
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
미해결
Swarmplot 에러
23.06.04 18:40 작성 조회수 310
1
강의 회차 : [20/20] 지역별 분양가를 시각화하고 정리하기
질문 : 마지막 시각화 단계에서, boxplot, boxenplot, violinplot 다 잘 구현되는데 swarmplot만 계속 에러가 납니다. 구글에서 에러메시지 검색도 해 봤는데, 잘 해결이 안되네요.. 확인해 주실 수 있으신가요.
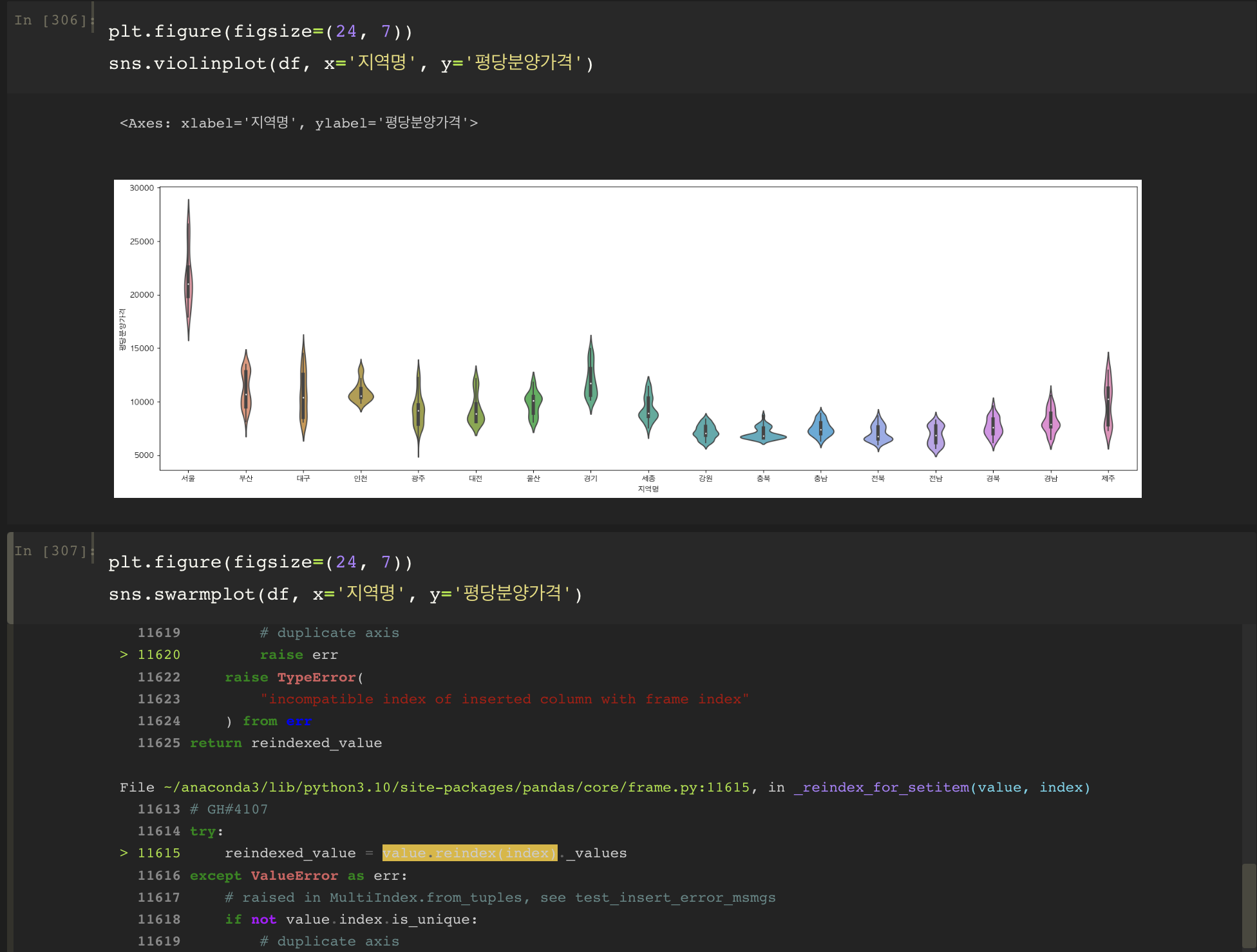 * 에러메시지도 함께 첨부드립니다.
* 에러메시지도 함께 첨부드립니다.--------------------------------------------------------------------------- ValueError Traceback (most recent call last) Cell In[307], line 2 1 plt.figure(figsize=(24, 7)) ----> 2 sns.swarmplot(df, x='지역명', y='평당분양가격') File ~/anaconda3/lib/python3.10/site-packages/seaborn/categorical.py:2664, in swarmplot(data, x, y, hue, order, hue_order, dodge, orient, color, palette, size, edgecolor, linewidth, hue_norm, native_scale, formatter, legend, warn_thresh, ax, **kwargs) 2657 linewidth = size / 10 2659 kwargs.update(dict( 2660 s=size ** 2, 2661 linewidth=linewidth, 2662 )) -> 2664 p.plot_swarms( 2665 dodge=dodge, 2666 color=color, 2667 edgecolor=edgecolor, 2668 warn_thresh=warn_thresh, 2669 plot_kws=kwargs, 2670 ) 2672 p._add_axis_labels(ax) 2673 p._adjust_cat_axis(ax, axis=p.cat_axis) File ~/anaconda3/lib/python3.10/site-packages/seaborn/categorical.py:330, in _CategoricalPlotterNew.plot_swarms(self, dodge, color, edgecolor, warn_thresh, plot_kws) 321 def plot_swarms( 322 self, 323 dodge, (...) 327 plot_kws, 328 ): --> 330 width = .8 * self._native_width 331 offsets = self._nested_offsets(width, dodge) 333 iter_vars = [self.cat_axis] File ~/anaconda3/lib/python3.10/site-packages/seaborn/categorical.py:229, in _CategoricalPlotterNew._native_width(self) 226 @property 227 def _native_width(self): 228 """Return unit of width separating categories on native numeric scale.""" --> 229 unique_values = np.unique(self.comp_data[self.cat_axis]) 230 if len(unique_values) > 1: 231 native_width = np.nanmin(np.diff(unique_values)) File ~/anaconda3/lib/python3.10/site-packages/seaborn/_oldcore.py:1134, in VectorPlotter.comp_data(self) 1132 else: 1133 comp_col = pd.Series(dtype=float, name=var) -> 1134 comp_data.insert(0, var, comp_col) 1136 self._comp_data = comp_data 1138 return self._comp_data File ~/anaconda3/lib/python3.10/site-packages/pandas/core/frame.py:4786, in DataFrame.insert(self, loc, column, value, allow_duplicates) 4783 if not isinstance(loc, int): 4784 raise TypeError("loc must be int") -> 4786 value = self._sanitize_column(value) 4787 self._mgr.insert(loc, column, value) File ~/anaconda3/lib/python3.10/site-packages/pandas/core/frame.py:4877, in DataFrame._sanitize_column(self, value) 4875 return _reindex_for_setitem(value, self.index) 4876 elif is_dict_like(value): -> 4877 return _reindex_for_setitem(Series(value), self.index) 4879 if is_list_like(value): 4880 com.require_length_match(value, self.index) File ~/anaconda3/lib/python3.10/site-packages/pandas/core/frame.py:11620, in _reindex_for_setitem(value, index) 11616 except ValueError as err: 11617 # raised in MultiIndex.from_tuples, see test_insert_error_msmgs 11618 if not value.index.is_unique: 11619 # duplicate axis > 11620 raise err 11622 raise TypeError( 11623 "incompatible index of inserted column with frame index" 11624 ) from err 11625 return reindexed_value File ~/anaconda3/lib/python3.10/site-packages/pandas/core/frame.py:11615, in _reindex_for_setitem(value, index) 11613 # GH#4107 11614 try: > 11615 reindexed_value = value.reindex(index)._values 11616 except ValueError as err: 11617 # raised in MultiIndex.from_tuples, see test_insert_error_msmgs 11618 if not value.index.is_unique: 11619 # duplicate axis File ~/anaconda3/lib/python3.10/site-packages/pandas/core/series.py:4914, in Series.reindex(self, index, axis, method, copy, level, fill_value, limit, tolerance) 4897 @doc( 4898 NDFrame.reindex, # type: ignore[has-type] 4899 klass=_shared_doc_kwargs["klass"], (...) 4912 tolerance=None, 4913 ) -> Series: -> 4914 return super().reindex( 4915 index=index, 4916 method=method, 4917 copy=copy, 4918 level=level, 4919 fill_value=fill_value, 4920 limit=limit, 4921 tolerance=tolerance, 4922 ) File ~/anaconda3/lib/python3.10/site-packages/pandas/core/generic.py:5360, in NDFrame.reindex(self, labels, index, columns, axis, method, copy, level, fill_value, limit, tolerance) 5357 return self._reindex_multi(axes, copy, fill_value) 5359 # perform the reindex on the axes -> 5360 return self._reindex_axes( 5361 axes, level, limit, tolerance, method, fill_value, copy 5362 ).__finalize__(self, method="reindex") File ~/anaconda3/lib/python3.10/site-packages/pandas/core/generic.py:5375, in NDFrame._reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy) 5372 continue 5374 ax = self._get_axis(a) -> 5375 new_index, indexer = ax.reindex( 5376 labels, level=level, limit=limit, tolerance=tolerance, method=method 5377 ) 5379 axis = self._get_axis_number(a) 5380 obj = obj._reindex_with_indexers( 5381 {axis: [new_index, indexer]}, 5382 fill_value=fill_value, 5383 copy=copy, 5384 allow_dups=False, 5385 ) File ~/anaconda3/lib/python3.10/site-packages/pandas/core/indexes/base.py:4274, in Index.reindex(self, target, method, level, limit, tolerance) 4271 raise ValueError("cannot handle a non-unique multi-index!") 4272 elif not self.is_unique: 4273 # GH#42568 -> 4274 raise ValueError("cannot reindex on an axis with duplicate labels") 4275 else: 4276 indexer, _ = self.get_indexer_non_unique(target) ValueError: cannot reindex on an axis with duplicate labels

답변을 작성해보세요.
3

박조은
지식공유자2023.06.04
안녕하세요. 라이브러리 버전에 업데이트 되며 중복된 index 때문에 발생하는 오류입니다.
data=df.reset_index(drop=True) <= 여기에서처럼 인덱스를 초기화 하고 drop=True 로 기존 인덱스를 삭제하도록 하면 잘 동작합니다. drop=True 는 안 해주셔도 무방하나, 데이터프레임을 재사용하고자할 때 drop=True 로 사용하는 것을 권장합니다.
sns.swarmplot(data=df.reset_index(drop=True), x="연도", y="평당분양가격", hue="지역명", size=1)안내가 부족했던점 사과드립니다.
감사합니다 :)

답변 1