






Mastering Harness Engineering
arigaram
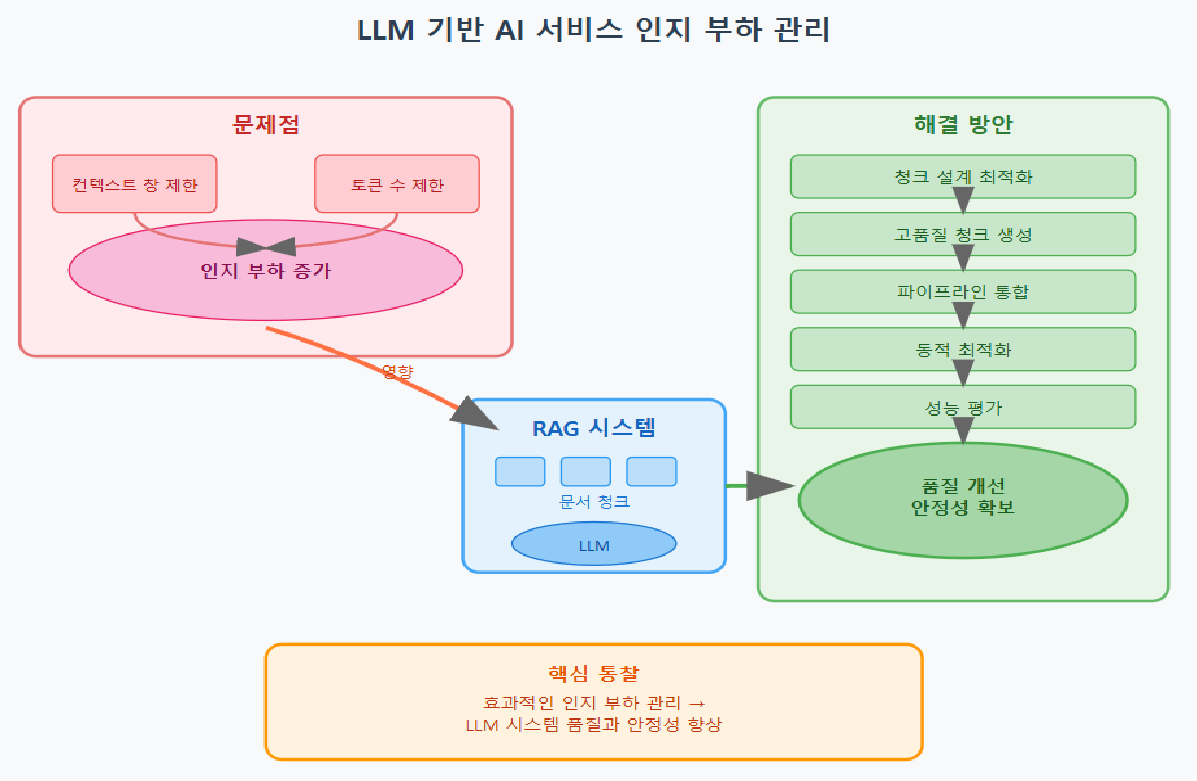
Moving beyond prompt engineering and context engineering, we are now entering the era of harness engineering. Harnesses can solve LLM-based challenges that are difficult to achieve with prompts and RAG alone.
Intermediate
harness





















![[LLM 101] Llama SFT Tutorial for LLM Beginners (feat. ChatApp Poc)Course Thumbnail](https://cdn.inflearn.com/public/files/courses/333429/cover/01k09qxkkwjcrqe886az6rr63t?w=420)




![[Practical AIoT] Perfect Preparation for Smart Mirror Makerthon: LLM, CV, and Hardware DesignCourse Thumbnail](https://cdn.inflearn.com/public/files/courses/340196/cover/01kexgfr26whtfsmsqd2dj1x7x?w=420)
![Just 1 hour! Creating 'My Own AI Senior Developer' to install on my computer (Antigravity Vibe Coding) [Source code provided]Course Thumbnail](https://cdn.inflearn.com/public/files/courses/340332/cover/ai/3/e87ee52b-1099-42db-a384-64ab8c725470.png?w=420)
![[AI Cheat Sheet] The secret to finishing work instantly, Agentic AICourse Thumbnail](https://cdn.inflearn.com/public/files/courses/340717/cover/ai/1/3b5cb844-25b5-4576-8224-d293d0989376.png?w=420)





