





マイクロナットJavaクラウドアプリケーションの作成
Billy Lee
Java Oracle Cloudネイティブアプリケーションを制作しながら、非同期処理、I/O処理、高性能Webアプリケーション、さらにJITコンパイラ技術で2倍以上の高速アプリケーション実行処理でネットワーク入力に負荷のない超高速アプリケーションを製作する予定です。
初級
Micronaut, Oracle, MSA

まさにビッグデータ時代! 👨💻
Hadoopで専門家になろう。

複数のIT大企業、ソーシャルメディアサービスなどで、ビッグデータの分析と処理にHadoop(Apache Hadoop)を先取りして使用しています。 Hadoopは、大量のデータを少ないコストで処理できるように作られたJava言語ベースのフレームワークで、大規模なデータセットを分散保存して処理します。ところで、そのようなHadoopを通じてビッグデータの専門家レベルのクラスに上がることができたらどうでしょうか。
企業はデータ分析を通じて新しい市場を開拓し、希少な価値を与え、新しい消費者に必要な情報をリアルタイムで提供できる快感を与えることができるようになります。中小企業 またビッグデータは必ず取り扱うべき必須事項であるだけに、ビッグデータ関連職務で就職/転職を夢見る方には朗報ではありません。
BigData with Hadoop

Google、Yahoo、Facebook、IBM、Instagram、Twitterなど
複数の企業がデータ分析に使用している
代表的なビッグデータソリューション、Hadoopを通じて
ビッグデータ分散型システムインフラストラクチャを構築します。
このレッスンでは、ビッグデータの用語を理解し、オープンソフトウェアHadoopを介してビッグデータを扱うプロセスを間接的に体験します。この講義を通じて、受講生の皆さんはビッグデータテクノロジー(Big Data Technology)の世界、そして第4次革命の世界を同時に経験できるようになります。
Hadoopとは?



もちろん、ここに該当しない方も歓迎します。 (初心者は2倍に歓迎します✌)




受講前、選手の知識をご確認ください!
サーバー統合に有利な仮想化技術を学び、OSレベルの仮想化を介して1つのOSに複数のサーバーを分離する方法に基づいて学びます。 Linuxに適用できる仮想化方式であるオープンソースソリューションUbuntuを通じて、誰もが挑戦して大量のサーバーを製作運営することになるでしょう。さらに、ゲストオペレーティングシステムの知識はもちろん、大量のサーバーを通じてビッグデータを分散技術に変えることになり、広がる多量の技術経験を蓄積できるようになります。サーバー仮想化を使用して、1つの物理サーバー上またはオペレーティングシステムで非常に効率的な仮想マシンの難しいオペレーティングシステムを体験することができます。
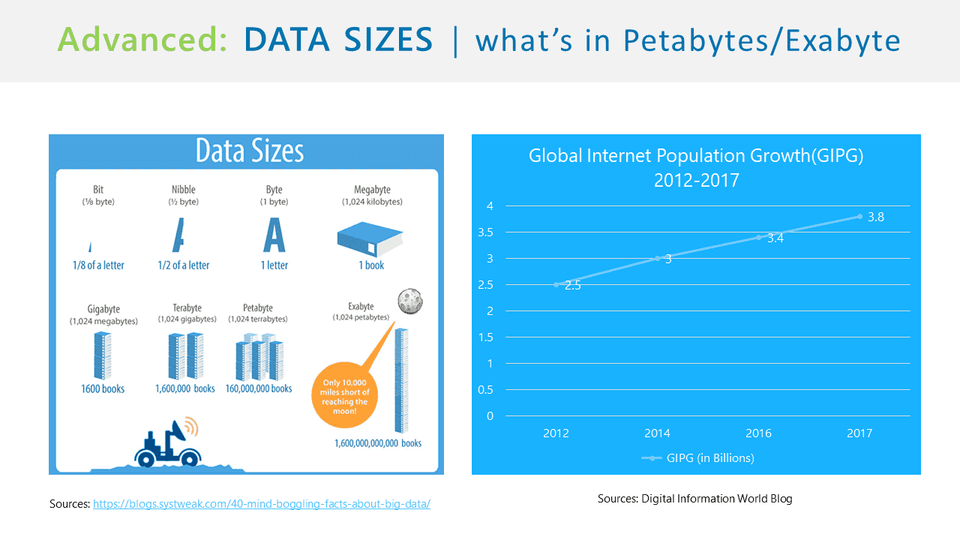

フロントエンド(FrontEnd)開発者がWebアプリケーションを開発する際に自然に遭遇するLinux CLI(Command Line Interface)方式のツールを使用する基礎的な方法から、Hadoopを扱うLinuxターミナルを自然に学ぶ予定です。もちろん、非 Windows ベースの GUI 環境で原도のように Ubuntu を使用するための前提事項を学びながら、セルの設定ファイルなどの Linux システムの理解を超えて中級者方向に自然に導きます。
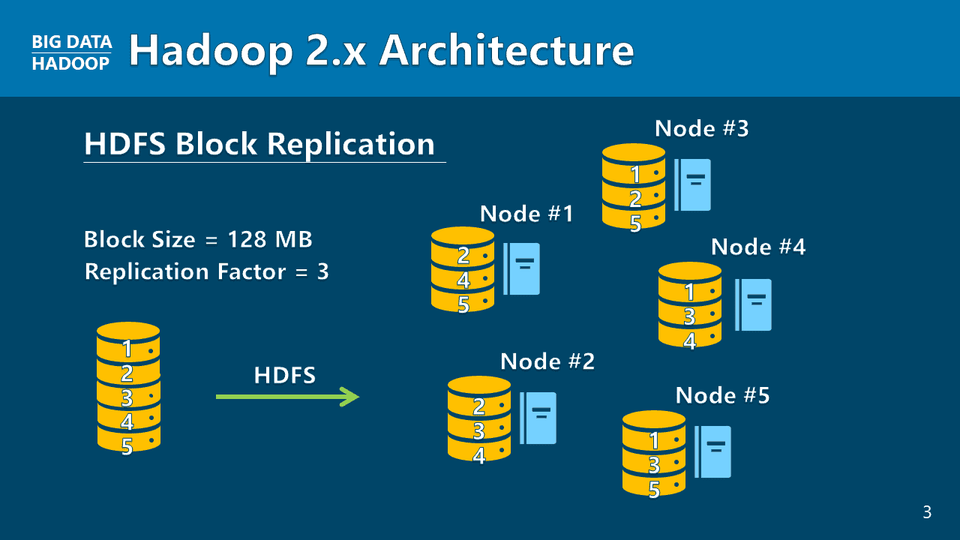

非定型データ処理のためのビッグデータの始まりは、GoogleのファイルシステムのモデルであるHadoop分散ファイルシステム(HDFS)とMapReduce(MapReduce)、そしてYan(YARN)というクラスタ拡張とリソース管理の理解です。 Hadoop Version 1、2、3のアーキテクチャ構造について一つ一つ見て、Hadoop技術の歴史がどんなものか受講生の皆さんに絵を描きます。
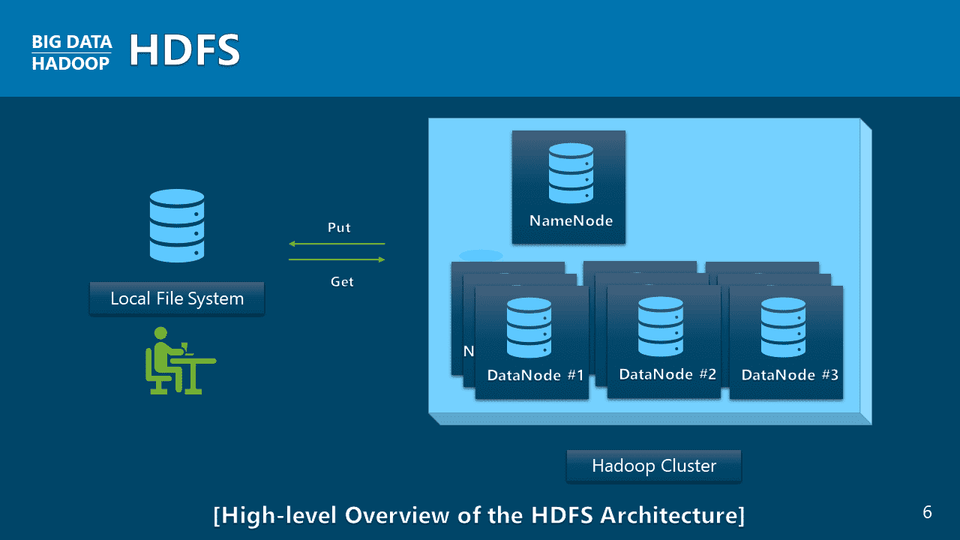
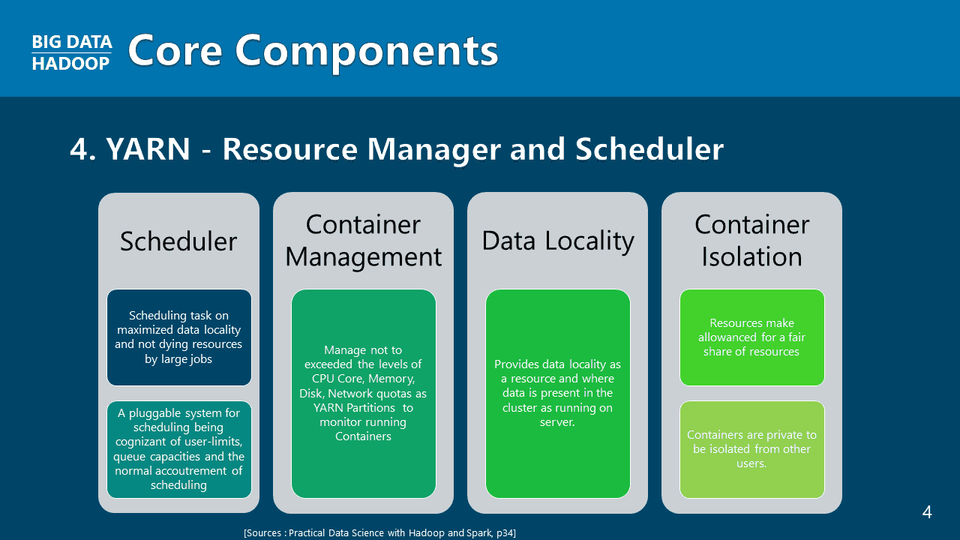
データ操作に使われる技術は多様ですが、ビッグデータ分析の基礎はマップリデュースアプリケーション制作にあります。プログラミング言語Python(Python)で、基本的なWordCount MapReduceアプリケーションからEclipseベースのJava言語でCOVID-19アプリケーションを作成するまで、さまざまなビッグデータマップリデュースアプリケーションの作成は、選択を超えて必須に進むべき方向を提示します。
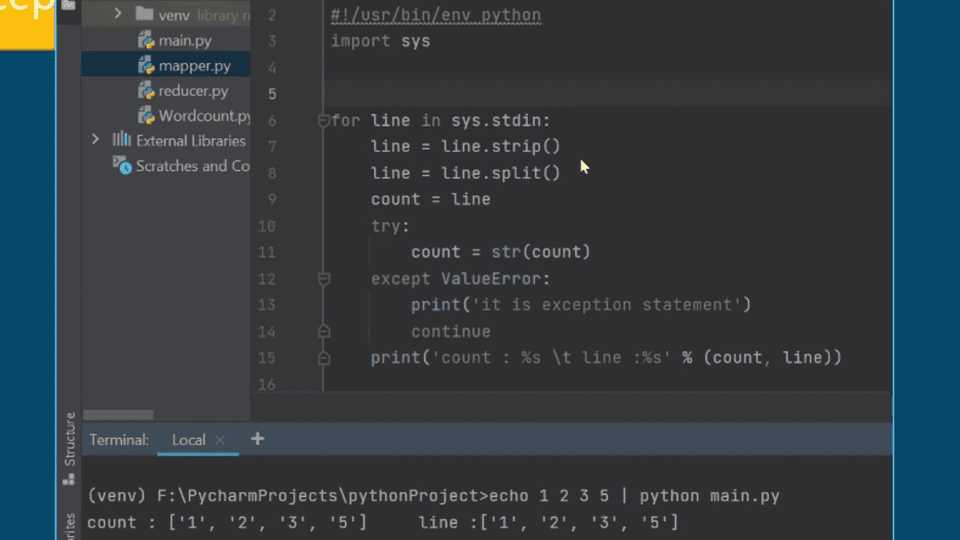
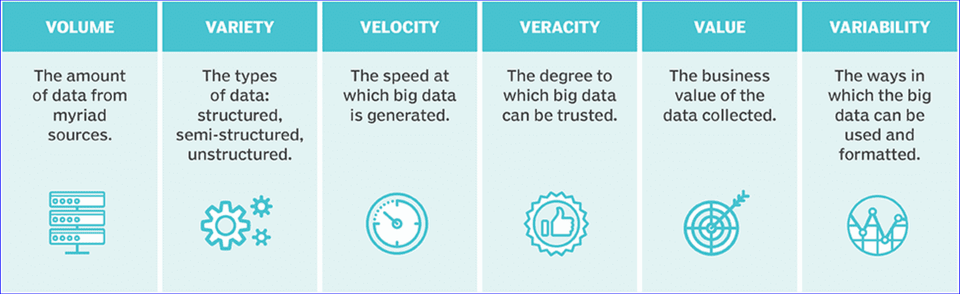
Q. ビッグデータとは何ですか? Hadoopを使用するときは、その定義が必要ですか?
はい、もちろんHadoopを扱うときは必ずビッグデータの簡単な定義と理解を求めます。もちろん、完璧で深いレベルの熟知を必要とするほどではありません。ただ、Hadoopを扱う際に必ず必要な理解度を求める形でしょう。
ビッグデータはHadoopツールを備え、非常に大きなデータセットを扱います。このデータセットは、多数の企業が扱うさまざまなパターンやトレンドを特定するために分析する基礎データです。人間の社会的行動とパターン、そして相互作用の中で繰り広げられる人類の価値創造と関連が立っています。
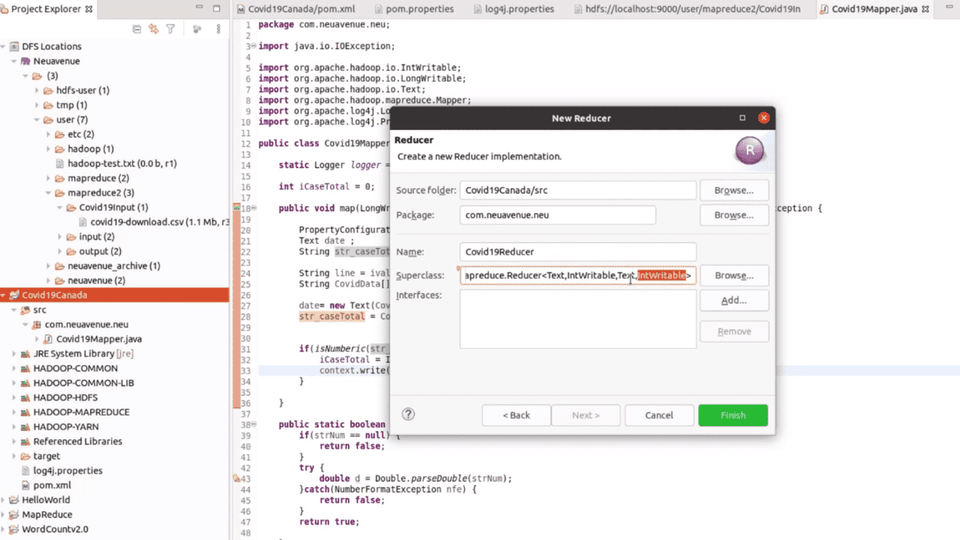
Q. Hadoopとは何ですか?コンポーネントは何で、Hadoopスタックは何ですか?
テラバイトを超えてペタ(Petta/Zettabyte)に至る大規模ソーシャルサイトのデータを 処理しなければならない使命をHadoopが助けています。 Hadoop Stackとは、このようなビッグデータを扱うオープンソースのフレームワーク方式です。
単に「Hadoop」は「Hadoop Stack」と呼ばれます。安価で日常的なコマディティハードウェアを使用してクラスタを構築し、その膨大なサーバーの集合体であるクラスタ内で大容量プロセスを処理するのを助けるのは、HadoopとHadoopスタックです。 Hadoopスタックは「単純なバッチプロセス」とも呼ばれ、Javaベースの「分散コンピューティングプラットフォーム」です。だから個人が望むだけのデータを周期別にバッチを回して処理しながら、データを所望の形に加工分散して結果値を算出するのです。
Q. プログラミングの知識が必要ですか?
プログラミングの知識やコードを書く経験がなくても大丈夫です。 JavaやPythonを初めて体験すると考えて教えるように、深い理解をもとに授業を進めます。講義に書かれた文書は英語で書かれていますが、従うことには支障がないように韓国語で講義します。たまに英語で説明をするのですが、高校レベルであれば解釈できないでしょうか? (私の低い英語力でも夢を叶えたようです。)
Q. Hadoopを扱うのにビッグデータはどのくらい関連がありますか?
この講義は当然ハドゥプを扱っています。単にRDMSというOracleやMSSQL、あるいはMYSQLを越えて大容量処理をはじめ、データ処理速度の問題、低コスト効果という企業の必須要素を創出したいと思います。特にソーシャルを扱わなければならない企業、つまりすぐに行と列に基づくデータRDMSで扱うリレーショナルデータを扱うストラクチャデータ(Structured data)だけでなく、画像、オーディオ、ワードプロセスファイルそのものを扱わなければならないアンストラクチャデータ(Unstructred data)などもハドゥが扱います。
サービスストラクチャーデータを扱うときは、Email、CSV、XML、およびJSONなどのWebサーバーとの通信とデータ連携に関するデータを言っています。 HTML、Web Sites、NoSQL Databasesもここに含まれています。もちろん、EDIというビジネス書類関連の計算移動させるコンピュータ対コンピュータ間の移動処理問題を扱う際に使うデータセットの累積もやはりここに属します。

Q.どの程度レベルまで内容を扱いますか?
このレッスンでは、Ubuntu(Ubuntu)20.04 LTSベースにHadoop(Hadoop)3.2.1をユーザーが直接インストールするのに役立ちます。 UnixやLinuxの経験がなくても自然に追いつくと、Linuxを基につながるインストールのヒントとLinuxオペレーティングシステムを自然に熟知することになります。また、Hadoopが扱うCLI言語やユーザー言語を習得する基本的な部分を超えて、Googleが持っている技術であるDFS and MapReduce技術に慣れるのに役立ちます。 YARN(ヤン)についての理解は基礎理論だけを持つことになります。 後にHadoop 3.3.0中級コースでクラスターを設置しながらヤンについてのより深い学習を期待してください。
Q. Ubuntu 20.04 LTSを練習環境として使用する理由はありますか?
Ubuntuは無料で利用可能で、LTS(Long-Term Service)を通じて長期サービスのサポートを夢見ている企業を対象に、HadoopをLinuxにインストールしながら、自然に企業が要求するオペレーティングシステムや開発環境を構築するのに役立ちます。同じ環境内でEclipseやIntelligentを使用することで、ビッグデータを扱うデータサイエンスの夢を実現するのに役立つ時間があります。

同様の環境、つまりグラフィカルユーザーインターフェース(GUI)
環境を通じてユーザーを助けています。
Hadoop川の本当によかったです! スパーク講義も開いてほしいです。 ありがとうございます!
現業でMapRを活用したビッグデータプラットフォームの運営を担当しています。講師の講義がたくさん役に立っています ありがとう
Hadoopの入門者にはいいですね。本を見る前にまず学習するのにちょうどいいようです。
利点: Hadoop MapReduceの基礎を学ぶことができます。 韓国語で唯一のHadoop講義のようです 残念なこと: マッパーを2つ使用して1つの共通キーに抽出する キーを2つ書く場合、 コンパレータを直接設定する方法 など気になった内容がなくて残念だった。 欠点: 講師様韓国語の発音が明確ではないが、背景音楽が大きくて何度何を言うのか再び聞かなければならなかった。 --------------------------------------- 先生の回答を見て別点5に修正します。
この講義は、ビッグデータを扱うHadoopの専門家として養成したい心で講義を制作しました。クラウデラなどの包括的なオンプロメス配布ソフトウェアアプリケーション(OPD)を使用するのではなく、Hadoopを最初からインストールし、データセットを抽出、移動、およびロードすることに進みます。 1.xバージョンから始まったHadoopは、3.3バージョンまで多くの機能が追加されて非常に海賊なプラットフォームになりましたが、多くのツールを扱い、ビッグデータ専門家として養成される心溢れる講義になることを願っています。


![[データ前処理] 心配しないで!Pandasがあるから。講義サムネイル](https://cdn.inflearn.com/public/files/courses/336824/cover/01k5849rtc0vfa7df3revd2tpb?w=420)




![[リニューアル] 初めてのMongoDB(モンゴDB) と NoSQL(ビッグデータ) データベース ブートキャンプ [入門から活用まで] (アップデート)講義サムネイル](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)
![[ディペックアップ_PASS] 国家技術 経営情報視覚化能力(筆記)講義サムネイル](https://cdn.inflearn.com/public/files/courses/336327/cover/01jytyqa2egrzn52a7m57fntzk?w=420)

![[マーケティングアーカイブ] ビッグデータ活用マーケティング戦略講義サムネイル](https://cdn.inflearn.com/public/files/courses/339225/cover/01k7e89h4d1fkmcr1bwfh1j33h?w=420)






![[リニューアル] 初めてのSQLとデータベース(MySQL) ブートキャンプ [入門から活用まで]講義サムネイル](https://cdn.inflearn.com/public/courses/324208/cover/85872a8e-d2bb-4c43-82fc-d55fa067746e/324208.png?w=420)


