
-
질문 & 답변
카테고리
-
세부 분야
업무 자동화
-
해결 여부
해결됨
네이버 쇼핑 크롤링 1
23.07.20 21:53 작성 조회수 974
0
강의 : 네이버 쇼핑 크롤링 1 , 11:14 시점에서 막힙니다.
from bs4 import BeautifulSoup
import requests
keyword = input("검색할 제품을 입력하세요 : ")
url = "https://search.shopping.naver.com/search/all?query={keyword}"
user_agent = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36"
headers = {'User-Agent': user_agent}
req = requests.get(url, headers=headers)
html = req.text
# print(html[:1000]) 확인용
soup = BeautifulSoup(html, "html.parser")
base_divs = soup.select("[class^=product_item]") # product_item 로 클래스 이름이 시작되는 클래스
# print(base_divs)
print(len(base_divs))
for base_div in base_divs:
title = base_div.select_one("[class^=product_link]")
print(title.text)
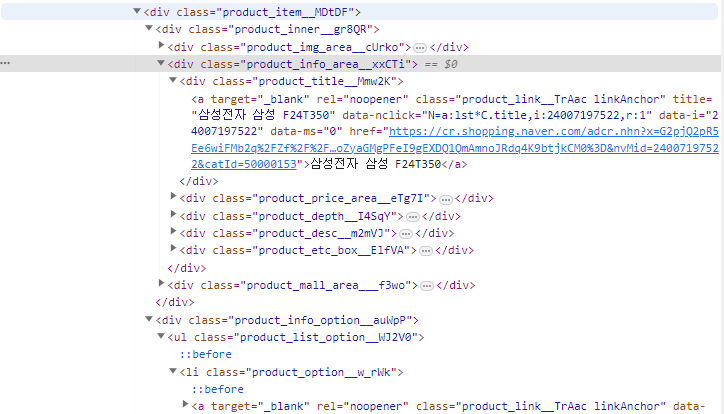
우선 강의에서는 basicLis_item, basicList_link 로 했는데 현재 네이버 쇼핑몰에서는 product_item***, product_link*** 로 되어 있습니다. 아래 스샷처럼요.
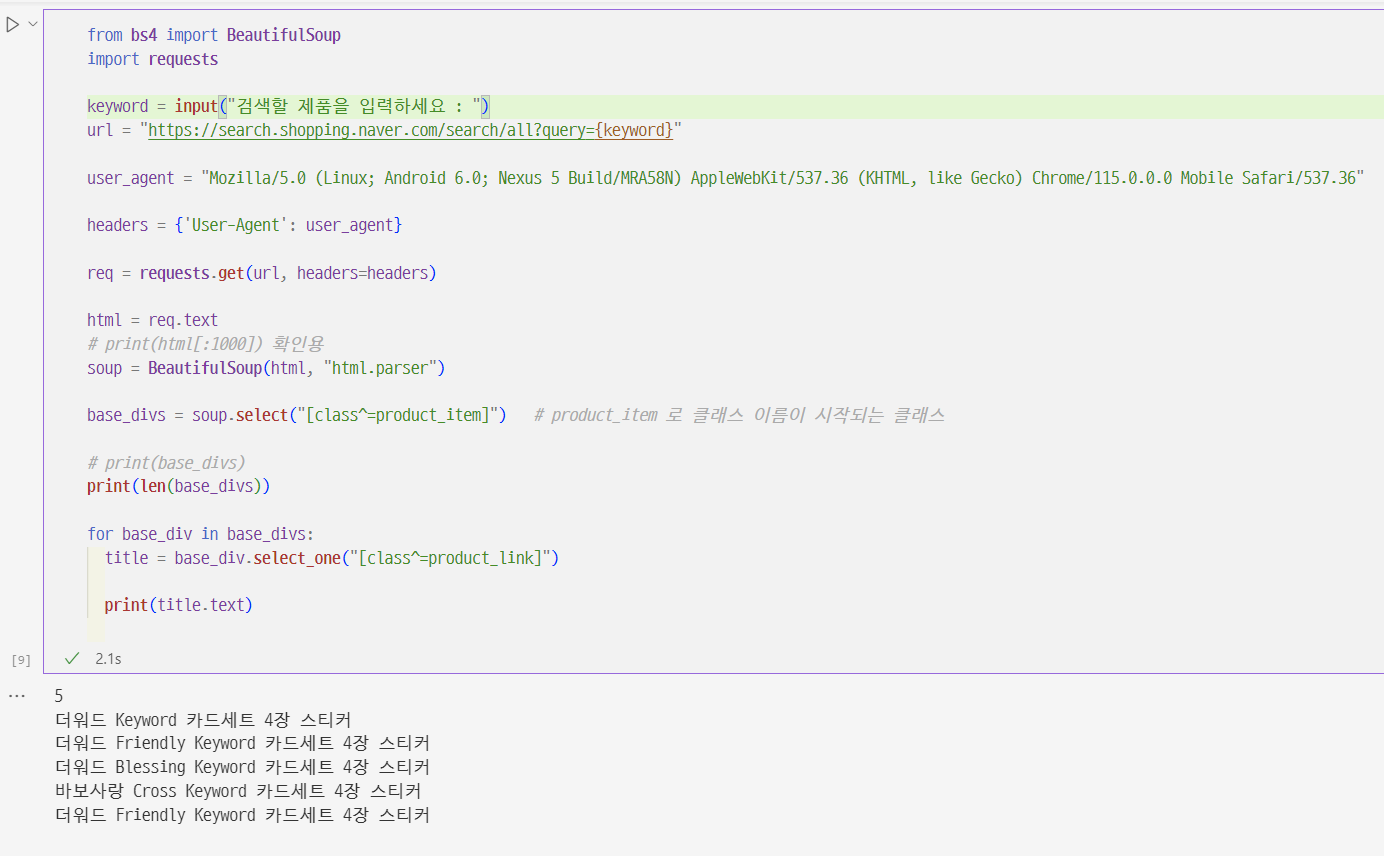
그런데 코드를 치니까 이상한게 나와요 자꾸..
이유가 뭘까요 ??

답변을 작성해보세요.
1

김플
지식공유자2023.07.20
url = "https://search.shopping.naver.com/search/all?query={keyword}"
앞에 f가 빠졌습니다.
이렇게되면 keyword를 input으로 입력받아도
url은 변화가 없이 https://search.shopping.naver.com/search/all?query={keyword} 입니다.
위 주소를 클릭해서 직접 들어가보시면 출력되는게 무엇인지 바로 알수있습니다.

답변 1