[Miễn phí] Bài giảng cơ bản TEXTOM 24 phiên bản mới: Phân tích nhận thức SNS để viết luận văn phân tích cơ bản dữ liệu lớn
Đây là buổi học miễn phí được thiết kế để giúp những người lần đầu tiếp cận 텍스톰 (TEXTOM) dễ dàng trang bị kỹ năng khai phá văn bản và phân tích dữ liệu lớn, thông qua các bài thực hành ví dụ thay vì chỉ tập trung giải thích lý thuyết nguyên tắc.
Việc đảm bảo năng lực thực hành của Textom là điều cần thiết. Trước khi tham gia khóa học, bạn phải tạo tài khoản TEXTOM và đảm bảo có ít nhất 10MB dung lượng trống dưới dạng tài khoản trả phí .
Bạn có thể viết một bài báo hoặc tự phân tích sau khi xem các bài giảng khai thác văn bản trên thị trường không?
“Tôi muốn thấy những ví dụ hoặc ví dụ thực tế về việc áp dụng lý thuyết vào phân tích thực tế chứ không chỉ là lý thuyết.”
“Chúng tôi cần một khóa học khai thác văn bản cho phép chúng tôi viết các bài báo về phân tích xu hướng, phân tích nhận thức, v.v.”
👉 Sau khi xem những đánh giá này, tôi quyết định quay phim bài giảng.
Phân tích dữ liệu lớn, là một xu hướng gần đây, Không có lĩnh vực nào trong kinh doanh/nghiên cứu mà không sử dụng nó.
Khai thác văn bản đang ngày càng trở thành phương pháp phân tích cần thiết cho nghiên cứu. Vì nó đã trở thành xu hướng nên nhiều người muốn học nó.
Textom để khai thác văn bản
TEXTOM là một chương trình tuyệt vời để khai thác văn bản mà không cần viết mã. Tuy nhiên, nhiều sinh viên sau đại học, nhà nghiên cứu và nhân viên văn phòng đang lãng phí thời gian và cảm thấy căng thẳng, gánh nặng vì họ không biết cách sử dụng Textom ngay cả sau khi tham dự các bài giảng hoặc đọc sách.
Một người hướng dẫn không có kinh nghiệm thực tế và chưa bao giờ viết bài báo? Tôi thực sự không thể giải thích cách thực hiện "phân tích dữ liệu lớn".
Chúng tôi sẽ tiết lộ bí quyết cốt lõi và bí quyết hoàn thành bài báo dữ liệu lớn trong nửa ngày bằng cách sử dụng Textom .
Đừng bao giờ tự học. Khai thác văn bản có rất nhiều kỹ thuật phân tích khác nhau.
Nếu bạn chỉ tiến hành bằng cách xem xét các lý thuyết và hướng dẫn mà không biết cách sử dụng các kỹ thuật phân tích thường dùng, chắc chắn bạn sẽ lãng phí thời gian . Sau khi thực hành các kỹ thuật thường dùng trong thực hành hoặc các bài báo dữ liệu lớn , bạn nên dần xây dựng nền tảng lý thuyết vững chắc để sau này có thể phân tích văn bản một cách tự do.
Nghĩa là chúng ta cần biết điều gì là quan trọng và điều gì không quan trọng trong phân tích văn bản . Biết điều này có thể giúp bạn tiết kiệm nhiều tuần hoặc thậm chí nhiều tháng.
Chúng tôi sẽ hướng dẫn bạn những kỹ thuật cơ bản thường dùng nhất dành cho người mới bắt đầu.
Khai thác văn bản và dữ liệu lớn ngày càng được ứng dụng nhiều hơn trong mọi lĩnh vực nghiên cứu. Thực hành doanh nghiệp cũng đòi hỏi khả năng xử lý dữ liệu văn bản phải được nhận dạng. Chúng tôi đã tạo ra bài giảng Textom tập trung vào đào tạo thực tế để bất kỳ ai cũng có thể dễ dàng theo dõi xu hướng khai thác dữ liệu lớn và văn bản hiện tại mà không cần phải viết mã phức tạp và khó khăn.
✅ Thực hành trích xuất dữ liệu, thu thập và phân tích dữ liệu cho người mới bắt đầu sử dụng Textom.
✅ Đây là bài giảng cơ bản về Textom để viết các bài báo dữ liệu lớn (phân tích nhận thức, phân tích xu hướng)
🚩 Tôi cũng đã thử nghiệm rất nhiều lần khi mới bắt đầu sử dụng Textom.
'Tôi nên sử dụng Textom như thế nào trong trường hợp này?' Tôi đã tìm kiếm trên internet và các hướng dẫn sử dụng, nhưng... các giải thích và bài giảng về Textom trên thị trường quá thiên về lý thuyết và quá khó để người mới bắt đầu có thể hiểu được. Tôi nhớ mình đã phải tìm kiếm qua nhiều menu khác nhau và vật lộn nhiều ngày trước khi cuối cùng giải quyết được vấn đề.
Khi còn là người mới bắt đầu và gặp khó khăn khi sử dụng Textom, tôi đã nghĩ, 'Giá như có ai đó hướng dẫn tôi thì việc phân tích dữ liệu lớn và viết bài báo có dễ hơn không?' 'Sẽ rất tiện lợi nếu có một bài giảng có thể đóng vai trò hướng dẫn cho những người mới sử dụng Textom hoặc đang tìm hiểu cách sử dụng phần mềm này'. Tôi đã chuẩn bị bài giảng này với suy nghĩ này.
Bài giảng này được thiết kế để giúp bạn cảm nhận về phân tích dữ liệu lớn bằng cách chứng minh quy trình thực tế của việc trích xuất dữ liệu thay vì cung cấp lời giải thích lý thuyết dài dòng về Textom. Nếu bạn thực hiện theo nhiều lần, bất kỳ ai cũng có thể sử dụng các kỹ thuật phân tích dữ liệu lớn và khai thác văn bản mà không cần lập trình Python.
Dành cho những người mới sử dụng Textom Đây là khóa học thực hành cơ bản.
Bài giảng này được thiết kế để cho phép những người mới làm quen với Textom thực hành thông qua các ví dụ thay vì tập trung vào các giải thích lý thuyết. Nếu bạn nghe bài giảng và theo dõi, bạn sẽ có thể thu thập dữ liệu bằng Textom và sau đó phân tích dữ liệu.
Sau khi giải thích ngắn gọn về lý thuyết cơ bản về khai thác văn bản, chúng tôi sẽ trích xuất trực tiếp dữ liệu lớn bằng chương trình Textom. Trong quá trình này, bạn sẽ hiểu được cách khai thác văn bản và có thể trực tiếp triển khai các phương pháp phân tích dữ liệu lớn.
Nếu bạn có hiểu biết đôi chút về khai thác văn bản hoặc Textom, hãy xem qua hướng dẫn do Textom cung cấp và sau đó tìm hiểu phương pháp thực tế thông qua bài giảng này, bạn sẽ có thể nâng cao kỹ năng phân tích khai thác văn bản của mình rất nhanh chóng.
Tôi giới thiệu điều này tới những người này!
Dành cho những người hoàn toàn mới với khai thác văn bản
Bất kỳ ai muốn học khai thác văn bản với Textom
Dành cho những ai muốn biết về các phương pháp triển khai thực tế sử dụng Textom thay vì các giải thích lý thuyết
Sinh viên sau đại học, nhà nghiên cứu, giáo sư, v.v. muốn viết bài báo về phân tích nhận dạng SNS và phân tích xu hướng bằng Textom nhưng cần nghiên cứu cơ bản
Các quy trình liên quan
Khóa học này được khuyến nghị cho những ai muốn phát triển các kỹ năng ứng dụng TEXTOM thực tế sau khi học khóa học cơ bản miễn phí.
add_shortcode('khóa học','330219','danh sách')
Xin chào, tôi là Jin-gyu Lee.
Lịch sử chia sẻ kiến thức
Hiện đang theo đuổi chương trình Tiến sĩ. trong Trường sau đại học AI (Chuyên ngành Xử lý ngôn ngữ tự nhiên)
Phát triển xử lý ngôn ngữ tự nhiên trong các công ty khởi nghiệp chuyên về AI và dữ liệu lớn hiện nay
Cựu nhà nghiên cứu phân tích dữ liệu lớn của tổ chức công
Nhiều kinh nghiệm dạy kèm riêng liên quan đến phân tích dữ liệu
Xử lý ngôn ngữ tự nhiên AI của Kmong, phân tích dữ liệu lớn Hoạt động dịch vụ chính (2% dịch vụ hàng đầu được Kmong lựa chọn cẩn thận)
Kinh nghiệm viết và trình bày nhiều bài báo dữ liệu lớn bằng TEXTOM
Hỏi & Đáp 💬
H. Tôi là người mới bắt đầu tìm hiểu về khai thác văn bản. Tôi vẫn có thể lắng nghe ngay cả khi tôi không biết gì không?
Vâng, đúng vậy. Khóa học này là khóa học giới thiệu dành cho người mới bắt đầu.
H. Tôi muốn áp dụng khai thác văn bản vào công việc của mình. Tôi có thể tham gia khóa học này được không?
Có, khóa học này bao gồm phần giới thiệu về các phương pháp phân tích thực tế cơ bản thường được sử dụng trong khai thác văn bản.
H. Tôi là người mới bắt đầu và muốn biết cách sử dụng Textom. Bạn có thể cho tôi biết cách sử dụng nó không?
Vâng, bài giảng này dành cho người mới bắt đầu sử dụng Textom. Khóa học này dành cho những người chưa biết cách sử dụng Textom.
"Nếu bạn để lại địa chỉ email cùng với bài đánh giá, chúng tôi sẽ gửi cho bạn dữ liệu bài báo khai thác văn bản miễn phí."
💡 Tôi muốn giúp đỡ những người mới bắt đầu khai thác văn bản và textom!
Chúng tôi sẽ đích thân triển khai các phương pháp sử dụng Textom mà bạn tò mò, cung cấp lời giải thích ngắn gọn về các yếu tố cốt lõi của khai thác văn bản mà bạn thấy khó hiểu và hỗ trợ bạn khi bạn đang cân nhắc phân tích và nghiên cứu dữ liệu lớn. Cảm ơn các bạn rất nhiều vì đã đọc. Hẹn gặp lại các bạn ở lớp nhé!
Xin chào. Tôi là Lee JinKyu (Tiến sĩ Kỹ thuật, Trí tuệ nhân tạo), Đại diện của Happy AI, người đã không ngừng làm việc với AI và phân tích dữ liệu lớn trong nghiên cứu, phát triển, đào tạo và các dự án thực tế.
Dựa trên xử lý ngôn ngữ tự nhiên (NLP) và khai thác văn bản (text mining), tôi đã và đang phân tích nhiều loại dữ liệu phi cấu trúc đa dạng như khảo sát, văn bản, đánh giá, báo chí, chính sách, dữ liệu học thuật, v.v. Gần đây, tôi đang truyền tải phương pháp ứng dụng AI tập trung vào thực tiễn phù hợp với tổ chức và môi trường làm việc bằng cách tận dụng AI tạo sinh và mô hình ngôn ngữ lớn (LLM).
Đã hợp tác với nhiều cơ quan công quyền, doanh nghiệp và tổ chức giáo dục như Samsung Electronics, Đại học Quốc gia Seoul, Sở Giáo dục, Viện Nghiên cứu Gyeonggi, Cục Lâm nghiệp, Tổng cục Quản lý Công viên Quốc gia, Thành phố Seoul, v.v., và đã thực hiện tổng cộng hơn 200 dự án nghiên cứu và phân tích trong nhiều lĩnh vực đa dạng như y tế, thương mại, sinh thái, luật pháp, kinh tế và văn hóa.
07/2024 ~ Hiện tại Doanh nghiệp chuyên về AI tạo sinh và Phân tích dữ liệu lớn Giám đốc HappyAI, a company specializing in Generative AI and Big Data analysis
Tiến sĩ Kỹ thuật (Trí tuệ nhân tạo) Trường Cao học Trí tuệ nhân tạo, Đại học Dongguk
Chuyên ngành chi tiết: Mô hình ngôn ngữ lớn (LLM)
(2022.03 ~ 2026.02)
2023 ~ 2025 Nhà bình luận AI của Public News (Các vấn đề về định kiến AI tạo sinh, RAG, ứng dụng LLM)
2021 ~ 2023 Nhà phát triển tại Stella Vision, công ty chuyên về AI và Big Data
2018 ~ 2021 Nghiên cứu viên Xử lý ngôn ngữ tự nhiên · Phân tích dữ liệu lớn tại Viện nghiên cứu do Chính phủ đầu tư
🔹 Lĩnh vực chuyên môn (Tập trung vào Giảng dạy · Dự án)
Sử dụng AI tạo sinh và LLM
LLM cá nhân (Private LLM), RAG, Agent
Cơ bản về Fine-tuning LoRA·QLoRA
Phân tích dữ liệu lớn dựa trên AI
Dữ liệu khảo sát · đánh giá · báo chí · chính sách · học thuật
Xử lý ngôn ngữ tự nhiên (NLP) · Khai phá văn bản (Text Mining)
Phân tích chủ đề, phân tích cảm xúc, mạng lưới từ khóa
Tự động hóa công việc bằng AI cho công cộng và doanh nghiệp
Tóm tắt · Phân loại · Phân tích văn bản
🎒 Khóa học & Hoạt động (Chọn lọc)
2025
Phát triển ứng dụng LLM/sLLM (Dựa trên Fine-tuning·RAG·Agent) – KT
2024
Lập trình LLM dựa trên LangChain·RAG – Samsung SDS
Lý thuyết LLM và Thực hành phát triển Chatbot RAG – Quỹ Kỹ thuật số Seoul (Seoul Digital Foundation)
Nhập môn phân tích dữ liệu lớn dựa trên ChatGPT – LetUin Edu
Cơ bản về trí tuệ nhân tạo·Kỹ thuật prompt – Viện Phát triển Nghề nghiệp Hàn Quốc
LDA·Phân tích cảm xúc với ChatGPT – Inflearn
Phân tích văn bản dựa trên Python – Đại học Khoa học và Công nghệ Quốc gia Seoul
Tạo chatbot LLM sử dụng LangChain – Inflearn
2023
Cơ bản về Python sử dụng ChatGPT – Đại học Kyonggi
Bài giảng đặc biệt về khóa học chuyên gia Big Data – Đại học Dankook
Cơ bản về phân tích dữ liệu lớn – LetUin Edu
💻 Dự án (Tóm tắt)
Xây dựng chatbot RAG dựa trên Private LLM (Tổng công ty Điện lực Hàn Quốc)
Phân tích dữ liệu lớn về phục hồi rừng dựa trên LLM (Viện Khoa học Lâm nghiệp Quốc gia)
Giải pháp Text Mining Private LLM dành riêng cho mạng nội bộ (Cơ quan Chính phủ)
Phát triển mô hình LLM dựa trên Instruction Tuning và RLHF
Phân tích dữ liệu chăm sóc sức khỏe, luật pháp, chính sách và giáo dục
Phân tích AI dữ liệu khảo sát, đánh giá và báo chí
→ Đã thực hiện hơn 200 dự án bao gồm các cơ quan công quyền, doanh nghiệp và viện nghiên cứu, including public institutions, corporations, and research institutes
📖 Ấn phẩm (Chọn lọc)
Cải thiện phân loại định kiến về kiến thức thông thường bằng cách giảm thiểu ảnh hưởng của các thuật ngữ nhân khẩu học (2024)
Improving Generation of Sentiment Commonsense by Bias Mitigation – Hội nghị quốc tế về Dữ liệu lớn và Tính toán thông minh (2023)
Phân tích nhận thức về công nghệ LLM dựa trên dữ liệu lớn từ các bài báo chí (2024)
Nhiều nghiên cứu khai phá văn bản (text mining) dựa trên NLP (Lĩnh vực Lâm nghiệp · Môi trường · Xã hội · Chăm sóc sức khỏe)
🔹 Khác
Phân tích và trực quan hóa dữ liệu dựa trên Python
Phân tích dữ liệu sử dụng LLM
Nâng cao năng suất công việc bằng cách sử dụng ChatGPT, LangChain và Agent
Cảm ơn bạn đã giải thích chi tiết!!
Đây là bài giảng hữu ích dành cho người mới bắt đầu học Văn bản.
Tôi nghĩ tôi hiểu rõ hơn khi bạn giải thích đi giải thích lại.







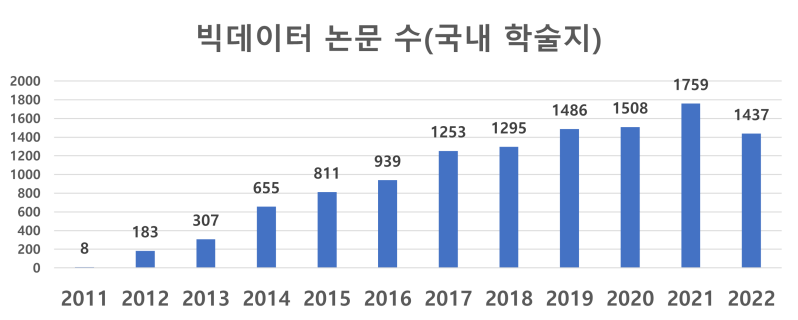
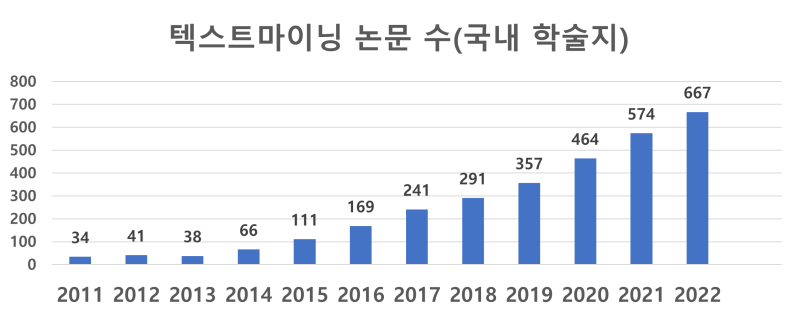
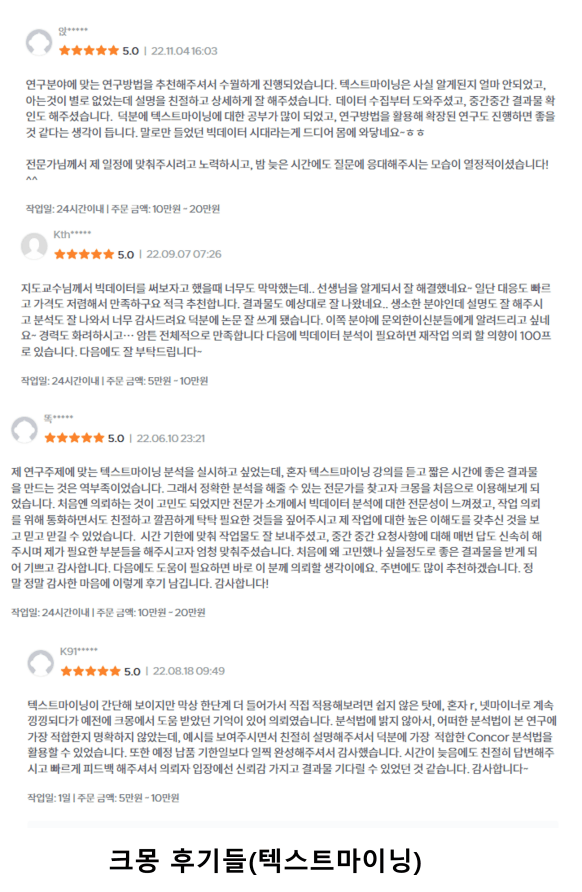



![[Miễn phí]Khai thác văn bản cơ bản: Phân tích đánh giá ứng dụng với Python(hoàn thành trong 40 phút)Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/331163/cover/74cc657a-a8f9-4a78-8edb-0d5fcd4c4c75/331163.png?w=420)





![[Thực chiến]TEXTOM Thực chiến bài giảng: Phân tích văn bản/khai thác văn bản để viết luận văn dữ liệu lớnHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/330219/cover/222b8ffa-fe15-4636-b10b-01cfd19a4114/그림1_크기줄임.png?w=420)







![[2026] Giải 176 bài tập sách vàng dành cho bạn thấy đề thi SQLD khóHình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/336270/cover/01kfq647gtwqrwbjwbrn9rhn1t?w=420)




![[Làm gì sau giờ làm] Chứng chỉ Phân tích Dữ liệu lớn - Kỳ thi thực hành (Dạng bài tập 1, 2, 3)Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/329972/cover/dcfb28fd-48c1-4bb1-ab31-d59eac874194/329972-original.png?w=420)


![[2026] SQLD All-in-One - Người không chuyên cũng đậu ngay lần đầuHình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/336953/cover/01kfq68bzb04w1mydc92ysfads?w=420)



