
-
질문 & 답변
카테고리
-
세부 분야
백엔드
-
해결 여부
미해결
질문있습니다!
23.02.19 05:46 작성 23.02.19 05:48 수정 조회수 290
2
안녕하세요 수업 질문입니다.
저만 그런건지 age index를 생성하기 전인데도 불구하고,
age로 sort 할 경우 성능이 오히려 3배 가량 향상됩니다.. ㅜㅜ
sort를 작성할 경우 수업과 동일하게 sort_key_generator는 나타나지 않고, documents returned도 0 으로 표기 됩니다.
하지만 explain 탭이 아닌 documents탭에서는 정렬방식이 적용 되어 문제없이 조회되는 걸로 보아 문법을 작성을 잘못 한것 같지않고, sort를 작성하면 explain이 제대로 나타나지 않아 헤매이고있습니다.
index의 장점을 직접 체험하기 위해 데이터는 약 100만개 정도 생성한 상태로 따라해보는데, 의도와는 다른 현상이 나타나 질문드립니다!!

답변을 작성해보세요.
0

김시훈
지식공유자2023.02.19
안녕하세요!
음 기본적으로 age로 소팅을 하려고 할 때 인덱스가 걸려 있지 않으면 무조건 더 느려요. IndexScan 대신 CollectionScan을 하기 때문이죠.
좀 더 구체적으로 상황을 설명해주실 수 있을까요?
해당 컬렉션 스키마, 테스트 해보고 싶은 쿼리, 인덱스 정보(아틀라스에서 해당 컬렉션 가면 indexes탭이 있는데 이걸 스샷 찍어서 보여주시면 될 것 같아요), explain도 보여주시면 좋고요

꼴쥐
질문자2023.02.20
[index 생성전]
sort없이 filter 조건만 부여했을 경우 아래와 같은 결과가 나옵니다.
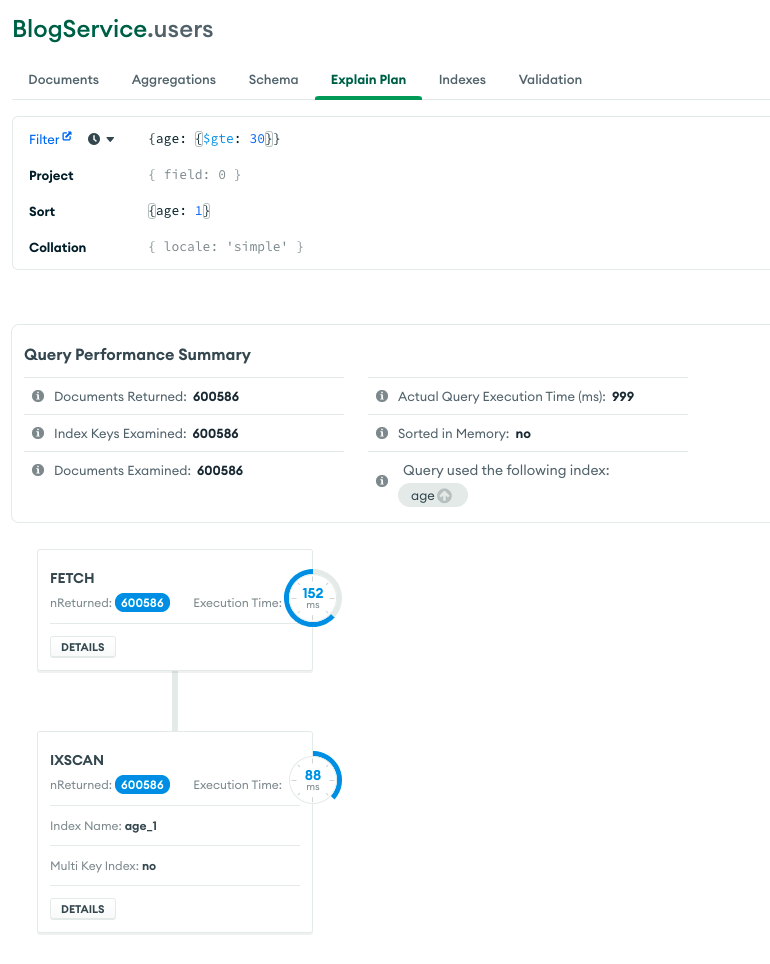
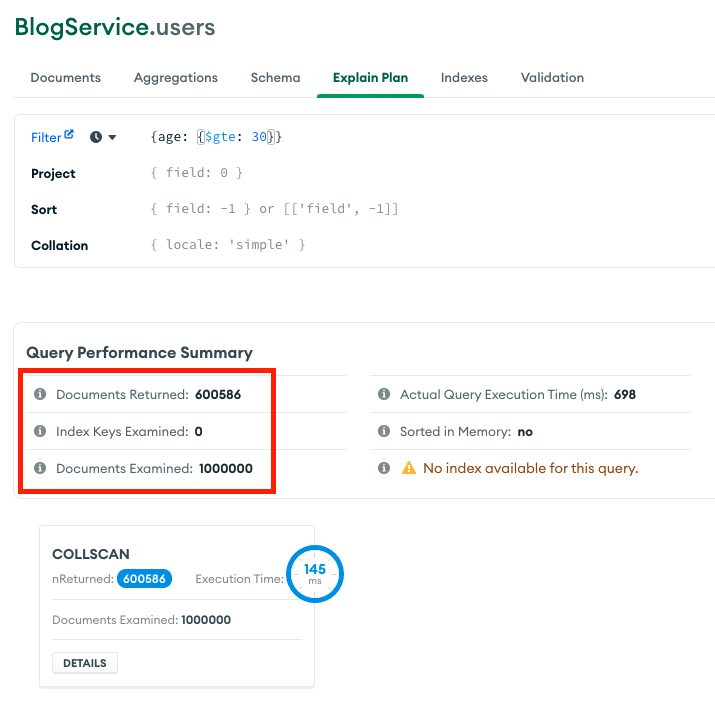 하지만, 강의와 동일하게 sort를 포함하여 find 옵션 구성시 아래와 같이 explain plan에서는 documents returned가 0이며,
하지만, 강의와 동일하게 sort를 포함하여 find 옵션 구성시 아래와 같이 explain plan에서는 documents returned가 0이며,
시간은 단축, sort_key_generator 표시 없는 결과값입니다ㅠㅠ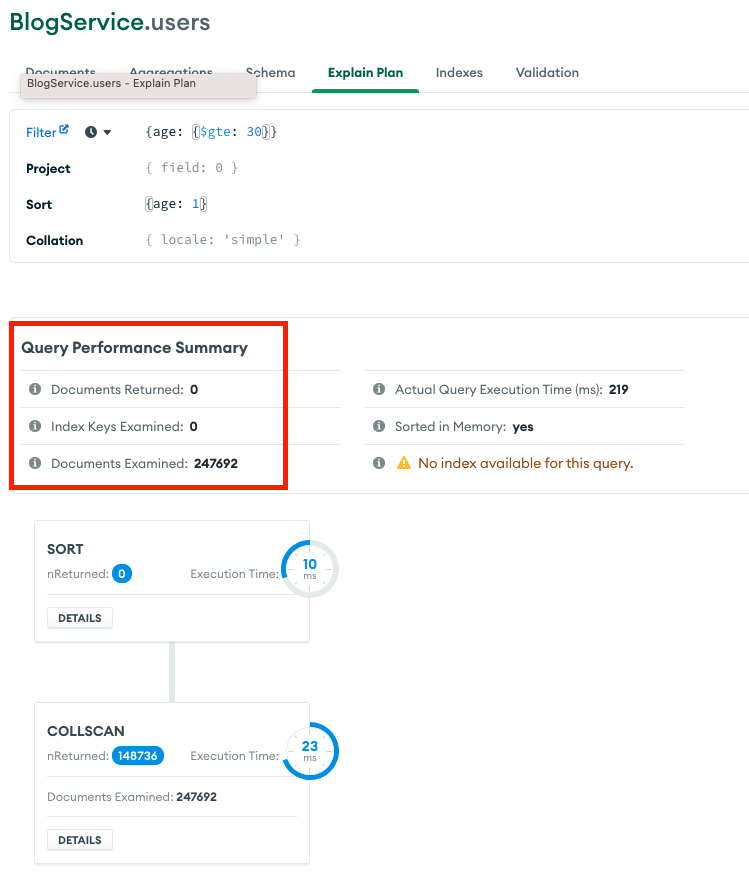
[index 생성 후]
인덱스 생성 후 컬렉션 스캔이 아닌 인덱스 스캔들 하지만 시간이 반대로 늘어나서 혼란스럽습니다..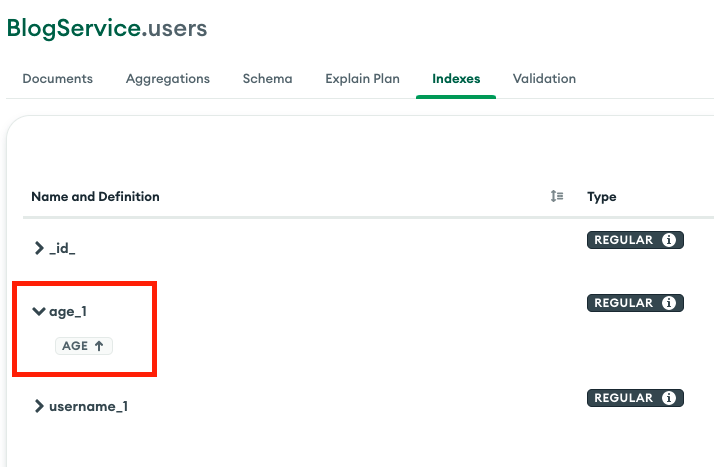
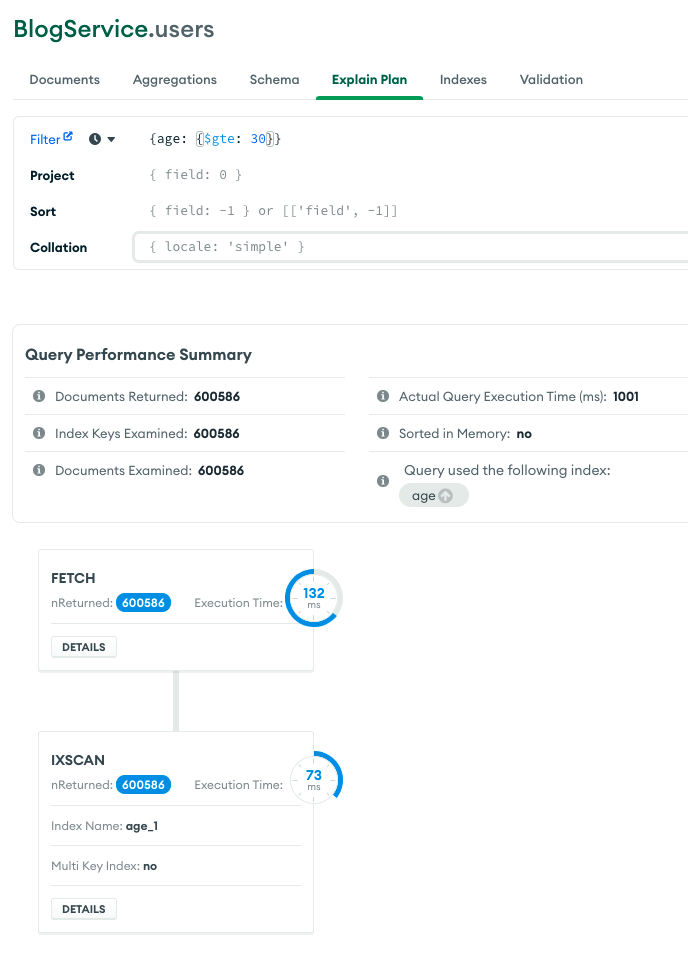
 [users schema]
[users schema]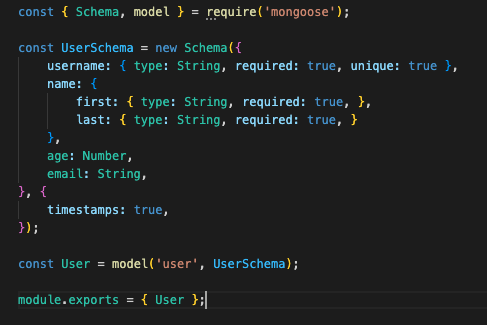
도움 부탁드립니다!! 감사합니다.
김시훈
지식공유자2023.02.24
좋은 질문입니다 그리고 답변이 늦어서 죄송합니다!
인덱스를 추가해서 더 느려진 이유는 "너무 많은 데이터"를 불러오기 때문이에요. 강의에서 보면 isActive: boolean과 같은 변별력이 적은 필드에는 인덱스를 쓰는게 도움이 되지 않는다고 했는데요. 비슷한 상황이 된겁니다.
IsActive: true or false 이렇게 두가지 옵션 밖에 없죠
age: { $gte: 30 } 이것도 사실상 비슷한 상황이에요. 30보다 크거나 작거나인거죠.
30보다 큰게 엄청 많죠. 그러면 그 인덱스들을 모두 불러오고 나서 그 다음에 책갈피 역할을 하는 인덱스를 이용해서 해당 문서를 하나하나 FETCH 해야됩니다. 인덱스가 없을 때는 FETCH가 없던 이유가 인덱스가 없기 때문에 COLLSCAN(Collection Scan) 자체가 처음부터 문서를 하나하나 이미 "FETCH" 하기 때문이에요.
그래서 아이러니 하게 오히려 인덱스로 두단계가 되면서 더 느려진겁니다.
근데 그렇다면 이 경우 인덱스를 쓰지 말라는건가?? 언제 써야되는거지?
이 경우 인덱스를 사용하는게 맞습니다!
단, "불러오고 싶은 데이터"만 불러오는거죠. 저희가 인덱스를 거는 이유는 클라이언트가 요청 했을 때 최대한 "빠르게" 해당 데이터를 탐색해서 보내주는건데요. 절대 많은 양의 데이터를 한번에 보내지 않아요. 화면에 보여줄 수 있는만큼만 보내주죠. 더 보고 싶으면 페이지네이션을 적용해서 다음 페이지에 해당되는 데이터를 추가로 요청하고요.
한 화면에 10개? 넉넉하게 스크롤까지 고려해서 많아야 100개도 못 보여주겠죠?
User.find({ $gte: 30 }).limit(100) 이렇게 해서 explain을 돌려보세요. 압도적으로 빠를거에요.
IXSCAN(인덱스 탐색) -> FECH(해당 인덱스가 가리키는 문서 불러오기) 이렇게 두단계이긴 하지만 딱 100개만 탐색하면 되기 때문에 IXSCAN으로 거의 즉시 탐색(~10ms.더 낮게 나올수도 있고요)을 할겁니다. 그러면 해당되는 100개만 FETCH하면 되죠.
인덱스가 없으면 COLLSCAN을 하게 되는데 100만개의 문서가 있고 age가 30보다 큰 문서들이 99만번째에 있다고 생각해보세요. 그러면 몽고디비 서버는 99만번까지 하나하나 확인을 해봐야되요. 엄청 느려지는거죠. 그에반면 인덱스를 사용하면 age 오름차순으로 쫙나열이 되어 있으니깐 바로 찾아낼 수 있게 되죠!

답변 1