





![[PyTorch] 쉽고 빠르게 배우는 딥러닝강의 썸네일](https://cdn.inflearn.com/public/courses/324742/course_cover/96781b94-7bae-47f8-ab6f-42821f26f042/coco-pytorch.png?w=420)
[PyTorch] 쉽고 빠르게 배우는 딥러닝
코코
딥러닝의 기본 뼈대인 MLP부터 CNN, RNN까지 쉽고 빠르게 배워봅니다.
중급이상
딥러닝, 인공신경망, PyTorch




롯데쇼핑 이커머스사업본부
임직원들도 이 강의를 듣고 있어요!
롯데쇼핑 이커머스사업본부
임직원들도 이 강의를 듣고 있어요!
먼저 경험한 수강생들의 후기
5.0
djchoi
유익한 강의 입니다
5.0
나경태
좋습니다 좋아요
5.0
plsch
잘 들었습니다.
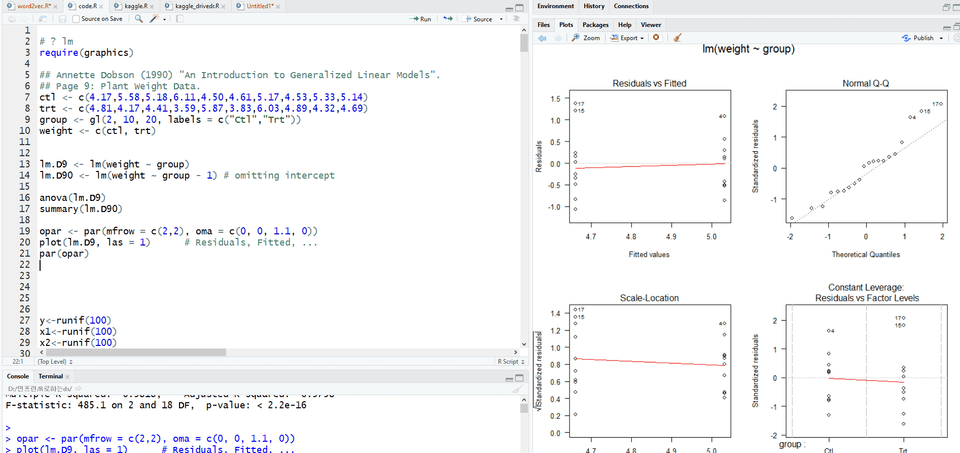
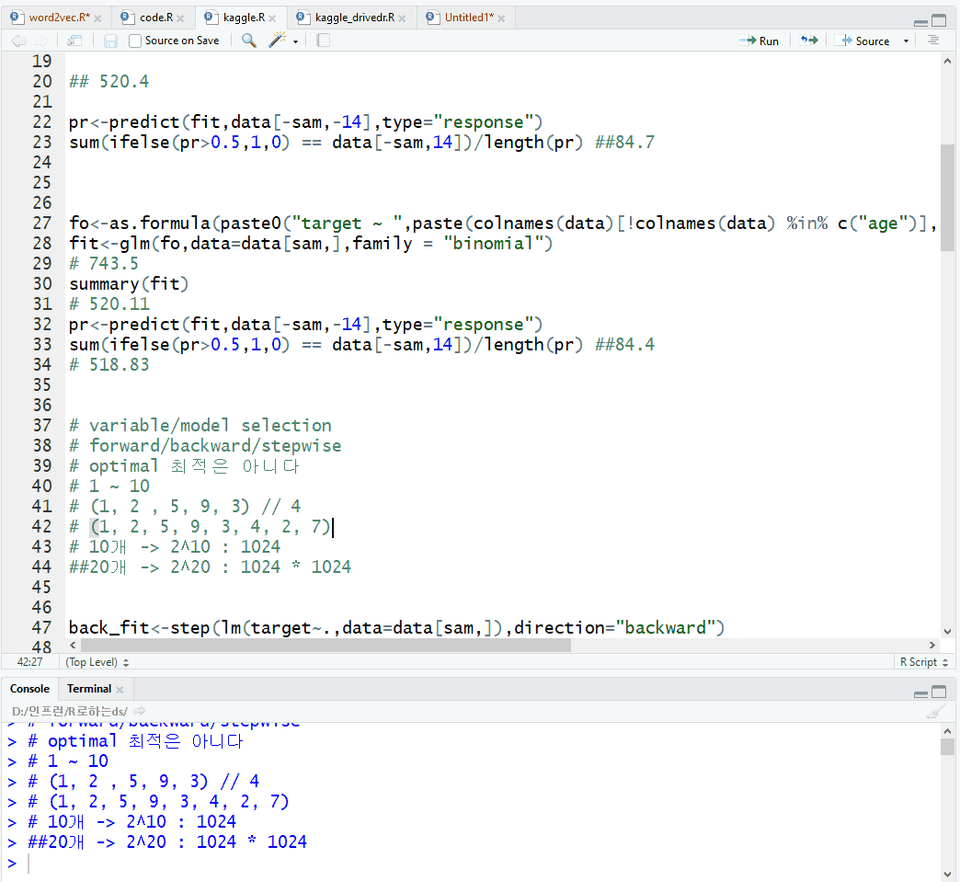
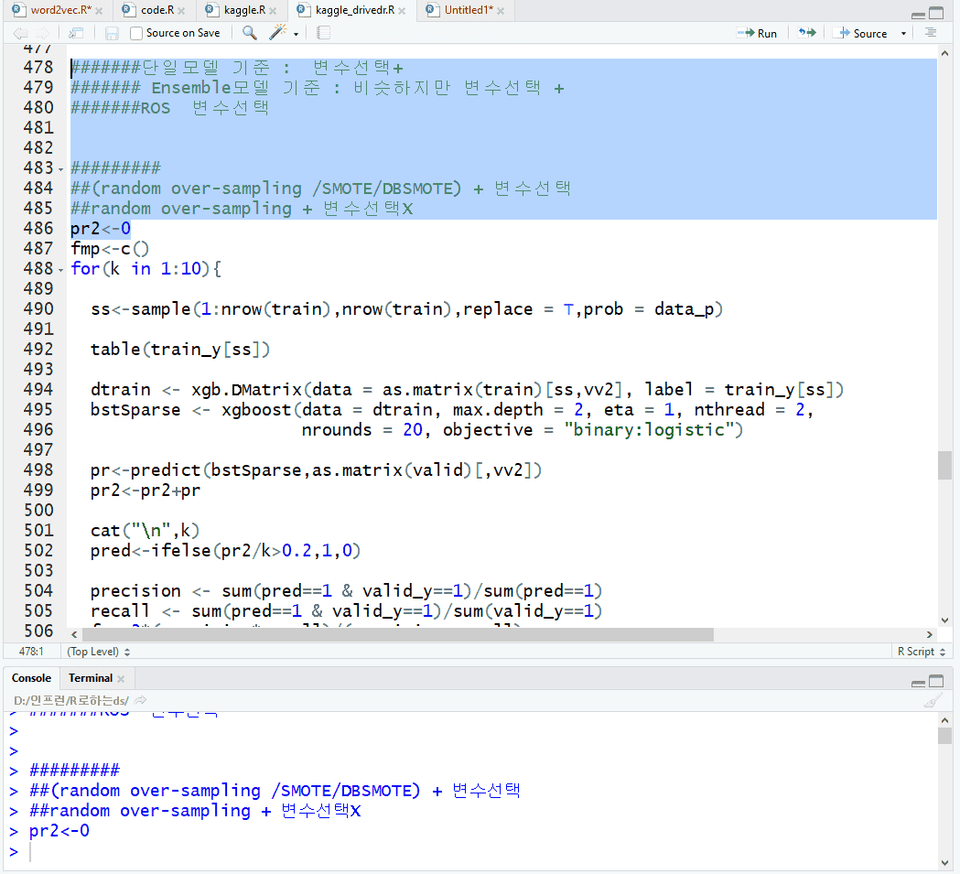
R로 머신러닝 모델 적합 시키는 법
머신러닝 모델 성능 늘리는 법
🙆🏻♀ R을 통해 무작정 datascience를 해보는 강의입니다.
데이터를 불러오는 것부터 모델 구축 및 모델 성능 전략까지 한줄한줄 쳐보면서 배웁니다..🙆🏻♂
이 강의는 이론보다 실습에 초점이 맞춰져 있는 강의입니다.
R에 대한 기본적인 지식과 머신러닝에 대한 전반적인 지식이 있으셔야 합니다.
R도 배웠고, 머신러닝도 배웠는데 데이터 분석을 할 줄 모르시나요?
이 강의는 데이터 입력부터 머신러닝 모델 구축 및 모델 성능 향상 전략까지 직접 한 줄 한 줄 코드를 쳐보면서 배우는 강의입니다.
Q. R을 어느 정도 할 줄 알아야 하나요?
A. 기본적으로 데이터를 불러들이고 전처리할 줄 아셔야 합니다. R프로그래밍 기초 강의는 필수로 수강을 하셔야 하며, 중급강의는 선택사항입니다.
Q. 머신러닝과 통계학은 어느 정도 알아야 하나요?
A. 기초적인 통계학(t.test/anova 등, 학부 교양수업 수준)을 알고 계시고, 머신러닝에 대한 이론적인 지식(학부 전공 수업 수준)이 있으셔야 듣기 수월하십니다.
학습 대상은
누구일까요?
통계학도 배웠고 머신러닝도 배웠는데 실전경험이 없으신 분
여러 머신러닝 모델을 적합해보고 싶으신 분
선수 지식,
필요할까요?
R에 대한 전반 적인 지식
통계학과 머신러닝 기초
8,488
명
수강생
522
개
수강평
136
개
답변
4.4
점
강의 평점
20
개
강의
학부에서는 통계학을 전공하고 산업공학(인공지능) 박사를 받고 여전히 공부중인 백수입니다.
수상
ㆍ 제6회 빅콘테스트 게임유저이탈 알고리즘 개발 / 엔씨소프트상(2018)
ㆍ 제5회 빅콘테스트 대출 연체자 예측 알고리즘개발 / 한국정보통신진흥협회장상(2017)
ㆍ 2016 날씨 빅데이터 콘테스트/ 기상산업 진흥원장상(2016)
ㆍ 제4회 빅콘테스트 보험사기 예측 알고리즘 개발 / 본선진출(2016)
ㆍ 제3회 빅콘테스트 야구 경기 예측 알고리즘 개발 / 미래창조과학부 장관상(2015)
* blog : https://bluediary8.tistory.com
주로 연구하는 분야는 데이터 사이언스, 강화학습, 딥러닝 입니다.
크롤링과 텍스트마이닝은 현재는 취미로 하고있습니다 :)
크롤링을 이용해서 인기있는 커뮤니티 글만 수집해서 보여주는 마롱이라는 앱을 개발하였고
전국의 맛집리스트와 블로그를 수집해서 맛집 추천 앱도 만들었었죠 :) (시원하게 말아먹..)
지금은 인공지능을 연구하는 박사과정생입니다.
전체
32개 ∙ (7시간 23분)
해당 강의에서 제공:
전체
6개
3.8
6개의 수강평
지식공유자님의 다른 강의를 만나보세요!
같은 분야의 다른 강의를 만나보세요!
![[PyTorch] 쉽고 빠르게 배우는 NLP강의 썸네일](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)

![[PyTorch] 쉽고 빠르게 배우는 GAN강의 썸네일](https://cdn.inflearn.com/public/courses/324945/course_cover/9794a376-0e54-4745-8a1d-3c6fe72b8fe6/pytorch-gan-eng.png?w=420)






![[R로 하는] 머신러닝을 위한 통계학 기초강의 썸네일](https://cdn.inflearn.com/public/courses/325155/course_cover/d8120723-26f7-4fcc-a25c-a99eef4ea0f6/machine-learning-statistics-r-eng.png?w=420)
![[R] KOSPI/KOSDAQ 전 종목 데이터 수집 및 관리강의 썸네일](https://cdn.inflearn.com/public/courses/324972/course_cover/36468a43-de3b-461b-af55-f3c7b0e51637/kospi-kosdaq-data-eng-1.png?w=420)












