
-
질문 & 답변
카테고리
-
세부 분야
백엔드
-
해결 여부
미해결
insert -> select 와 update-> select 의 동작 차이가 이해가 안됩니다.
20.08.25 23:52 작성 조회수 166
0
안녕하세요 계속 질문을 드르게 되네요.
PostRepository 안에 a() 와 b() 라는 메소드를 두개 만들고,
a() 메소드는 아래와 같이 save 한후, findById() 로 찾는것 입니다.
Insert 쿼리와 select 쿼리가 모두 수행 됐습니다.
==a() 메소드 코드==
@Transactional
private void test04(){
System.out.println("-------------- test 04 시작 ---------------");
Post post = new Post();
post.setTitle("test_04");
post.setLikeCount(1);
post.setCreatDate(new Date());
Post savedPost = postRepository.save(post);
Optional<Post> findPost = postRepository.findById(savedPost.getId());
System.out.println("Result====>"+ findPost.get().getTitle() );
}
==수행결과==
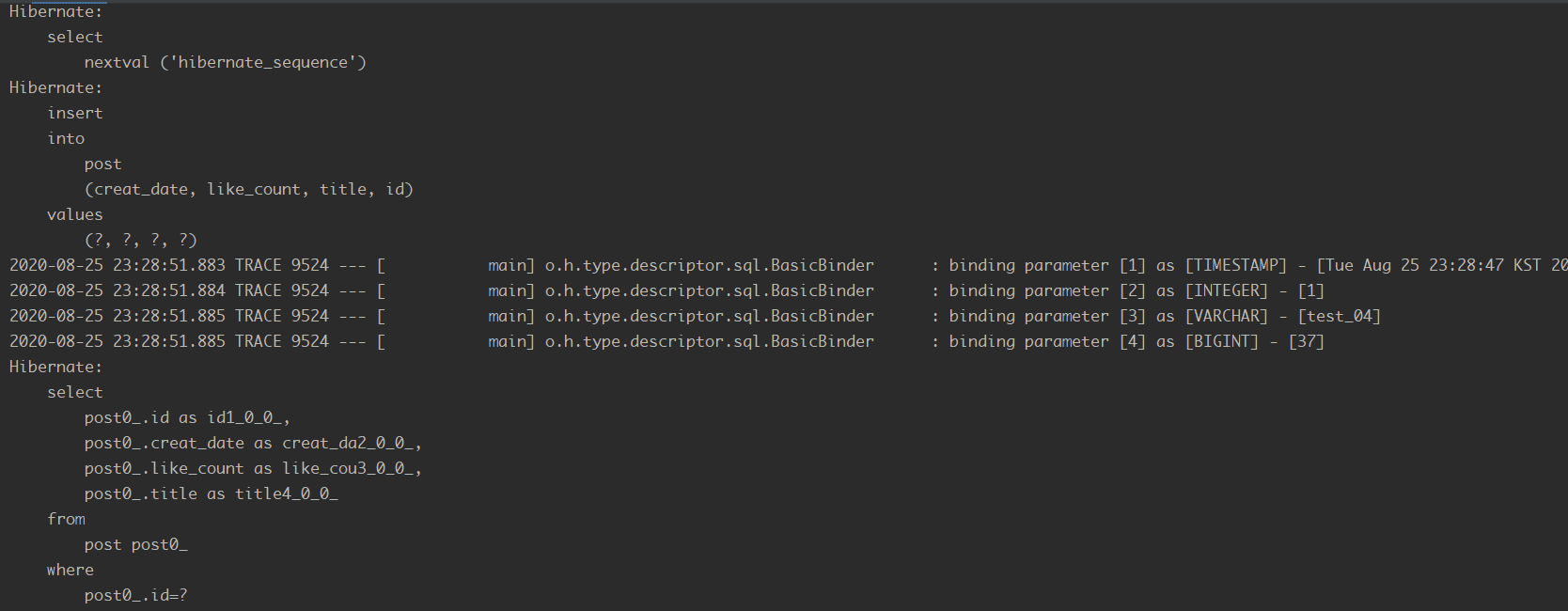
b() 메소드를
"스프링 데이타 JPA6 update쿼리 " 챕터에서 말씀 하신것처럼 만들면, 강의 하실때 말씀 하시길
update() <- (직접만든것은 권장안함) 수행 후 에 findById() 로 조회를 하게 되면,
PersistenceContext 에 영속성으로 들어가 있어서 불필요한 쿼리 라고 생각 해서 update 만 수행 되고 select 쿼리는 수행 안된다고 하셨습니다.
왜 a() 와 b() 메소드가 서로 수행이 왜 틀린거죠?
a() 메소드 역시 영속성 컨테이너에는 db에 저장한 내용이 남아 있으니, findByid 시에 쿼리를 날리지 않아도 되지 않나요?
지연 쿼리이고, 싱크를 맞추기 위해 findById() 수행 시점에 Insert 쿼리와 select 쿼리가 날라 간다고 여러 차례 말씀 하셨는데요
a() 와 b() 메소드 모두 db 작업을 했고, db 작업 후에 findById()를 하는것인데
insert 문은 수행한 a() 는 싱크를 맞추기 위해 select문을 수행하고
update문을 수행한 b()는 싱크를 맞추지 않고 영속성 context에서 가져오는 이유를 모르겠습니다.

답변을 작성해보세요.
0

0

백기선
지식공유자2020.08.26
제가 해당 수업 영상을 다시 확인하지 않았지만 제가 강의 중에 말을 잘못했었나보네요. findById가 아니라 findAll을 말한건데요/ Pesist 상태의 객체를 findById하는 경우에는 save를 했든 update를 했든 추적중인 PersistentContext에 들어있기 때문에 다시 조회할 필요가 없어서 select 쿼리가 발생하지 않아야 합니다.
지금처럼 그런 쿼리가 보인다면 트랜잭션 처리가 제대로 안된거고 Persist 상태인 객체가 없기 때문에 다시 조회했을 겁니다.

답변 2