Khóa học Kỹ thuật dữ liệu (1): Cài đặt trực tiếp Big Data Hadoop
Những sinh viên muốn tìm hiểu Hadoop và dữ liệu lớn sẽ ăn mừng những tiến bộ đáng kinh ngạc mà họ đã đạt được khi trải nghiệm thế giới dữ liệu lớn thông qua khóa học này!
Khóa học này được tạo ra với mục tiêu đào tạo các chuyên gia Hadoop xử lý dữ liệu lớn. Thay vì sử dụng ứng dụng Phần mềm phân phối tại chỗ (OPD) toàn diện như Cloudera, chúng tôi sẽ cài đặt Hadoop từ đầu và hướng dẫn bạn qua các bước trích xuất, di chuyển và tải tập dữ liệu. Hadoop, bắt đầu từ phiên bản 1.
5.0
상냥한 날다람쥐
100% đã tham gia
công lao:
Bạn có thể tìm hiểu những kiến thức cơ bản về Hadoop MapReduce.
Có vẻ như đây là bài giảng Hadoop duy nhất bằng tiếng Hàn.
Thất vọng:
Sử dụng hai trình ánh xạ để trích xuất bằng một khóa chung
Khi sử dụng hai phím
Cách tự thiết lập bộ so sánh
Thật đáng thất vọng khi không có điều gì khiến tôi tò mò.
điều bất lợi:
Người hướng dẫn phát âm tiếng Hàn không rõ ràng, nhạc nền thì to nên tôi phải nghe lại nhiều lần.
------------------------------
Sau khi xem phản hồi của thầy sẽ sửa lại thành 5 sao.
5.0
김태경
59% đã tham gia
Tốt cho người mới bắt đầu sử dụng Hadoop. Tôi nghĩ nó hoàn hảo để nghiên cứu trước khi đọc sách.
Bạn sẽ nhận được điều này sau khi học.
Trải nghiệm công nghệ dữ liệu lớn trong cuộc sống hàng ngày
Xử lý dữ liệu lớn với Hadoop
Tìm hiểu công nghệ xử lý phân tán để xử lý dữ liệu lớn với Hadoop
Xử lý dữ liệu lớn của Hadoop bằng ngôn ngữ Java
Tìm hiểu các kỹ thuật để khắc phục những hạn chế của việc xử lý dữ liệu quan hệ với Hadoop
Tìm hiểu các dự án và giao diện khác nhau của Hadoop
Đây là thời đại của dữ liệu lớn! 👨💻 Trở thành chuyên gia với Hadoop.
Trung tâm của khoa học dữ liệu, Hadoop đang là xu hướng!
Nhiều tập đoàn CNTT lớn, các dịch vụ truyền thông xã hội và nhiều công ty khác đang cạnh tranh để sử dụng Hadoop (Apache Hadoop) cho việc phân tích và xử lý dữ liệu lớn. Hadoop là một nền tảng dựa trên Java được thiết kế để xử lý lượng dữ liệu khổng lồ với chi phí thấp, cho phép lưu trữ và xử lý phân tán các tập dữ liệu lớn. Nhưng điều gì sẽ xảy ra nếu bạn có thể đạt đến trình độ chuyên gia dữ liệu lớn thông qua Hadoop?
Thông qua phân tích dữ liệu, các công ty sẽ có thể tiên phong trong các thị trường mới, tạo ra giá trị độc đáo và mang đến cho người tiêu dùng mới cảm giác thích thú khi được tiếp cận thông tin thiết yếu theo thời gian thực. Dữ liệu lớn cũng là một kỹ năng quan trọng đối với các doanh nghiệp vừa và nhỏ, vì vậy đây là tin đáng mừng cho những ai đang tìm kiếm việc làm hoặc thay đổi nghề nghiệp trong lĩnh vực dữ liệu lớn .
BigData với Hadoop
Google, Yahoo, Facebook, IBM, Instagram, Twitter, v.v. Nhiều công ty đang sử dụng nó để phân tích dữ liệu. Thông qua Hadoop, một giải pháp dữ liệu lớn tiêu biểu Hãy xây dựng một cơ sở hạ tầng hệ thống phân tán dữ liệu lớn .
Khóa học này bắt đầu bằng việc tìm hiểu thuật ngữ dữ liệu lớn và sau đó cung cấp trải nghiệm gián tiếp về cách xử lý dữ liệu lớn bằng phần mềm nguồn mở Hadoop . Thông qua khóa học này, sinh viên sẽ đồng thời trải nghiệm thế giới công nghệ dữ liệu lớn và Cuộc cách mạng Công nghiệp lần thứ tư.
Hadoop là gì?
Hadoop là phần mềm mã nguồn mở mà bất kỳ ai cũng có thể sử dụng miễn phí. Trong bài giảng này, chúng ta sẽ tìm hiểu về dữ liệu lớn bằng Hadoop phiên bản 3.2.1 .
Hiểu về dữ liệu lớn Cách sử dụng Hadoop Được ngay.
Dữ liệu lớn Về thuật ngữ Hiểu biết thiết yếu
Hadoop của Trong khái niệm và sử dụng Giới thiệu về Hàn Quốc
Thông qua Hadoop Xử lý dữ liệu lớn Hướng dẫn học tập
Tôi giới thiệu điều này tới những người này!
Tất nhiên, những người không phù hợp với danh mục này cũng được chào đón. (Người mới bắt đầu được chào đón gấp đôi ✌)
Việc làm/Thay đổi công việc CNTT tương lai đang được xem xét Những người khao khát theo đuổi ngành khoa học dữ liệu
Thông qua Java/Python Tôi muốn xử lý dữ liệu lớn Những người làm điều đó
Với sự quan tâm và tò mò Về dữ liệu lớn Bất cứ ai muốn trải nghiệm nó
Phiên bản Hadoop 3.x Môi trường dữ liệu, v.v. Nhân viên văn phòng muốn trải nghiệm
Trước khi tham gia lớp học, vui lòng kiểm tra lại kiến thức của bạn!
Kiến thức tiên quyết là kiến thức cơ bản về ngôn ngữ lập trình Java , kiến thức về dữ liệu lớn và thuật ngữ liên quan đến máy ảo/bộ dữ liệu và hiểu biết cơ bản về Linux Ubuntu .
Nội dung sau đây Tôi đang học.
1. Hiểu các thách thức về công nghệ ảo hóa và hệ điều hành khách
Chúng ta sẽ tìm hiểu công nghệ ảo hóa, một lợi thế cho việc hợp nhất máy chủ, và cách cô lập nhiều máy chủ với một hệ điều hành duy nhất thông qua ảo hóa cấp hệ điều hành. Bất kỳ ai cũng có thể đảm nhận thử thách tạo và vận hành một số lượng lớn máy chủ bằng Ubuntu, một giải pháp mã nguồn mở hỗ trợ ảo hóa Linux. Hơn nữa, chúng ta sẽ có được kiến thức về hệ điều hành khách và tích lũy kinh nghiệm kỹ thuật sâu rộng trong việc phân phối dữ liệu lớn trên nhiều máy chủ. Sử dụng ảo hóa máy chủ, bạn có thể trải nghiệm nhiều hệ điều hành chạy trên một máy chủ vật lý hoặc hệ điều hành duy nhất trong một máy ảo hiệu suất cao.
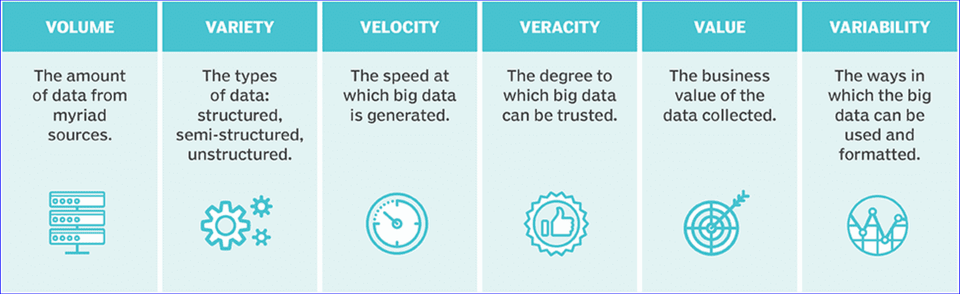
Tìm hiểu về định nghĩa của Dữ liệu lớn và các ứng dụng thực tế của nó.
Hãy cùng tìm hiểu thuật ngữ liên quan đến Hadoop, phần mềm xử lý dữ liệu được các doanh nghiệp ưa chuộng.
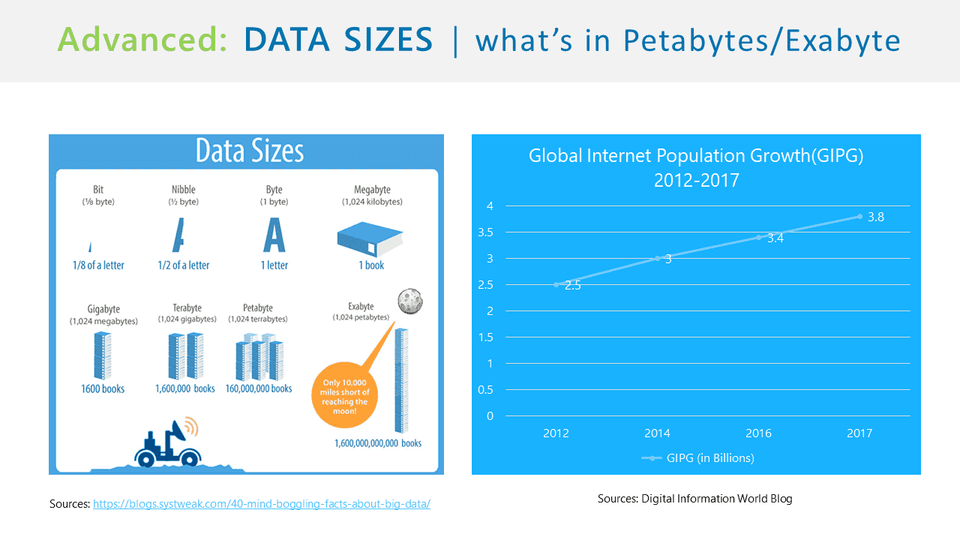
Kích thước dữ liệu
Bối cảnh: Dữ liệu lớn
2. Cách cài đặt Hadoop trên Ubuntu 20.04 LTS và sử dụng lệnh
Chúng tôi sẽ đề cập đến những kiến thức cơ bản về cách sử dụng các công cụ Linux CLI (Giao diện Dòng lệnh) mà các nhà phát triển front-end thường gặp khi phát triển ứng dụng web, sau đó chuyển đổi liền mạch sang Linux terminal cho Hadoop. Hơn nữa, chúng tôi sẽ đề cập đến những kiến thức cơ bản về sử dụng Ubuntu trong môi trường GUI không phải Windows, vượt ra ngoài phạm vi hiểu biết cơ bản về các hệ thống Linux như tệp cấu hình shell và hướng đến trình độ trung cấp.
Hãy cùng cài đặt và thiết lập Linux (Ubuntu 20.04 LTS) dưới dạng máy ảo trên máy tính xách tay chạy Windows 10.
Cài đặt Hadoop phiên bản 3.2.1 trên máy ảo Linux.
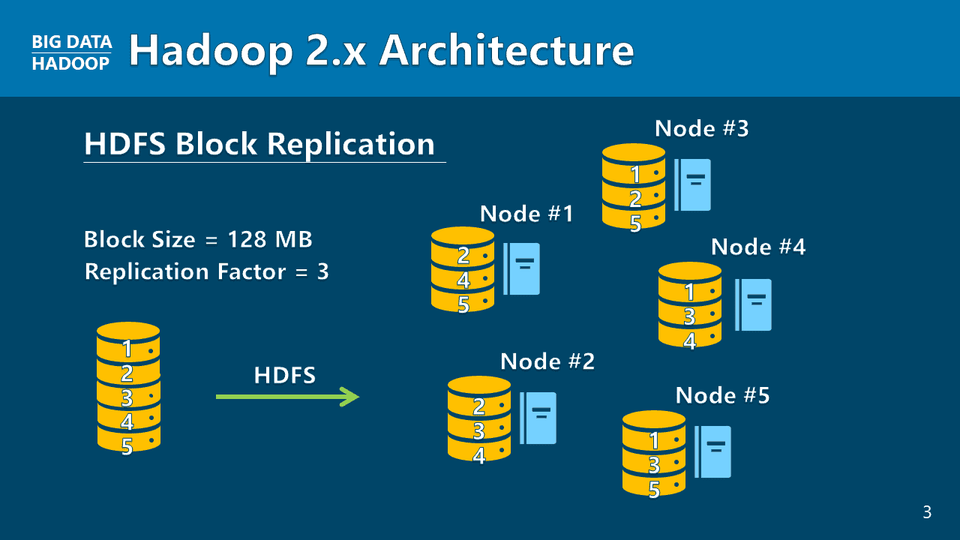
Kiến trúc Hadoop 2.x
Hadoop 2.x so với 3.x
3. Hướng dẫn định hướng mới nhất của Hadoop 3.2.1 & Hiểu về cấu trúc kiến trúc cốt lõi
Điểm khởi đầu cho việc xử lý dữ liệu lớn trên dữ liệu phi cấu trúc là tìm hiểu Hệ thống Tệp Phân tán Hadoop (HDFS), một mô hình hệ thống tệp của Google, MapReduce và YARN để mở rộng cụm và quản lý tài nguyên. Chúng ta sẽ lần lượt xem xét cấu trúc kiến trúc của Hadoop phiên bản 1, 2 và 3, cung cấp cho sinh viên cái nhìn trực quan về lịch sử công nghệ Hadoop.
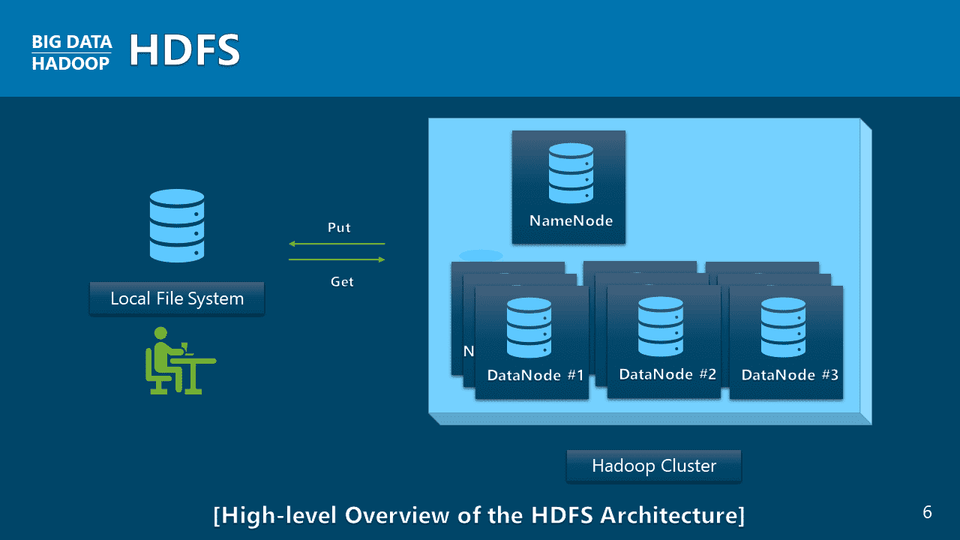
Hiểu và tích hợp với Hệ thống tệp phân tán Hadoop (HDFS).
Hiểu các nguyên tắc của khung Map/Reduce và phân tích dữ liệu dựa trên nguyên tắc đó.
Kiến trúc HDFS
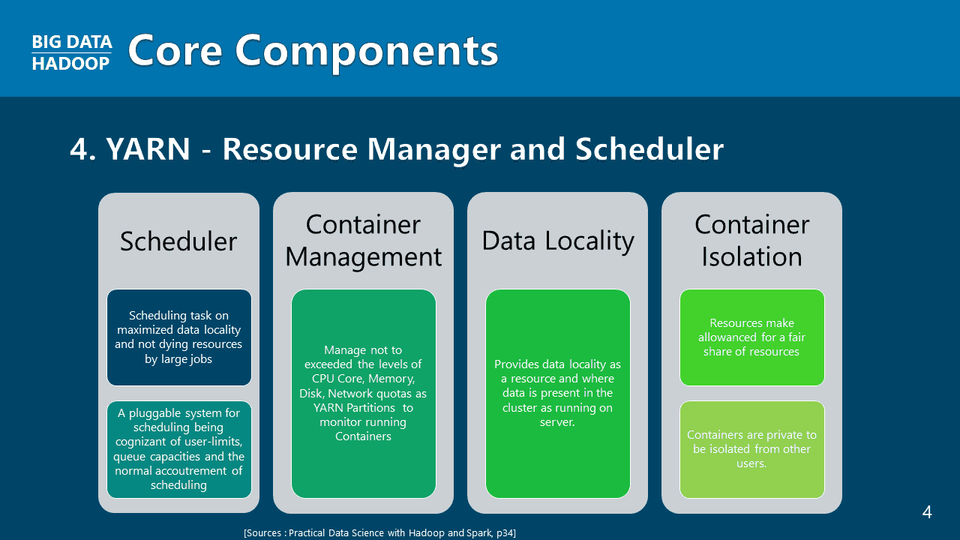
Các thành phần cốt lõi của YARN
4. Hướng dẫn vận hành HDFS Shell và xây dựng ứng dụng MapReduce bằng Java/Python
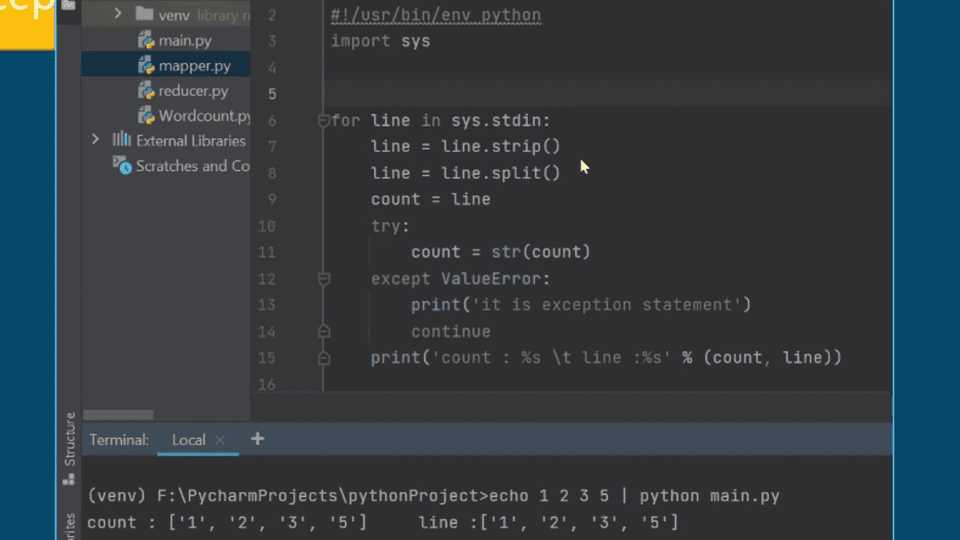
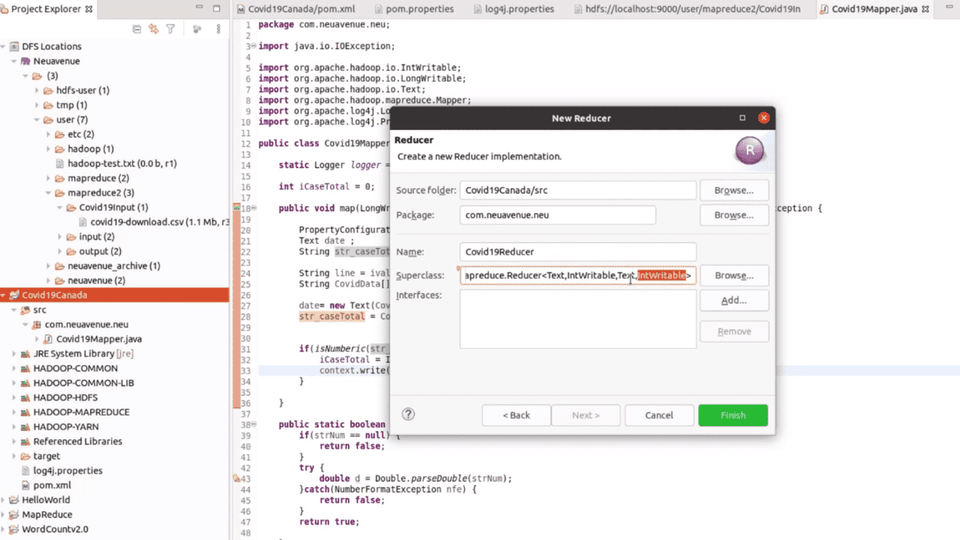
Mặc dù các kỹ thuật xử lý dữ liệu có thể khác nhau, nền tảng của phân tích dữ liệu lớn nằm ở việc xây dựng các ứng dụng MapReduce. Từ một ứng dụng MapReduce đếm từ cơ bản bằng Python đến một ứng dụng COVID-19 được xây dựng bằng Java dựa trên Eclipse, việc xây dựng nhiều ứng dụng MapReduce dữ liệu lớn không còn là một lựa chọn nữa; đó là một bước tiến cần thiết.
Hãy kết nối Hadoop với Java và triển khai một ứng dụng.
Hãy kết nối Hadoop với Python và triển khai một ứng dụng.
Ứng dụng Map/Reduce WordCount của Python
Ứng dụng Java Map/Reduce WordCount
Câu hỏi dự kiến Hỏi & Đáp!
H. Dữ liệu lớn là gì? Có cần thiết phải định nghĩa dữ liệu lớn khi sử dụng Hadoop không?
Vâng, tất nhiên, khi làm việc với Hadoop, bạn cần có định nghĩa ngắn gọn và hiểu biết về dữ liệu lớn. Tất nhiên, điều này không đòi hỏi sự hiểu biết đầy đủ và chuyên sâu. Tuy nhiên, nó đòi hỏi một mức độ hiểu biết cần thiết để làm việc với Hadoop.
Dữ liệu lớn liên quan đến việc xử lý các tập dữ liệu cực lớn bằng công cụ Hadoop. Các tập dữ liệu này đóng vai trò là nền tảng để phân tích nhiều mô hình và xu hướng khác nhau trên nhiều doanh nghiệp. Chúng liên quan chặt chẽ đến hành vi xã hội, mô hình của con người và việc tạo ra giá trị thông qua tương tác.
H. Hadoop là gì? Các thành phần của nó là gì? Hadoop stack là gì?
Dữ liệu từ các trang mạng xã hội quy mô lớn, từ terabyte đến petabyte (Zettabyte)Hadoop đang hỗ trợ sứ mệnh này. Hadoop Stack là một nền tảng mã nguồn mở để xử lý dữ liệu lớn.
Nói một cách đơn giản, "Hadoop" được gọi là "ngăn xếp Hadoop". Hadoop và ngăn xếp Hadoop giúp bạn xây dựng các cụm bằng phần cứng phổ thông, giá rẻ và xử lý quy mô lớn trong các cụm máy chủ khổng lồ này. Ngăn xếp Hadoop, còn được gọi là "xử lý hàng loạt đơn giản", là một "nền tảng điện toán phân tán" dựa trên Java. Nó cho phép người dùng xử lý hàng loạt dữ liệu tùy ý, định kỳ, phân phối dữ liệu theo định dạng mong muốn để tạo ra kết quả.
H. Có cần kiến thức lập trình không?
Ngay cả khi bạn không có kiến thức lập trình hay kinh nghiệm viết code, cũng không sao cả. Tôi giảng dạy với sự hiểu biết sâu sắc về Java và Python, như thể bạn đang trải nghiệm chúng lần đầu tiên. Mặc dù tài liệu bài giảng bằng tiếng Anh, tôi sẽ giảng bằng tiếng Hàn để đảm bảo bạn có thể theo dõi mà không gặp bất kỳ khó khăn nào. Tuy đôi khi tôi có giải thích bằng tiếng Anh, nhưng tôi tin rằng bất kỳ ai có trình độ trung học phổ thông đều có thể hiểu được. (Giống như tôi đã đạt được ước mơ của mình, ngay cả khi trình độ tiếng Anh của tôi còn hạn chế.)
H. Dữ liệu lớn có liên quan gì đến Hadoop?
Khóa học này tự nhiên bao gồm Hadoop. Không chỉ giới hạn ở các hệ quản trị cơ sở dữ liệu quan hệ (RDMS) đơn giản như Oracle, MSSQL hoặc MySQL, khóa học còn hướng đến việc giải quyết các yêu cầu kinh doanh thiết yếu, bắt đầu từ xử lý quy mô lớn, tốc độ xử lý dữ liệu và hiệu quả chi phí. Cụ thể, Hadoop không chỉ xử lý dữ liệu có cấu trúc—dữ liệu quan hệ được xử lý bởi các hệ quản trị cơ sở dữ liệu quan hệ dạng hàng và cột—mà còn cả dữ liệu phi cấu trúc, chẳng hạn như hình ảnh, âm thanh và các tệp xử lý văn bản.
Khi xử lý dữ liệu cấu trúc dịch vụ, chúng ta đang nói đến dữ liệu liên quan đến giao tiếp và tích hợp dữ liệu với máy chủ web, chẳng hạn như email, CSV, XML và JSON. HTML, trang web và cơ sở dữ liệu NoSQL cũng được bao gồm. Tất nhiên, việc tích lũy các tập dữ liệu được sử dụng để xử lý việc chuyển giao tài liệu kinh doanh từ máy tính sang máy tính, được gọi là EDI, cũng thuộc loại này.
Khóa học này sẽ hướng dẫn người dùng cài đặt Hadoop 3.2.1 trên Ubuntu 20.04 LTS. Ngay cả khi bạn chưa từng có kinh nghiệm về Unix hoặc Linux, bạn vẫn sẽ được học các kỹ thuật cài đặt và hệ điều hành Linux. Ngoài những kiến thức cơ bản về CLI và ngôn ngữ người dùng của Hadoop, khóa học này cũng sẽ giúp bạn làm quen với các công nghệ DFS và MapReduce độc quyền của Google. Kiến thức của bạn về YARN sẽ chỉ giới hạn ở lý thuyết cơ bản. Chúng tôi dự kiến sẽ cung cấp một bài học chuyên sâu hơn về YARN khi bạn cài đặt một cụm trong khóa học Hadoop 3.3.0 trung cấp.
H. Có lý do gì khiến bạn sử dụng Ubuntu 20.04 LTS làm môi trường thực hành không?
Ubuntu hoàn toàn miễn phí, và chương trình LTS (Dịch vụ Dài hạn) của nó hướng đến các công ty đang tìm kiếm hỗ trợ dịch vụ dài hạn. Bằng cách cài đặt Hadoop trên Linux, bạn có thể tự nhiên xây dựng hệ điều hành và môi trường phát triển phù hợp với nhu cầu kinh doanh của mình. Bằng cách hỗ trợ sử dụng Eclipse và Intelligent trong cùng một môi trường, bạn có thể góp phần hiện thực hóa giấc mơ khoa học dữ liệu, vốn liên quan đến dữ liệu lớn, ngay bây giờ.
Ubuntu là hệ điều hành Windows cho phép cài đặt và vận hành. Môi trường tương tự, tức là GUI (Giao diện người dùng đồ họa) Chúng tôi đang giúp người dùng thông qua môi trường.
Khuyến nghị cho những người này
Khóa học này dành cho ai?
Một sinh viên muốn tìm hiểu những kiến thức cơ bản về dữ liệu lớn từ đầu
Những người khao khát các nguyên tắc và ứng dụng dữ liệu lớn
Những người muốn tìm hiểu Hadoop để xử lý dữ liệu lớn của công ty
Sau khi cả gia đình trở về Hàn Quốc vào tháng 9 năm 2022, tôi đã thực hiện tư vấn TA cho dự án Big Data của Hyundai Motors (từ tháng 9 đến tháng 11 năm 2022), đồng thời đảm nhận vai trò quản lý dự án (PMO) dẫn dắt hệ sinh thái Hadoop, Machine Learning và Deep Learning thông qua quản lý dự án Agile và xây dựng hệ thống Big Data C-ITS. Sau đó, tôi đã làm việc tại đội ngũ Nền tảng Dữ liệu Đổi mới của Bảo hiểm Nhân thọ AIA, sử dụng Azure Data Factory & Azure Databricks với tư cách là một nhà khoa học dữ liệu, cháy hết mình với niềm đam mê và sự nghiên cứu sâu sắc về công nghệ quản lý dữ liệu.
Từ năm 2012 đến năm 2020, tôi là một sinh viên chăm chỉ đã tốt nghiệp chuyên ngành Kỹ thuật Phần mềm (Software Eng. Technician) tại Centennial College, đồng thời là người có 9 năm kinh nghiệm trong lĩnh vực IT tại Hàn Quốc, từng làm việc trong nhiều dự án thuộc lĩnh vực tài chính (tài chính, dự án tài chính và liên quan đến Big Data).
Năm 1999, tôi đã làm tình nguyện viên kỹ thuật mạng tại P.T.S. ở khu vực Dasmarinas, Philippines trong 1 năm, qua đó tích lũy kiến thức về mạng và thế giới IT toàn cầu. Sau khi trở về Hàn Quốc vào năm 2000, tôi đã phát triển hệ thống Warehouse Inventory Control and Management bằng ngôn ngữ Clarion 4GL và PIS Operational Test PCS bằng C/C++ tại K.M.C.
Sau khi hoàn thành khóa học chuyên gia Java tại LG-SOFT SCHOOL vào năm 2001, tôi đã có khoảng 2 năm nghiên cứu và phát triển R&D về e-CRM/e-SFA tại CNMTechnologies, tham gia đa dạng các dự án (Ngân hàng Phát triển Hàn Quốc / Khu phức hợp Chính phủ Daejeon / Dược phẩm Youngjin).
Từ năm 2004 cho đến khi sang Canada vào năm 2012, tôi đã tham gia phát triển và dẫn dắt nhiều dự án như SKT/SK C&C (IMOS), Ngân hàng SC First (TBC), Bảo hiểm Prudential (PFMS), Quản lý tài khoản Bảo hiểm Nhân thọ AXA Kyobo, Tái cấu trúc quản lý tài chính NGM của Ngân hàng Kookmin và nhiều dự án khác.
Sống tại Canada từ cuối năm 2012, với tư cách là một người cha của ba đứa trẻ và là một Scrum Master, tôi là người có kinh nghiệm thực tế tại khu vực Bắc Mỹ và Canada trong việc áp dụng phương thức phát triển Agile để phát triển các ứng dụng tìm thợ sửa chữa (handyman), ứng dụng thương mại điện tử, phát triển sản phẩm và ứng dụng công thức nấu ăn.
Khóa học này được tạo ra với mục tiêu đào tạo các chuyên gia Hadoop xử lý dữ liệu lớn. Thay vì sử dụng ứng dụng Phần mềm phân phối tại chỗ (OPD) toàn diện như Cloudera, chúng tôi sẽ cài đặt Hadoop từ đầu và hướng dẫn bạn qua các bước trích xuất, di chuyển và tải tập dữ liệu. Hadoop, bắt đầu từ phiên bản 1.
công lao:
Bạn có thể tìm hiểu những kiến thức cơ bản về Hadoop MapReduce.
Có vẻ như đây là bài giảng Hadoop duy nhất bằng tiếng Hàn.
Thất vọng:
Sử dụng hai trình ánh xạ để trích xuất bằng một khóa chung
Khi sử dụng hai phím
Cách tự thiết lập bộ so sánh
Thật đáng thất vọng khi không có điều gì khiến tôi tò mò.
điều bất lợi:
Người hướng dẫn phát âm tiếng Hàn không rõ ràng, nhạc nền thì to nên tôi phải nghe lại nhiều lần.
------------------------------
Sau khi xem phản hồi của thầy sẽ sửa lại thành 5 sao.
Cảm ơn bạn đã đánh giá chi tiết của bạn. Lý thuyết về Hadoop rộng lớn đến mức không thể chạm tới mọi thứ. Việc hiểu toàn bộ Hadoop thậm chí còn khó khăn hơn sau khi nghe bài giảng của tôi. Mình đã bỏ nhạc nền và thu âm lại cho giọng rõ hơn, cảm ơn bạn đã tham gia lại khóa học. Ngoài ra còn có các bài giảng được cập nhật, vì vậy tôi hy vọng bạn có thể nghe chúng trong thời gian yên tĩnh và trở thành chuyên gia về Hadoop.
Cảm ơn. MapR là một công nghệ dữ liệu tiên tiến. Tôi biết ơn vì nó đang mang lại những lợi ích tốt. Chúng tôi hy vọng rằng bạn sẽ trở thành nhà điều hành nền tảng dữ liệu lớn đầy cảm hứng bằng cách học riêng các công nghệ hệ sinh thái như Apache Accumulo hoặc HASE Spark. Tôi ghen tị với sự tích hợp của Oozie, Flume, Pig và Zookeeper YARN khi làm việc trên MapR.
Chúng tôi khuyến khích bạn trở thành chuyên gia dữ liệu lớn ở Toronto.
Vâng, cảm ơn bạn đã đánh giá tốt. Đối với những người mới bắt đầu làm quen với Hadoop, việc theo dõi các cuốn sách hiện có trên thị trường là điều không dễ dàng. Về khía cạnh đó, bài giảng của tôi, giống như đánh giá của Tae-kyung Kim, đã nêu bật quan điểm của việc chạy các ứng dụng Hadoop, HDFS và YARN trên một nút duy nhất trong khi tìm hiểu trước khi mua sách. Nếu nó hoạt động, cảm ơn bạn. Hẹn gặp lại với một bài giảng hay hơn. Tôi mong muốn được phát triển thành một chuyên gia về Hadoop.
Tôi hy vọng rằng bài giảng này sẽ là cơ hội để tiếp cận Hadoop một cách thân thiện hơn. Chúng tôi cũng mong muốn được cung cấp các bài giảng về Spark cho bạn. Chúng tôi khuyến khích bạn trở thành chuyên gia về Hadoop ở Toronto.
























![[Khóa quản lý số 3] DE, DBA (SSIS, SSAS, Machine Learning, BI, ETL)Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/329784/cover/c5e6543b-72c3-4471-b43f-15b9002e65ed/329784-eng.png?w=420)

![[Làm mới] Bootcamp Cơ sở dữ liệu MongoDB và NoSQL (Big Data) cho người mới bắt đầu [Từ nhập môn đến ứng dụng] (Cập nhật)Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)

![SQL dùng ngay trong thực tế [Bài giảng trực tiếp từ tác giả sách SQL 200]Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/335513/cover/e2411bc7-040f-4c60-bbe9-2c254f0f8b18/335513.png?w=420)

![[2026] Giải 176 bài tập sách vàng dành cho bạn thấy đề thi SQLD khóHình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/336270/cover/01kfq647gtwqrwbjwbrn9rhn1t?w=420)
![[DevWonyoung] Apache Kafka dành cho người mới bắt đầuHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/326507/cover/aa474be0-c000-4b61-afbb-cb78ed0fb843?w=420)
![[D-PEC UP_PASS] Chứng chỉ kỹ thuật quốc gia Năng lực trực quan hóa thông tin quản trị (Lý thuyết)Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/336327/cover/01jytyqa2egrzn52a7m57fntzk?w=420)



![[Miễn phí]Khai thác văn bản cơ bản: Phân tích đánh giá ứng dụng với Python(hoàn thành trong 40 phút)Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/331163/cover/74cc657a-a8f9-4a78-8edb-0d5fcd4c4c75/331163.png?w=420)


