




![[PyTorch] 簡単に素早く学ぶディープラーニング講義サムネイル](https://cdn.inflearn.com/public/courses/324742/course_cover/96781b94-7bae-47f8-ab6f-42821f26f042/coco-pytorch.png?w=420)
[PyTorch] 簡単に素早く学ぶディープラーニング
coco
MLP、CNN、RNNなど、ディープラーニングの基本的な骨組みを簡単に素早く学びます。
中級以上
Deep Learning(DL), Artificial Neural Network, PyTorch
理論と実践は異なります。機械学習の基本概念を把握し、必ず知っておくべき様々なモデルの核心的な概念と理論を紹介します。そして、多様なデータを扱いながら、実戦に役立つ様々な技法とノウハウを共有します。

学習した受講者のレビュー
5.0
eastone0508
教育が楽しかったです。
5.0
김동현
現業に役立つことが多いようです。
5.0
blueday
講義ありがとうございます。
機械学習と人工知能に関する基本概念
線形回帰分析
知っておくべき機械学習モデルの核心概念
クラス不均衡問題を解決する手法
クラスタリング(群集分析)に関する概念と理論
データを正しく分析する方法
初心者データサイエンティストのための第一歩!
機械学習および人工知能に関する基本的な核心概念を学習したいですか?この講義では、データサイエンティストになるために必ず必要な核心概念と理論、そして実戦に必要な様々な技法を紹介します。


ですので、この講義では数学的な説明よりも核心中心の概念説明を行い、初心者の方でも簡単に理解できるようにしました。それだけでなく、実戦でデータを扱う際に直面する問題点と、それらの問題を解決するための様々な方法やノウハウも共有します。

機械学習モデルの
核心的な概念と理論を
知りたい方

データサイエンティストとして
急成長
したい方

実戦で必要な
機械学習の手法とノウハウを
身につけたい方
内容をすべて学習した後は、少なくともデータサイエンティストとしてデータを適切に分析できるようになるよう講義を構成しました。それだけでなく、データドメインに合わせた適切な実験設計を行い、モデルの性能を高めるための変数選択やモデリングまでできるようになります。
Q. 講義を受けるために数学的な知識はたくさん必要ですか?
学部レベルの統計学を必要としますが、関連する知識がなくても問題ありません。
Q. Rを扱える必要がありますか?
はい、RまたはPythonをある程度扱えるという前提で授業を進めます。以下の<Rプロ그래밍 기초 다지기>(Rプログラミング基礎固め)の授業を受講されることをお勧めします。

Rプログラミング基礎固め
データ分析、Rプログラミングが初めてなら?無料講義

経験から得た
核心ノウハウを
伝達

生々しく
学ぶ
ライブコーディング

多様な
データで
実戦感覚Up
単なる機械学習の理論講義や、データを当てはめてみるだけの単純な実習に留まりません。7回参加したビッグデータ大会(7回本選進出、5回受賞)や様々なプロジェクトを通じて得た経験から、データ分析を上手く行うためのノウハウを最大限にお伝えしたいと考えています。
実際に私がデータ分析を行う過程をお見せするために、実習の大部分はライブコーディングで進行されます。コーディングの過程で分からないことが出てきたときに、どのように検索し、どのように適用するのかまで詳細にお見せし、データを扱う中で直面する問題点や、それを解決するために使用する方法も併せて共有します。
さまざまなデータを扱います。例題としてよく使われるボストン・ハウジング(住宅価格予測)データをはじめ、多重共線性(マルチコ)が非常に強いシミュレーションデータ、映画レビューのポジティブ・ネガティブ予測(韓国語)データ、ソウルのヴィラ伝貰(チョンセ)価格予測データ、KaggleのOttoデータなど、多様なデータを扱うことで実戦感覚を身につけます。
機械学習とは何か、機械学習で何ができるのかについて扱います。また、機械学習とディープラーニングの違いは何か、様々な機械学習モデルとディープラーニングモデルについて簡潔に紹介します。あわせて、機械学習とディープラーニングの分野で共通して発生する過学習(オーバーフィッティング)現象について扱います。

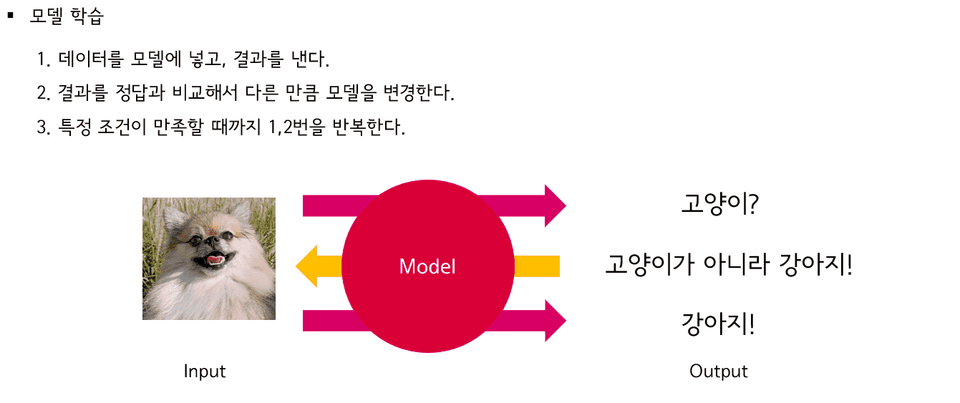
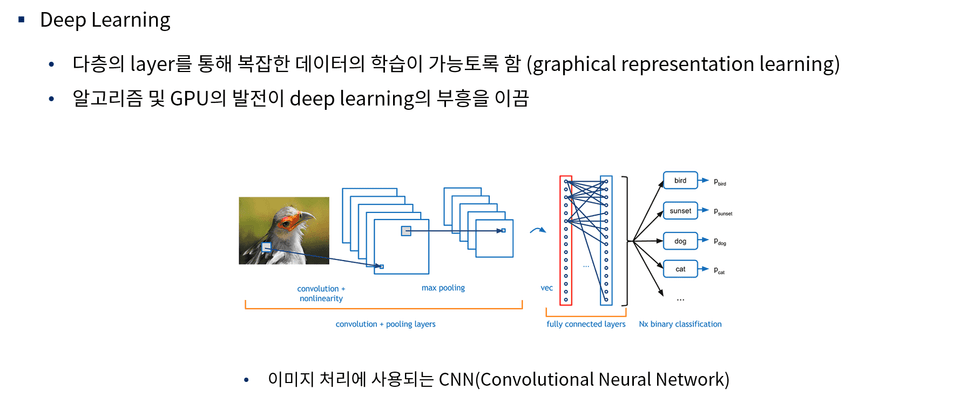
機械学習を学ぶ際、常に最初に学ぶモデルが線形回帰モデルです。それほど簡単でシンプルなモデルですが、性能が良くないという理由であまり使われない傾向があります。しかし、線形回帰モデルは実務で多く使用されており、線形回帰問題においては強力なツールです。最も基本となる理論と概念を重点的に扱います。

必須として知っておくべき機械学習モデルについて扱います。数学的な内容よりも、理解しやすいように概念を中心に講義を進めます。あまり使われないモデルであるDecision Tree、kNNなどのモデルは、単体モデルとしてはあまり使われませんが、他の分野やモデルで多様に活用されます。したがって、決して疎かにしてはいけません。多様なモデルの概念と活用法を学び、eXplainable AIとして脚光を浴びているShapValueについても紹介します。


クラス不均衡問題は、思ったよりも多様な分野で頻繁に発生し、さまざまな問題を引き起こします。代表的なものとして、多数派クラスに偏ってモデルが学習されることで、予測性能が低下する点が挙げられます。このような問題を解決するための多様な手法(Resampling method)について紹介します。

データを分析することは、単にデータを読み込んでモデルを適合させる過程で終わるものではありません。基本的なデータの前処理を経て、Y値を予測するために主要な派生変数を生成し、適切な実験設計を必須で行う必要があります。多様な状況に合わせた実験設計と、データサイエンティストとして知っておくべき必須知識をお伝えします。


"機械学習の理論と実践には、かなりの差が存在します。世の中には多様なドメインとデータがあり、データを分析するためには単にモデルを学習させるだけでは不十分です。ドメインに合わせた適切な実験設計と、モデルの性能を高めるための派生変数の生成、そして分析目的に応じたモデルの選択が不可欠です。
この講義では、データサイエンスと人工知能の概念と核心をできるだけ分かりやすく説明し、実戦で使える様々なヒントやノウハウを提供します。この講義を通じて、データ分析の実戦感覚を養い、実力を向上させることができるよう願っています。"
学習対象は
誰でしょう?
機械学習モデルの核心概念と理論を知りたい方
データサイエンティストとして早く成長したい方
前提知識、
必要でしょうか?
学部レベルの統計学
Rプログラミング基礎
8,491
受講生
524
受講レビュー
136
回答
4.4
講座評価
20
講座
学部では統計学を専攻し、産業工学(人工知能)の博士号を取得して今もなお勉強中の無職です。
受賞
ㆍ 第6回ビッグコンテスト ゲームユーザー離脱アルゴリズム開発 / NCソフト賞(2018)
ㆍ 第5回ビッグコンテスト 住宅ローン延滞者予測アルゴリズム開発 / 韓国情報通信振興協会長賞(2017)
ㆍ 2016 気象ビッグデータコンテスト / 気象産業振興院長賞(2016)
ㆍ 第4回ビッグコンテスト 保険詐欺予測アルゴリズム開発 / 本選進出(2016)
ㆍ 第3回ビッグコンテスト 野球試合予測アルゴリズム開発 / 未来創造科学部 長官賞(2015)
* blog : https://bluediary8.tistory.com
主に研究している分野は、データサイエンス、強化学習、ディープラーニングです。
クローリングとテキストマイニングは、現在は趣味でやっています :)
クローリングを利用して、人気のコミュニティ投稿だけを収集して表示する「マロン」というアプリを開発し、
全国のグルメ店リストとブログを収集して、グルメ推薦アプリも作りましたね :) (見事に大失敗しましたが..)
現在は人工知能を研究している博士課程の学生です。
全体
71件 ∙ (14時間 31分)
講座資料(こうぎしりょう):
1. オリエンテーション
10:28
2. 機械学習の概念
13:09
3. 機械学習の区別
06:35
4. 機械学習の種類
25:17
5. ディープラーニングとは?
10:22
6. ディープラーニングのさまざまな分野
19:04
7. モデルの適合性評価
22:25
8. モデルのパフォーマンス指標
15:06
9. 回帰分析とは
08:15
10. 回帰係数の推定
13:32
11. 回帰係数の意味
15:10
12. 多重回帰分析
09:32
13. モデル検定と多重共線性
11:26
14. 多重共線性診断方法
17:36
15. 回帰モデルの性能指標
04:57
17. 交互作用
04:11
18. 回帰モデルの診断
06:28
19. 多項回帰分析
04:15
20. ロジスティック回帰分析
08:53
22. 回帰係数縮小法
08:08
23. 回帰係数縮小法 - Ridge
09:02
全体
30件
4.8
30件の受講レビュー
受講レビュー 1
∙
平均評価 5.0
受講レビュー 10
∙
平均評価 4.9
受講レビュー 1
∙
平均評価 5.0
受講レビュー 5
∙
平均評価 5.0
受講レビュー 1
∙
平均評価 5.0
知識共有者の他の講座を見てみましょう!
同じ分野の他の講座を見てみましょう!
期間限定セール、あと3日日で終了
¥60,060
30%
¥10,805




![[Rとする]機械学習のための統計学の基礎講義サムネイル](https://cdn.inflearn.com/public/courses/325155/course_cover/d8120723-26f7-4fcc-a25c-a99eef4ea0f6/machine-learning-statistics-r-eng.png?w=420)
![[PyTorch] NLP を簡単に素早く学ぶ講義サムネイル](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)
![[R] KOSPI/KOSDAQ 全銘柄データの収集および管理講義サムネイル](https://cdn.inflearn.com/public/courses/324972/course_cover/36468a43-de3b-461b-af55-f3c7b0e51637/kospi-kosdaq-data-eng-1.png?w=420)
![[PyTorch] GAN を簡単に素早く学ぶ講義サムネイル](https://cdn.inflearn.com/public/courses/324945/course_cover/9794a376-0e54-4745-8a1d-3c6fe72b8fe6/pytorch-gan-eng.png?w=420)














![[7日完成] 一発合格するMS AI-900資格証講義サムネイル](https://cdn.inflearn.com/public/files/courses/338854/cover/01k4caartf5v7x2e574pq0wnp8?w=420)

![[テンソルフロー2] Pythonマシンラーニング完全征服 - マラソン記録予測プロジェクト講義サムネイル](https://cdn.inflearn.com/public/courses/324207/course_cover/1a79c7dc-1624-4d3a-95ff-79ba1e9c4025/python_machine_learning.png?w=420)



![[ICTアーカイブ] ビッグデータの核心とビジネスモデル講義サムネイル](https://cdn.inflearn.com/public/files/courses/338811/cover/01k44rs7zkwq0ehc8vqsy2mdtb?w=420)




