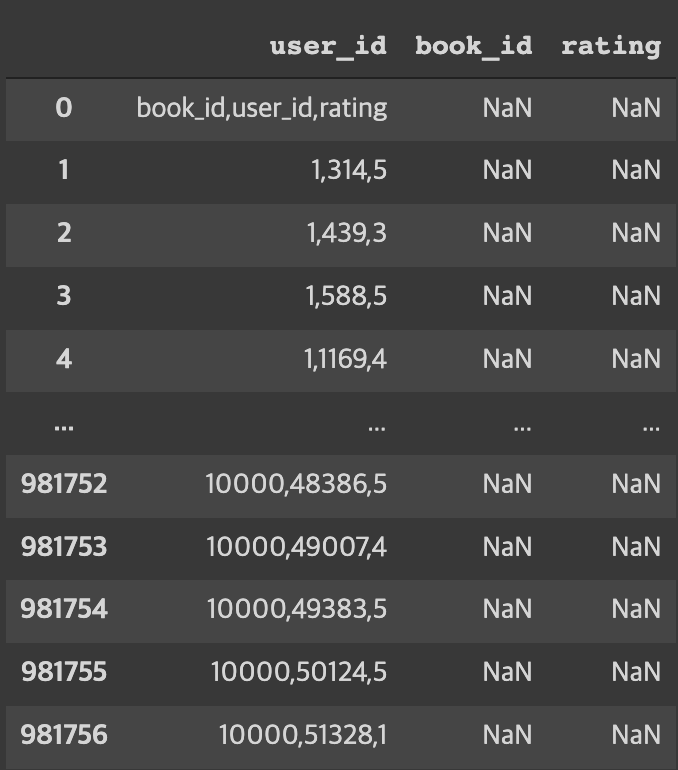
<제 코드>
ratings = pd.read_csv('book_ratings.csv')
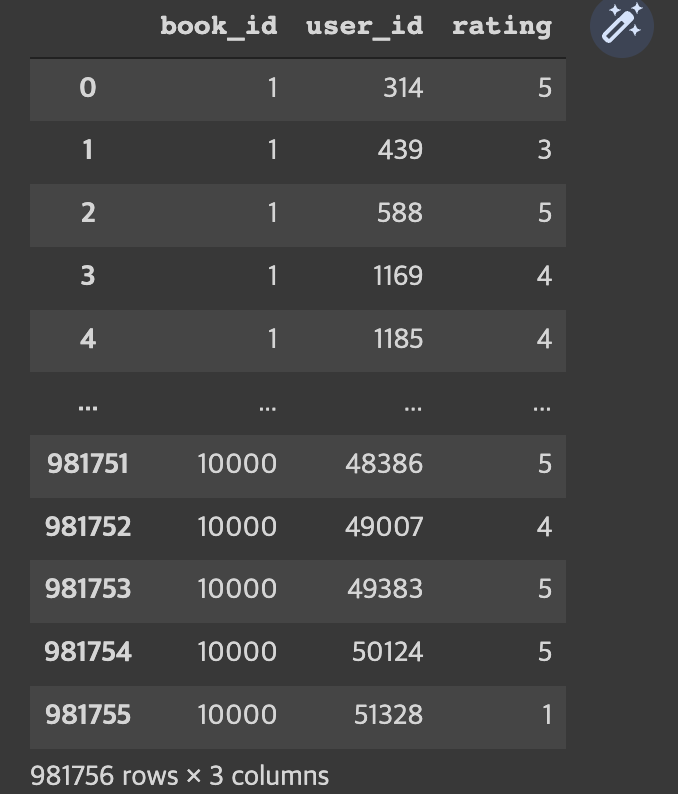
데이터 읽어오는부분은 데이터마다 다 다르기 때문에 해당 부분만 조심하시면 될 것 같습니다.
감사합니다.
-거친코딩 드림-
0
0
거친코딩
지식공유자2022.07.08
안녕하세요.
거친코딩입니다.
올려주신 코드를 확인해보니,
제가 드린 예제가 아니라, 다른 데이터를 가져온 듯 싶네요.
일단 ratings.user_id 자체 타입이 int 이기 때문에,
학습자님의 str 데이터 타입의 max를 읽지 못한 것으로 예상됩니다.
그래서 해당 데이터를 str -> int로 형 변환 하셔서 다시 해보시길 바랍니다.
그래도 안되는 경우 해당 데이터 및 예시코드를 올려주세요.
감사합니다.
-거친코딩 드림-

paper0426
질문자2022.07.09
계속 해봤는데 오류가 뜹니다..!
# csv 파일에서 불러오기
import pandas as pd
# train set과 test set을 나누기 위한 라이브러리
from sklearn.model_selection import train_test_split
# 필요한 tensorflow모듈들을 가져온다.
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input,Embedding,Dot,Add,Flatten
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import SGD,Adamax
# DataFrame 형태로 데이터를 읽어온다.
r_cols = ['user_id', 'book_id','rating']
ratings = pd.read_csv('/book_ratings.csv',
names=r_cols,
sep='/t',
encoding='latin-1')
ratings_train, ratings_test = train_test_split(ratings,
test_size = 0.2,
shuffle=True,
random_state=2021)
K=200
mu=ratings_train.rating.mean()
M = ratings.user_id.max() + 1
N = ratings.book_id.max() + 1
def RMSE(y_true, y_pred) :
return tf.sqrt(tf.reduce_mean(tf.square(y_true-y_pred)))
user = Input(shape=(1,))
item = Input(shape=(1,))
P_embedding = Embedding(M,K,embeddings_regularizer=l2())(user)
Q_embedding = Embedding(N,K,embeddings_regularizer=l2())(item)
user_bias = Embedding(M, 1, embeddings_regularizer=l2())(user)
item_bias = Embedding(N, 1, embeddings_regularizer=l2())(item)

답변 3