
![[PyTorch] 簡単に素早く学ぶディープラーニング講義サムネイル](https://cdn.inflearn.com/public/courses/324742/course_cover/96781b94-7bae-47f8-ab6f-42821f26f042/coco-pytorch.png?w=420)
[PyTorch] 簡単に素早く学ぶディープラーニング
coco
¥10,355
中級以上 / Deep Learning(DL), Artificial Neural Network, PyTorch
4.2
(19)
200+
MLP、CNN、RNNなど、ディープラーニングの基本的な骨組みを簡単に素早く学びます。
中級以上
Deep Learning(DL), Artificial Neural Network, PyTorch
Q-learningからDeep Q-learningについて学び、強化学習をRで具現してみる時間があります。 Deep Q-network を超えて Self-imitation learning と Random Netowrk Distillation までの全体的な強化学習内容を扱います。
受講生 97名
難易度 中級以上
受講期間 無制限

強化学習理論
Q-learningからDeep Reinforcement Learningまで
Explorationのためのいくつかの強化学習技術
🙆🏻♀ Q-learningとDeep Q-learningを超えてRNDまで🙆🏻♂
アルファゴで始まった強化学習のブーム、強化学習はアルファゴが出る以前から存在していたアルゴリズムであることを知っていましたか?

強化学習は、一般的に勉強するのに進入障壁が高い分野として知られています。アルファゴが出てきてから多くの人が興味を持ち始めていましたが、内容が簡単ではなく、勉強するのが難しいです。強化学習を勉強したかったのですが、難しくて始まらなかった方のために重要な部分だけを選んでまとめてお知らせします。 Q-learning から DQN そして DQN を超えて強化学習の主な問題である sparse reward problem と、これを解決するためのいくつかのアイデアを紹介します。短時間で強化学習を全体的に勉強できる良い講義になります。
強化学習がいったい何なのか、強化学習にはどのような要素があり、どのように学習が進行するのかを例に次々と説明します。
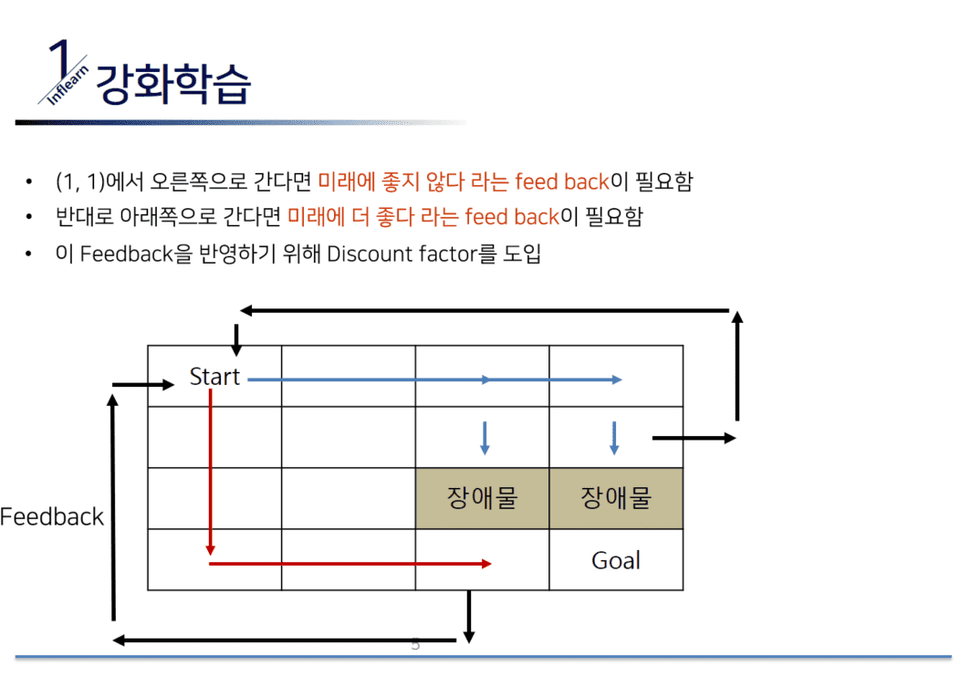
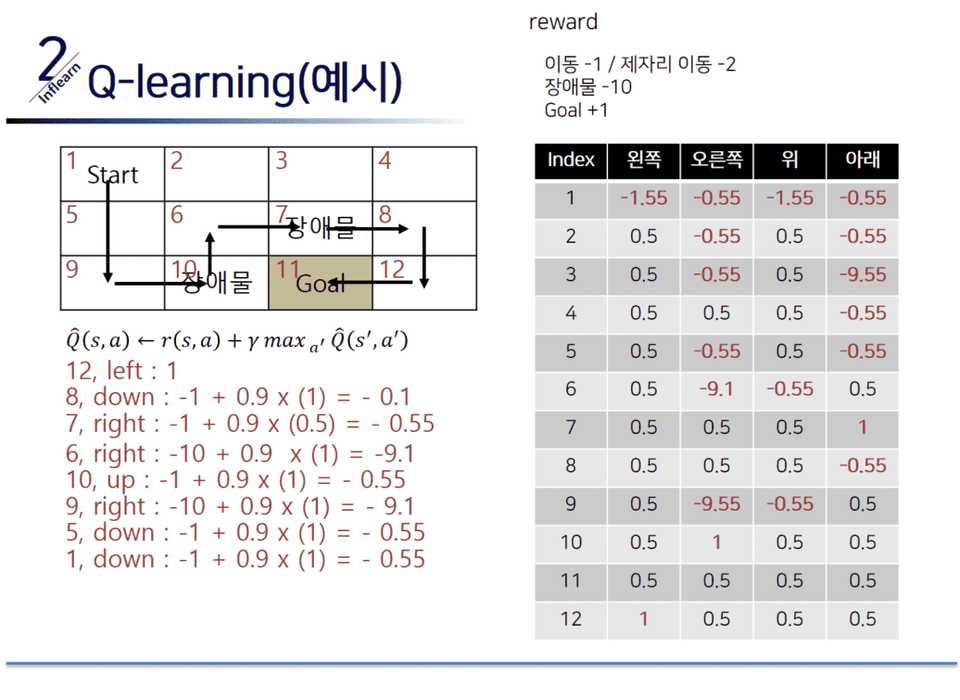
言葉だけ説明しては理解できません。手で直接Q-learingを解きながら強化学習の概念をしっかり理解してみましょう。
Deep reinforcement learningの基本これは、Deep Q-network(DQN)からPerDQNを含む多くのDQN変形、actorcritic、Self-Imitation learingまで重要な内容を中心にまとめています。
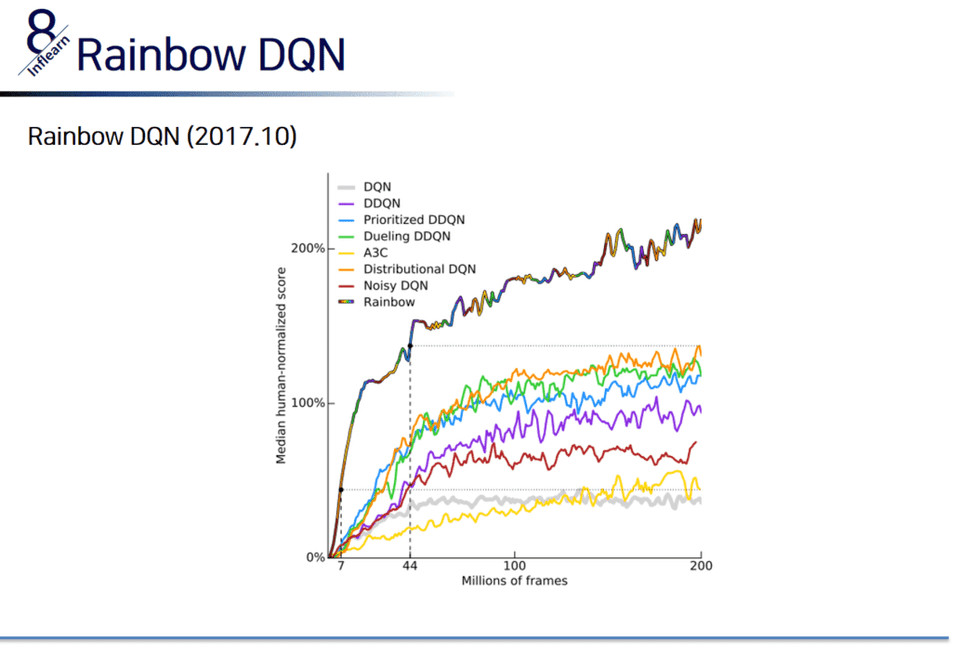
強化学習の主な問題である sparse reward problem について話し、これを解決するためのいくつかの技法について話します。
私たちは主に「curiosity」または「prediction error」について話し、それらを活用したいくつかのアルゴリズムについて紹介します。
(SIL、Random Network Distillationなど)

直接コードで実装してみないと半分だけ知っているのでしょう?最も重要なモデルについては、Rで直接強化学習アルゴリズムを組み込み、結果を一緒に確認してみてください。
そしてExplorationのためのRNDが本当に効果があるかどうかを一緒に確認してみましょう。
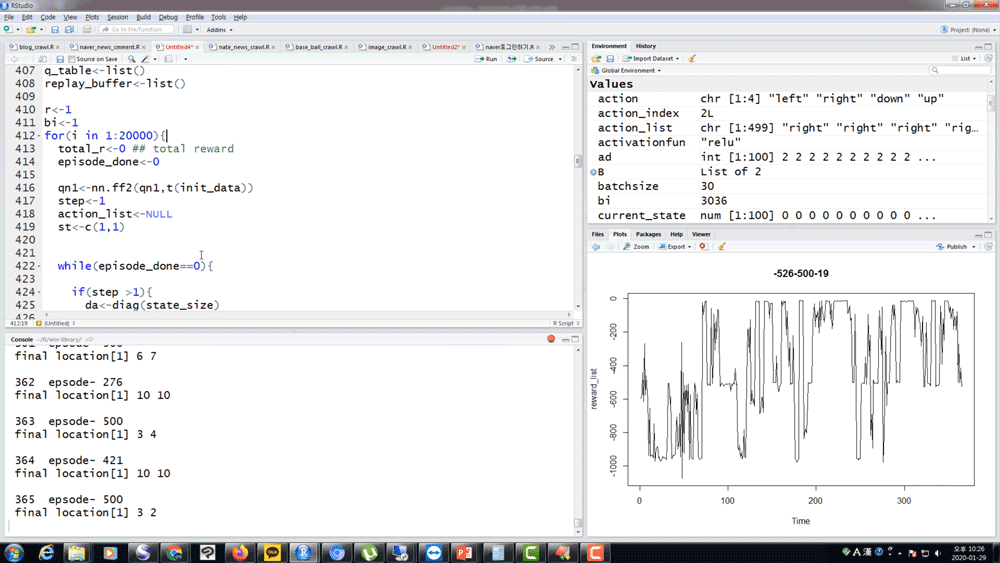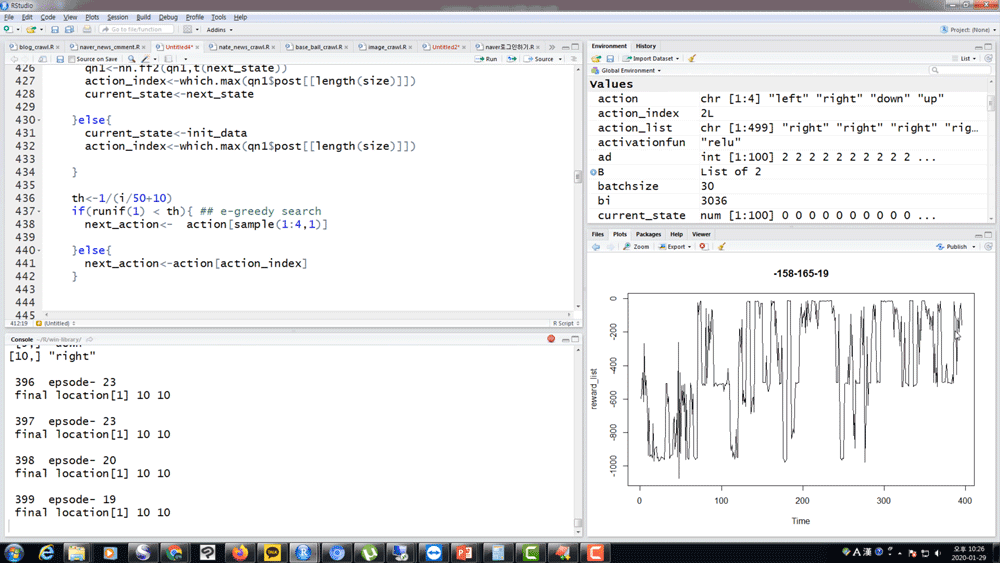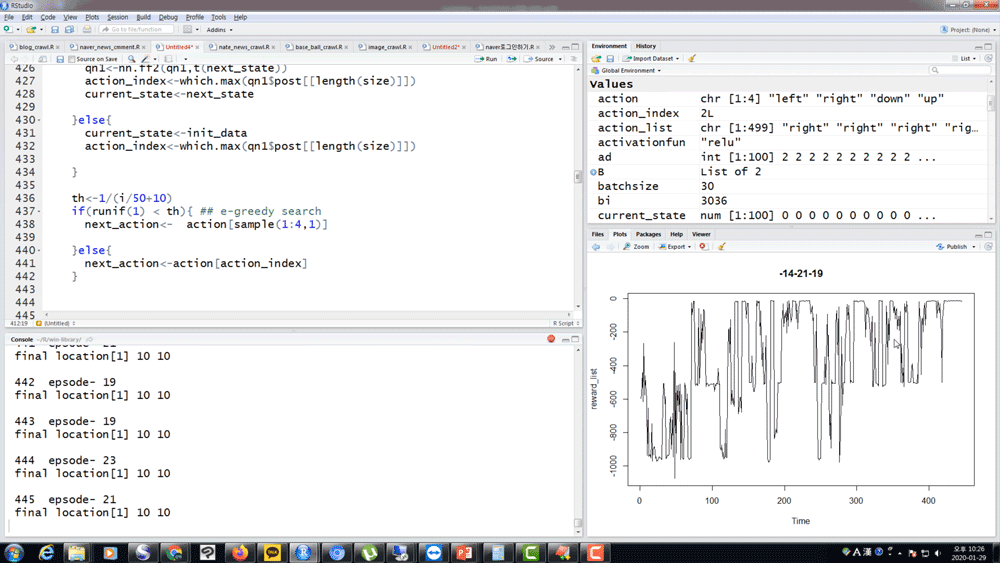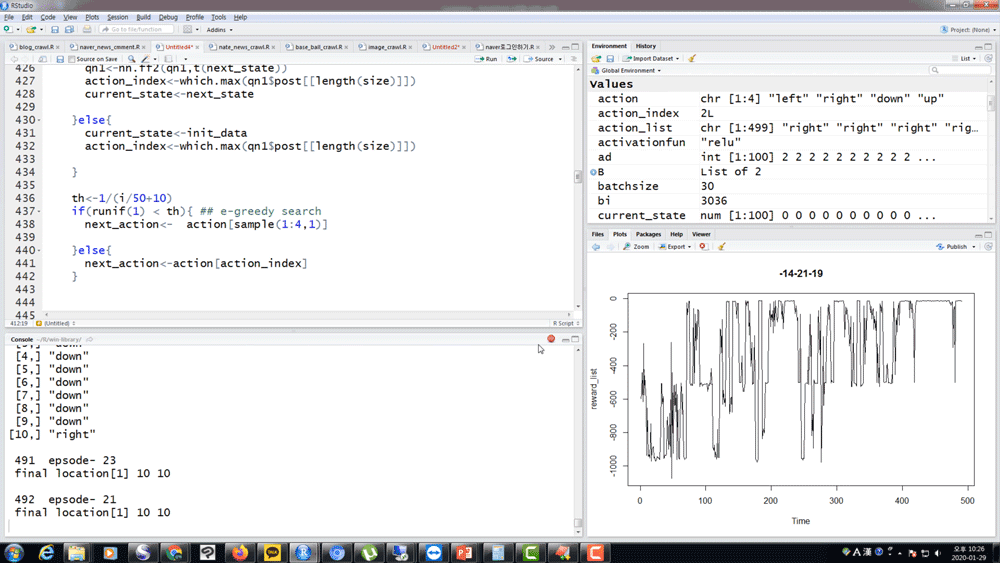
Q. 選手の知識はありますか?
A. 機械学習、NNに関する基本的な概念があることをお勧めします。
Q. Pythonで練習しませんか?
A. 現在はRで実習コードを実装して講義をアップロードし、今後はpythonで実習するコードをアップロードする予定です。
学習対象は
誰でしょう?
強化学習簡単に学びたい人
短時間で全体的な強化学習を学びたい人
前提知識、
必要でしょうか?
Rプログラミング中級スキル
Neural ネットワークの基本的な理解
機械学習の基本的な知識
8,488
受講生
522
受講レビュー
136
回答
4.4
講座評価
20
講座
学部では統計学を専攻し、産業工学(人工知能)の博士号を取得して今もなお勉強中の無職です。
受賞
ㆍ 第6回ビッグコンテスト ゲームユーザー離脱アルゴリズム開発 / NCソフト賞(2018)
ㆍ 第5回ビッグコンテスト 住宅ローン延滞者予測アルゴリズム開発 / 韓国情報通信振興協会長賞(2017)
ㆍ 2016 気象ビッグデータコンテスト / 気象産業振興院長賞(2016)
ㆍ 第4回ビッグコンテスト 保険詐欺予測アルゴリズム開発 / 本選進出(2016)
ㆍ 第3回ビッグコンテスト 野球試合予測アルゴリズム開発 / 未来創造科学部 長官賞(2015)
* blog : https://bluediary8.tistory.com
主に研究している分野は、データサイエンス、強化学習、ディープラーニングです。
クローリングとテキストマイニングは、現在は趣味でやっています :)
クローリングを利用して、人気のコミュニティ投稿だけを収集して表示する「マロン」というアプリを開発し、
全国のグルメ店リストとブログを収集して、グルメ推薦アプリも作りましたね :) (見事に大失敗しましたが..)
現在は人工知能を研究している博士課程の学生です。
全体
20件 ∙ (4時間 31分)
講座資料(こうぎしりょう):
全体
3件
知識共有者の他の講座を見てみましょう!
同じ分野の他の講座を見てみましょう!
新規会員登録で25%OFF
¥5,223
25%
¥6,963
![[PyTorch] NLP を簡単に素早く学ぶ講義サムネイル](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)
![[PyTorch] GAN を簡単に素早く学ぶ講義サムネイル](https://cdn.inflearn.com/public/courses/324945/course_cover/9794a376-0e54-4745-8a1d-3c6fe72b8fe6/pytorch-gan-eng.png?w=420)






![[Rとする]機械学習のための統計学の基礎講義サムネイル](https://cdn.inflearn.com/public/courses/325155/course_cover/d8120723-26f7-4fcc-a25c-a99eef4ea0f6/machine-learning-statistics-r-eng.png?w=420)
![[R] KOSPI/KOSDAQ 全銘柄データの収集および管理講義サムネイル](https://cdn.inflearn.com/public/courses/324972/course_cover/36468a43-de3b-461b-af55-f3c7b0e51637/kospi-kosdaq-data-eng-1.png?w=420)












![[テンソルフロー2] Pythonマシンラーニング完全征服 - マラソン記録予測プロジェクト講義サムネイル](https://cdn.inflearn.com/public/courses/324207/course_cover/1a79c7dc-1624-4d3a-95ff-79ba1e9c4025/python_machine_learning.png?w=420)

![[7日完成] 一発合格するMS AI-900資格証講義サムネイル](https://cdn.inflearn.com/public/files/courses/338854/cover/01k4caartf5v7x2e574pq0wnp8?w=420)








