





ビッグデータ パイプライン マスタ: 成功のためのツールとテクノロジー
jphil
皆さん、ビッグデータ処理の4段階である[データ収集▶データ保存▶データ分析▶表現]について、理論30%+実践70%のコードラボ方式でより楽しく体系的に学習します🧑🏻🏫
初級
Big Data, Elasticsearch, Apache Spark
高可用性(High Availability)が保証されたビッグデータシステムまたは分散処理システムクラスター(HDFS、Zookeeper、Spark、Zeppelin)を自ら構築してみる、コードラボ中心の授業です。
受講生 121名
難易度 初級
受講期間 無制限

学習した受講者のレビュー
5.0
귤껍데기
内容が充実していて、初めて始めるのに良い講義だと思います。このような講義を用意してくださってありがとうございます。
5.0
one831
まもなく卒業を控えた、データエンジニアを志望するコムボールと学生です。 雇用関連ポートフォリオを作成しながら、ビッグデータを処理するためのパイプラインとアーキテクチャをどのように構成し、どのようにaws環境を設定してできるだけ低コストで効率的に利用できるか悩みが多かったが、本講義を通じて膨大なインサイトとノウハウを手に入れます。 特に、ビッグデータを扱うさまざまなフレームワークに関する多くの知識も得られるようになり、今後どのように掘り下げられるのかインスピレーションを得たようで嬉しいです。 干ばつの終わりにダンビーに会いました。私のようにこちらの分野を志望される学生の方に受講おすすめです。
5.0
권영미
ありがとうございます!
ビッグデータクラスターの構築
分散ファイルまたは処理システム
高可用性
Hadoop
HDFS
Apache Spark
Apache Zeppelin
Apache Zookeeper
AWS (EC2, AMI, Security Group)
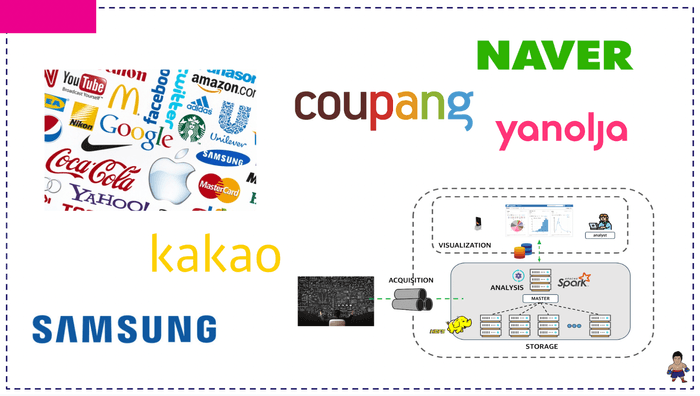
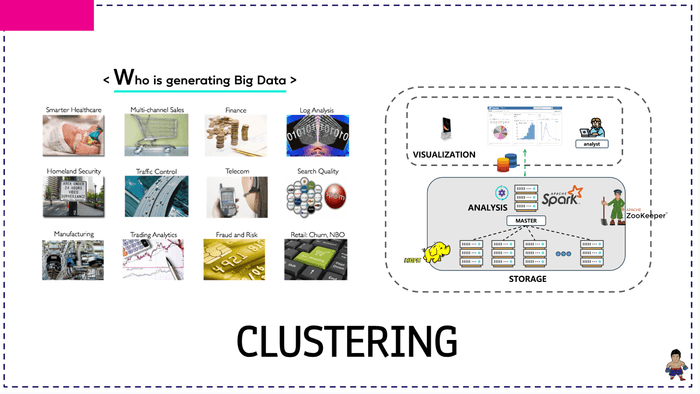
クラスターパッケージを理論としっかりとしたコードラボを通じて、直接構築してみる予定です。

上記の高可用性ファイルシステムデーモンの構成が、少々難しく見えますか?本来、初めて目にするアーキテクチャやシステム構成図というものは、負担に感じて当然のものです。
約6年間にわたる素晴らしい弟子たちの貴重なフィードバックを振り返り、過去にInflearnで2つの講義をローンチした経験をもとに、受講生の皆さんの目線に合わせて一歩ずつ、できるだけ分かりやすく質の高いコンテンツで構成しましたので、安心してついてきてください。
 special thanks to my lovely students 👨🏻🎓
special thanks to my lovely students 👨🏻🎓

すぐにCODELABから始めるのではなく、高可用性クラスターを構築する際に必要な理論から学習します。そして、AWS環境やLinux環境に慣れていない受講生の方々のために、ガイド動画およびバックグラウンド知識を勉強してから、本格的に深層的なコードラボを進める予定です 😎




学習対象は
誰でしょう?
ビッグデータ処理システムのクラスター構築を直接経験したい受講生
データ分析およびシステムに関心があり、職務を希望する学生
高可用性クラスタの実習を直接体験したい開発者
ビッグデータ分析および構築分野で強みを作りたい就活生
前提知識、
必要でしょうか?
Python基礎コーディング
Linuxコマンドの基礎知識
データベースの基礎知識
473
受講生
42
受講レビュー
50
回答
4.9
講座評価
2
講座
最初の講義として、[ビッグデータシステムの構築および分析に関心のある入門者] のために
"Mastering Big Data Processing: Tools and Techniques for Success" 講座をオープンいたしました。
「授業およびプロフィール」の詳細は、授業詳細ページに詳しく記載しましたので、そちらをご参照ください 🙏🏻
全体
36件 ∙ (4時間 51分)
講座資料(こうぎしりょう):
全体
21件
4.8
21件の受講レビュー
受講レビュー 4
∙
平均評価 5.0
5
理論からコードラップまで初期入務者に本当におすすめする講義です! ビッグデータクラスタ構築講義で必須で受講することをおすすめします!
こんにちはYeonwoo Jungさん、 大切な受講評 ありがとうございます。機会があれば、1日2日投資して、AWSで実践に従うことができます。明けましておめでとうございます:)
受講レビュー 2
∙
平均評価 5.0
5
以前はパイプライン講義を聞いて見た講義を聞いていますが、頭の中によく入ってきてとても良いです〜 コンパクトで実務に使われる講義ありがとうございます〜 この講義もすぐに入ってしまいそうですが、他の講義もあるかと期待されます。
2日かかりましたね。 lab形式だからちょっと早く進んで、 namenode 起動ができなくてシャベルするのが難しかったのに(おそらくどこかミスしてそうだった) 後で見たら trouble shoot guide 部分に起動手順スクリプトとログ見る部分整理しておきましたね。これを見たら、もっと早く間違いを修復しました。 もし進んでいる方はみんな追いつくよりは一度精読して従うのもいいと思います~ 講師。良い講義毎回ありがとうございます〜
こんにちはJason.Kingさん、 私の今回の講義を熱心に受講していただきありがとうございます :) 時々バグや trouble shooting を直接体験してみて悩んで見て復活してみるのがたくさん役に立つ時があるのでむしろ今回の経験が今後大きな助けになると思われます。 大規模なオフソースを直接構築してみるとクラスタを構築してみましたので、他のオフソースが出ても今すぐ早く構築することができます。これからもファイティングです
受講レビュー 3
∙
平均評価 5.0
受講レビュー 1
∙
平均評価 5.0
5
まもなく卒業を控えた、データエンジニアを志望するコムボールと学生です。 雇用関連ポートフォリオを作成しながら、ビッグデータを処理するためのパイプラインとアーキテクチャをどのように構成し、どのようにaws環境を設定してできるだけ低コストで効率的に利用できるか悩みが多かったが、本講義を通じて膨大なインサイトとノウハウを手に入れます。 特に、ビッグデータを扱うさまざまなフレームワークに関する多くの知識も得られるようになり、今後どのように掘り下げられるのかインスピレーションを得たようで嬉しいです。 干ばつの終わりにダンビーに会いました。私のようにこちらの分野を志望される学生の方に受講おすすめです。
こんにちはone831、 大切な受講評ありがとうございます、今後も良い結果がありますようにファイティングです
受講レビュー 4
∙
平均評価 4.5
知識共有者の他の講座を見てみましょう!
同じ分野の他の講座を見てみましょう!



![[管理コース#3] DE、DBA(SSIS、SSAS、MachineLearning、BI、ETL)講義サムネイル](https://cdn.inflearn.com/public/courses/329784/cover/c5e6543b-72c3-4471-b43f-15b9002e65ed/329784-eng.png?w=420)


![[データ前処理] 心配しないで!Pandasがあるから。講義サムネイル](https://cdn.inflearn.com/public/files/courses/336824/cover/01k5849rtc0vfa7df3revd2tpb?w=420)

![[リニューアル] 初めてのMongoDB(モンゴDB) と NoSQL(ビッグデータ) データベース ブートキャンプ [入門から活用まで] (アップデート)講義サムネイル](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)



![[2026] SQLD問題が難しいあなたのための黄色本176問題解説講義サムネイル](https://cdn.inflearn.com/public/files/courses/336270/cover/01kfq647gtwqrwbjwbrn9rhn1t?w=420)






![実践しながら学ぶDockerとCI環境 [2023.11 アップデート]講義サムネイル](https://cdn.inflearn.com/public/course-325821-cover/e5a56b04-463b-410c-9b3a-d769cd192add?w=420)