
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
해결됨
안녕하세요, 한글 깨짐 현상 관련하여 질문드립니다
22.01.15 16:23 작성 조회수 446
1
안녕하세요, 강의 잘 듣고 있습니다. 네이버 금융 사이트에서 다음 부분의 내용을 크롤링하려고 했습니다.
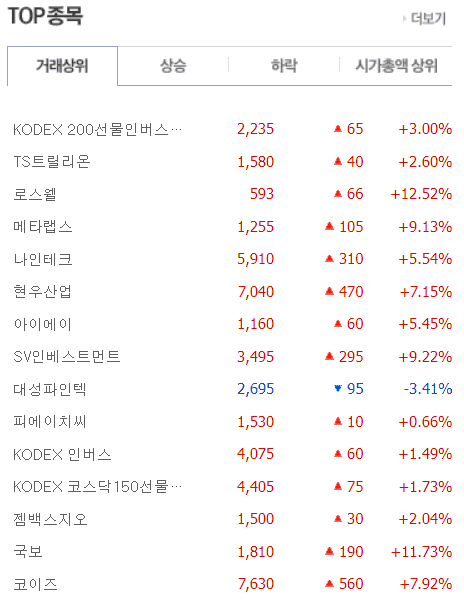
그래서 강의에서 제시해 주신 대로 크롤링을 하였는데 한글 깨짐 현상이 발생하는 것을 확인할 수 있었습니다...
구글링을 해보니, 네이버 금융 사이트에서 인코딩 관련 문제가 생기는 것을 찾을 수 있었고, 이를 해결하기 위해 더 정보를 찾아보니
다음과 같이 코드를 작성해 주면 한글 깨짐 현상이 해결됨을 확인할 수 있었습니다.
아직 크롤링 초보라 문제가 해결됨은 눈으로 확인하여도, 강사님이 설명해 주시는 것 만큼 뭔가가 확실하게 풀리는 느낌은 없어서요...
위와 같이 인코딩 문제가 발생하였을 때의 상황은 이렇게 해결하는 것이 맞나요?? 혹시 부가적인 설명도 가능하다면 조금 부탁드립니다ㅠㅠ
특히 urllib 를 사용해본 경험이 많지 않아서 해당 라이브러리 안에 어떤 모듈이나 함수를 사용해야 하는지 잘 모르겠습니다..
답변해주시면 감사하겠습니다!

답변을 작성해보세요.
0

잔재미코딩 DaveLee
지식공유자2022.01.17
안녕하세요.
아무래도 기술들이 여러가지가 연결이 되다보니, 한번에 완벽하게 알기는 어려운 것은 맞을 것 같아요. 이를 한꺼번에 싹 다 한번에 설명한다고 다 이해가 되는 것은 아니더라고요. 그래서 초급 중급 이렇게 나눠서 단계별로 설명드리고 있습니다. 특히 크롤링은 웹사이트를 어떻게 만들었느냐에 따라 굉장히 다양한 케이스가 발생할 수 있는 것이 맞고요.
인코딩은 웹사이트 데이터 인코딩이 다른 경우가 있어서 그런 것 같습니다. 이 때는 데이터 인코딩을 변환해줘야 할 것 같고, urllib 으로 하든, requests 로도 하든 둘다 네트워크 통신을 위한 유사한 목적을 가진 라이브러리라서, requests 로도 인코딩 변환은 가능합니다. 다만 인코딩 처리는 가끔은 완벽하게 되기 어려운 경우가 있어서, 잘안되는 경우, 두 라이브러리를 둘다 써봐도 좋을 것 같습니다. 왜냐하면 데이터를 가져와서 인코딩을 처리하는 방식이 urlib 과 requests 내부에서 다른 부분이 있는 것으로 이해하고 있습니다. requests 에서의 인코딩 처리도 구글링을 통해, 다음과 같은 링크로 참고해보시는 것도 또 좋을 것 같습니다.
https://wikidocs.net/48470



답변 1