









![[VLM101] Building a Multimodal Chatbot with Fine-tuning (feat.MCP / RunPod)Course Thumbnail](https://cdn.inflearn.com/public/files/courses/337551/cover/01jzjdkw9evbt245h3w2mdfs2r?w=420)
[VLM101] Building a Multimodal Chatbot with Fine-tuning (feat.MCP / RunPod)
dreamingbumblebee
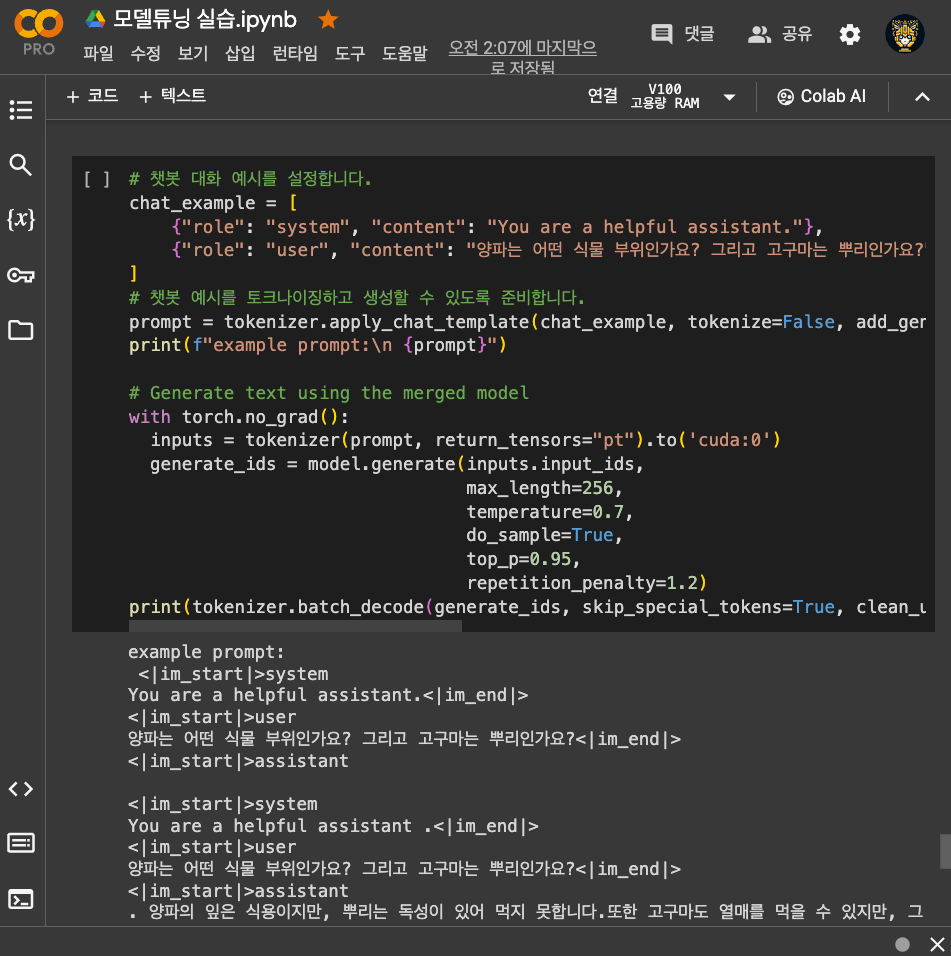
This is an introductory course for understanding the concept and application methods of Vision-Language Models (VLM), and practicing running the LLaVA model in an Ollama-based environment while integrating it with MCP (Model Context Protocol). This course covers the principles of multimodal models, quantization, service development, and integrated demo development, providing a balanced mix of theory and hands-on practice.
Basic
Vision Transformer, transformer, Llama




![[PyTorch] Learn NLP easily and quicklyCourse Thumbnail](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)
![[Practical AIoT] Perfect Preparation for Smart Mirror Makerthon: LLM, CV, and Hardware DesignCourse Thumbnail](https://cdn.inflearn.com/public/files/courses/340196/cover/01kexgfr26whtfsmsqd2dj1x7x?w=420)









![Just 1 hour! Creating 'My Own AI Senior Developer' to install on my computer (Antigravity Vibe Coding) [Source code provided]Course Thumbnail](https://cdn.inflearn.com/public/files/courses/340332/cover/ai/3/e87ee52b-1099-42db-a384-64ab8c725470.png?w=420)



