




Data Augmentation 관련
1261
작성한 질문수 6
안녕하세요 선생님
항상 좋은강의 잘 듣고있습니다.
대학원생활에 정말 많은 도움 받고 있어요 ㅎㅎ
수업을 듣던 중 궁금한점이 생겨서 질문 남깁니다.
Q1. Config의 이해 - Data Pipeline 수업을 듣고 적용해보던 중 default로 적용되어있는 Augmentation기법들(Resize, RandomFlip, Normalize, Pad) 말고 mmdetection에서 제공하는 다른 transform 함수를 적용해보려 합니다.
https://mmdetection.readthedocs.io/en/latest/_modules/mmdet/datasets/pipelines/transforms.html
위 주소에 나온 Cutout, Mosaic, Mixup를 적용하고 싶은데 아래 사진과 같이 coco_instance.py 파일에 저렇게 추가하면 적용될까요?
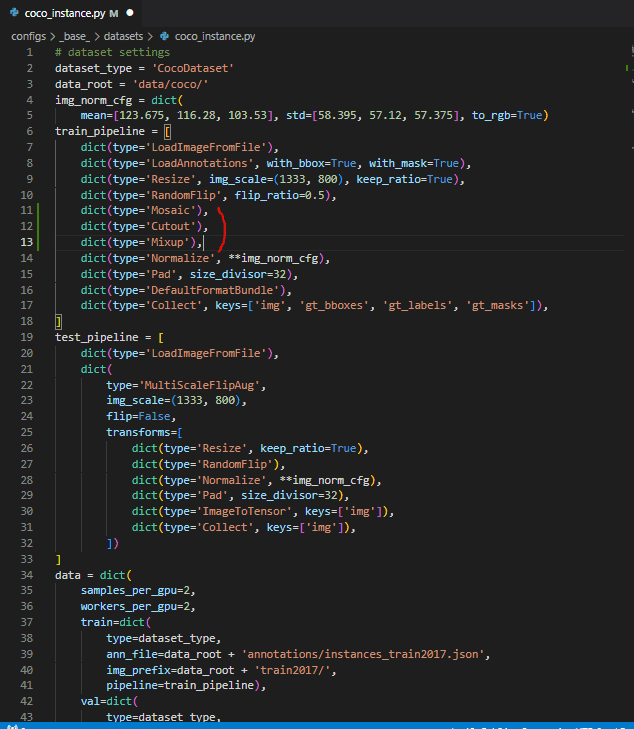
Q2. data augmentation을 적용했을 때 데이터가 얼만큼 늘어나는지 어떻게 아나요?
제 데이터가
train:80장
val:20장
이렇게 구성되어있는데 얼만큼 늘어나는지(ex, augmentation적용 후 300장) 궁금합니다!
답변 3
0
mmdet의 yolox_s, yolox_tiny config를 확인하면 Mosaic, MixUp 적용 예시를 확인할 수 있습니다. 필요한 분들 참고하시면 좋을 듯합니다.
0
안녕하세요 업데이트가 늦었습니다.. ㅎㅎ
Data Augmentation에 Mosaic을 적용하기 위해서는 train_dataset 파이프라인에
MultiImageMixDataset을 같이 사용 해야 합니다.
방법은 아래와 같습니다.
# Open configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py directly and add the following fields
data_root = 'data/coco/'
dataset_type = 'CocoDataset'
img_scale=(1333, 800)
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='Mosaic', img_scale=img_scale, pad_val=114.0),
dict(
type='RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)), # The image will be enlarged by 4 times after Mosaic processing,so we use affine transformation to restore the image size.
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
train_dataset = dict(
_delete_ = True, # remove unnecessary Settings
type='MultiImageMixDataset',
dataset=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
],
filter_empty_gt=False,
),
pipeline=train_pipeline
)
data = dict(
train=train_dataset
)
감사합니다.
0
안녕하십니까,
오, mmdetection이 Mosaic과 MixUp이 되는 군요. 저도 모르고 있었습니다.
MixUp은 type='Mixup' 아닐까 싶습니다.
아래 URL도 참조해 보시지요.
https://cake.tistory.com/38?category=498558
수행해 보시고 결과도 update 부탁드립니다.
MMDetection 버전 이슈
0
80
2
강의 환경설정 질문
0
81
2
Custom Dataset에서의 polygon 정보 관련
0
127
3
cvat.ai 보안 수준이 궁금합니다
0
118
2
캐클 nucleus 챌린지 runpod 실습 코드 에러 질문드립니다.
0
135
3
추론 결과의 Precision(또는 mAP) 평가 방법
0
115
2
mmdetection mask rcnn inferenct 실습 시 runpod 템플릿 관해서 질문드립니다.
0
82
2
runpod에서 google drive 연결 시 오류 발생
0
139
2
로드맵 선택
0
87
1
mmcv
0
79
2
Anchor box의 Positive 처리 위치
0
83
2
해당 강의 runpod 적용 후 에러 제보드립니다
0
122
2
run pod credit 관련 제보
0
153
2
mmdetection 2.x과 3.x 호환 관련 표기
0
104
2
mm_faster_rcnn_train_kitti.ipynb 실행 오류
0
133
3
질문 드립니다.
0
105
3
mm_faster_rcnn_train_coco_bccd 실행 오류 질문드립니다.
0
107
1
강사님께 수정을 제안드리고 싶은 것이 있습니다.
0
114
1
google automl efficientdet 다운로드 및 설치 오류
0
99
1
이상 탐지에 사용할 비전 기술 조언 부탁드립니다.
0
130
2
OpenCV 관련 질문드립니다.
0
97
2
mmcv 설치관련해서 문의드려요
0
391
3
강의 구성 관련해서 질문이 있습니다
1
154
2
모델 변환 성능 질문드립니다.
0
133
1