
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
미해결
MDP 행동가치함수에 대한 문의 입니다.
21.08.10 12:41 작성 조회수 226
0

제일 아래 쪽 ? 부분이 정의에 의한 부분이 맞는 건지요?
설명하실때 왼쪽은 행동에 대한 합을 나타내고 오른쪽은 하나의 행동에 대해서라고 강의를 하셨는데 이 부분이 이해가 가질 않습니다.

답변을 작성해보세요.
0

멀티코어
지식공유자2021.08.11
안녕하세요 강석원님.
제가 질문을 정확히 이해하지 못해 나름의 방식으로 답변을 드리겠습니다.
결론부터 말씀드리자면 강석원님이 말씀하신 마지막 수식은 틀린 수식입니다.
MDP에서 정책, 가치함수, 행동가치함수를 이해하는 것이 생각보다 좀 어렵습니다.
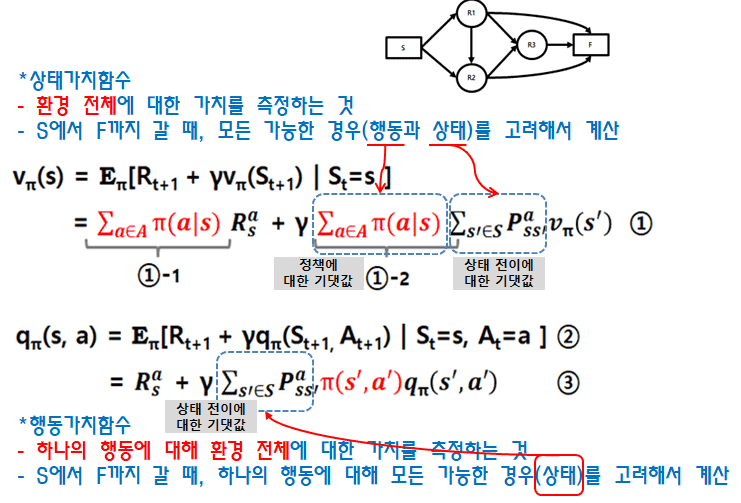
상태가치함수는 환경 전체에 대한 가치를 측정합니다. 라우팅 그림을 참고하시면 에이전트가 S에서 F까지 갈 때 취할 수 있는 모든 행동과 갈 수 있는 모든 상태를 고려해야 합니다. 그래서 수식 (1)-2에서 상태이동에 대한 확률P와 행동에 대한 확률 ㅠ(정책)을 모두 고려한 확률의 기대값을 구합니다.
반면 행동가치함수는 하나의 행동에 대한 가치를 측정합니다. 행동가치함수는 하나의 행동만을 고려하기 때문에 상태가치함수와 달리 모든 행동을 고려할 필요가 없이 하나의 행동만을 고려하면 됩니다.
이 개념을 가지고 수식을 다시 보시면 이해가 좀 더 쉽습니다.
감사합니다.

답변 1