
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
미해결
crawling시 값을 못가져오는 경우...
21.10.28 23:35 작성 조회수 200
0

답변을 작성해보세요.
0

잔재미코딩 DaveLee
지식공유자2021.10.30
안녕하세요. 우선은 각자 연습해보시는 것은 너무 좋을 수도 있지만, 입문자 레벨에서 다양한 웹페이지를 크롤링 시도를 해보시면 또 역시 이슈가 발생할 수 있는 것은 사실이예요. 본 강의 질문/답변은 강의 영상에 대한 이해가 안가실 때 이부분을 해결해드려야, 다음 단계로 나가실 수 있으실 것 같아서, 오픈해놓은 질문/답변이거든요. 그런데 여기에 각자 크롤링 이슈를 문의하시다보면, 제가 해당 코드를 확인하려면 결국 제가 각자 원하시는 크롤링 코드를 작성하는 상황이 발생하더라고요. 즉, 일종의 외주를 평생 저에게 맡기는 상황이 되버려서요. 이 부분은 양해를 부탁드려요.
가볍게 설명드리면, 요즘에는 크롤링을 막기 위함도 있고, 웹사이트 기술이 발전해서, 일부 데이터는 정적인 웹페이지가 아니라, 특정 데이터를 동적으로 가져옵니다. 동적으로 만들어지기 때문에, 정적인 웹페이지에서 데이터를 크롤링하는 기술로는 크롤링이 안됩니다. 이렇게 동적인 데이터를 크롤링하는 또다른 기술이 selenium 이고요. 관련 기술은 난이도가 조금 높아요. 그래서 관련된 부분은 별도 강의로 상세히 설명은 드리고 있습니다.
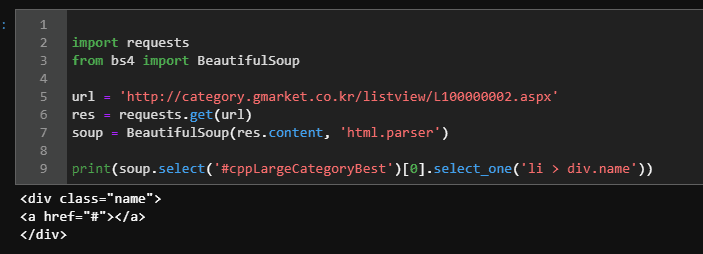
해당 페이지를 오른쪽 클릭하셔서, 소스 보기를 하시면 해당 정적인 웹페이지 태그에는 다음과 같이 나와있더라고요. 이 부분을 보시면 이해하실 수 있으실 것 같습니다.
감사합니다.


답변 1