Through in-depth theoretical explanations of Kafka Connect and detailed practical training that can be used immediately in the field, we will help you grow into an expert in building data linkage and data pipelines based on Kafka Connect that are needed in the field.
I've completed the Kafka core course followed by the Connect course. As expected, it was an excellent lecture. If there's one thing that's a bit disappointing, it's that in the latest version, some parameter values need to be modified to complete the hands-on exercises, but since the course includes explanations for all these parts, it's not a big problem. Thank you for creating such a great course and sharing your knowledge.
5.0
행복한 족제비
100% enrolled
Korea's Best Kafka Course
5.0
잉여인간
100% enrolled
The lecture materials were well-prepared, so there were no problems during the practice sessions.
I really enjoyed the course.
What you will gain after the course
Core Mechanisms of Kafka Connect's Key Components
Understanding CDC(Change Data Capture) and practical application techniques
Understanding MySQL Data Replication and CDC (Change Data Capture) and Practical Application Methods
Core Mechanisms and Features of the Debezium CDC Source Connector
Inter-RDBMS Data Integration Using Debezium CDC Source Connector
Know-how on building a Debizium Connect-based linkage system
Setting up and running JDBC-based Source Connector and Sink Connector environment
Application of various SMT classes for message conversion
Managing connections using REST API
Utilizing the Schema Registry and integrating with Connect
Managing schema registry using REST API
Connect for Apache Kafka Practices, From principles to practical applications, everything is clear!
For powerful real-time data linkage Kafka Connect.
The best open-source solution for real-time integration between diverse data systems!
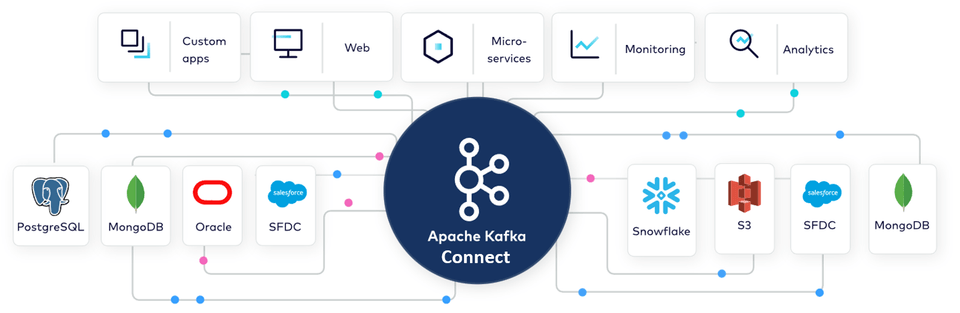
Kafka Connect allows you to easily, quickly, and reliably build real-time data connections between various systems through pre-built connectors without any separate coding implementation.
Many companies overseas have already adopted Kafka Connect, and in Korea, as Kafka Connect is utilized for integration between heterogeneous data systems and the construction of enterprise data pipelines, demand for talent with practical Kafka and Kafka Connect skills is growing. Unfortunately, however, learning materials for Kafka Connect remain scarce. Books, materials, and lectures offer only basic and superficial information, making it difficult to cultivate individuals with the practical skills required for practical work.
We will guide you to grow into the Kafka Connect expert you desire in the field.
detailed Mechanism Description
Practical level Various examples
Issue Resolution OK to the room
This course covers Kafka Connect at a level of detail and practicality unmatched in any other lecture or book. Through a detailed explanation of the mechanisms of Kafka Connect's core components and numerous hands-on examples that demonstrate various data integration and operational management using Connect , we aim to help you grow into a Kafka Connect expert in demand in the field .
Above all, you will be able to master Kafka Connect data integration based on CDC.
Most enterprises' core data systems are RDBMSs. Real-time integration of physically separate databases is now dominated by Change Data Capture (CDC) . CDC is an excellent data integration technique that enables real-time integration of large amounts of data without delay while minimizing system load. Debezium Connector is a leading CDC solution that utilizes Kafka Connect to enable data integration between different RDBMSs.
Many companies are demanding talent capable of handling CDC-based connections. Therefore, this course will provide a detailed theoretical and practical explanation of the mechanisms of CDC and Debezium Connectors, their configuration and implementation, as well as various issues and solutions that may arise when applying Debezium in production.
Unique features of this course Check it out.
Understanding the key components of Kafka Connect through detailed explanations and hands-on practice.
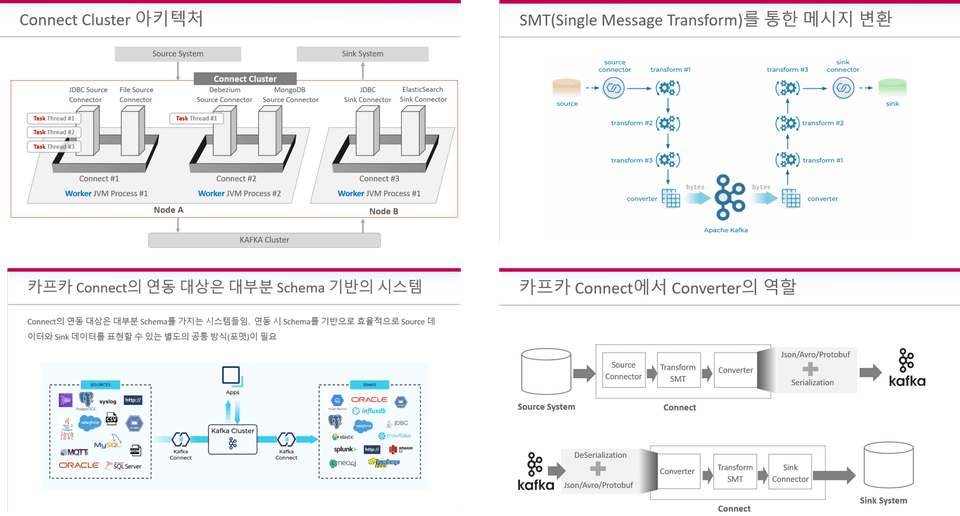
We will provide you with detailed explanations and hands-on practice to acquire core fundamental knowledge on Connect Clusters, Connectors, SMT (Single Message Transform), Converters, and more, enabling you to utilize them freely.
Environment configuration and operation practice for various connectors
We help you build a Kafka-based, practical data linkage system through various connector configuration parameters, internal mechanisms, and various application practices that can be applied to the RDBMS operating environment, such as SpoolDir Source, JDBC Source/Sink, and Debezium Source Connector.
A detailed explanation of the Debizium CDC Source Connector mechanism, various practical exercises, and potential issues and solutions!
We've covered a lot about the Debezium CDC source connector. We'll provide a detailed guide on how to build real-time connectivity between disparate RDBMSs in an RDBMS production environment using Debezium CDC and the JDBC Sink Connector.
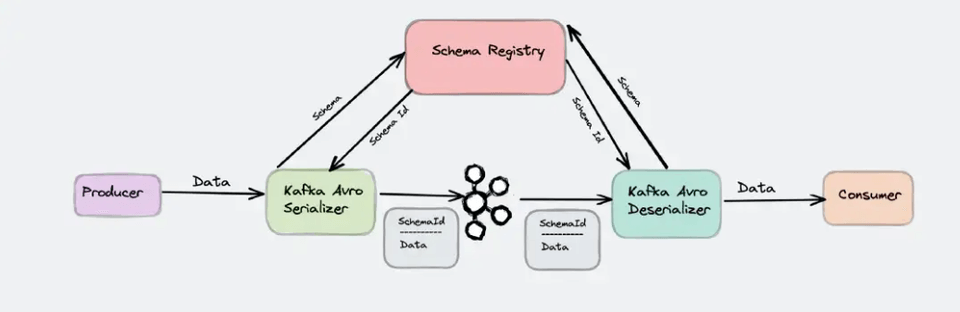
Understanding and Utilizing Avro and the Schema Registry
We'll cover in detail the transfer and central management of schema data through Connect, Avro, and the Schema Registry, as well as schema compatibility, which is crucial in practice. Through this, you'll learn how to integrate Connect and the Schema Registry to build efficient enterprise data integration and data pipelines, which are essential in practice.
Managing Connect and Schema Registry via REST API
You will learn how to create/modify/delete/manage key elements of Connect and Schema Registry through various REST APIs.
Bonus for Kafka Connect Masters!
We provide a 200-page course textbook to all students. We hope it will help you learn Kafka Connect.
Practice Environment 💾
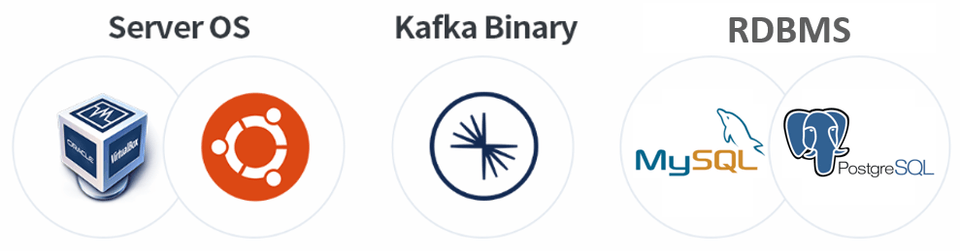
Server OS
The Kafka server OS is Ubuntu Linux 20.04, running on an Oracle VirtualBox VM. Although it uses Linux, it runs on a virtual machine, making it suitable for both Windows and macOS environments.
VirtualBox can be installed on most Windows and macOS platforms. However, for Macs, VirtualBox is not installed on the latest M1 models. Therefore, you must install Ubuntu using a virtual environment such as UTM. For M1 models, please ensure that Ubuntu can be installed in a virtual environment before selecting a course.
Confluent Kafka Community Edition
Kafka uses Confluent Kafka Community Edition version 7.1.2, not Apache Kafka.
Confluent, founded by the core team behind Kafka, provides enterprise-grade Kafka with enhanced performance and convenience for enterprise customers. It offers 100% compatibility with Apache Kafka while also offering access to a wider range of Kafka modules and integrated binaries. With Confluent, you can leverage the powerful distributed Kafka system in a more elastic and scalable form. This reduces infrastructure deployment and maintenance burden and accelerates development.
RDBMS
Although file data linking is also provided as a practice, such as with the Spooldir Source Connector, most of the Connect practice linking is centered around data linking between RDBMSs.
In particular, many exercises use the same MySQL database for both Source and Sink. The Source uses MySQL, while the Sink uses PostgreSQL. The versions used in these exercises are MySQL 8.0.31 and PostgreSQL 12 .
Recommended PC Specifications
A full lab environment configuration may require a PC environment with 20-30GB of storage capacity and 4GB or more of RAM .
Check out the Q&A 💬
Q. Why should I learn Kafka Connect?
Kafka Connect is a core component for Kafka-based data integration . Many companies that have already adopted Kafka are effectively leveraging Kafka Connect to easily build large-scale data pipelines.
Kafka Connect is used to interconnect heterogeneous data systems, including major RDBMSs such as Oracle, MySQL, and PostgreSQL, as well as NoSQL systems such as MongoDB and ElasticSearch, and DW systems such as RedShift, SnowFlake, Vertica, and Teradata, through over 120 different connectors.
Kafka Connect allows for easy interconnection/integration of heterogeneous data systems without the need for separate coding implementation. In particular, its use and utilization are increasing in many companies due to its advantages such as reduced interconnection S/W costs through Community license and real-time interconnection of large amounts of data without delay based on CDC.
If you master Kafka Connect through this course, you will be able to take a step forward as a Kafka expert that companies want.
Q. Should I take the previous lecture, "Kafka Complete Guide - Core"?
It would be better if you took the previous lecture, Kafka Complete Guide - Core Edition, but even if you didn't take the lecture, if you have a good understanding of the basic concepts of Kafka, such as Broker, Producer, and Consumer, and have experience applying Kafka message sending and reading, you can sufficiently take this lecture.
Q. Do I need to have RDBMS experience to take this course?
Unfortunately, this course requires at least 3 months of RDBMS experience . You can do most of the lecture exercises if you just understand the basics of RDBMS table and column alteration creation. However, if you do not have some experience with RDBMS, you may find the exercises difficult, even though the lecture explains CDC and RDBMS replication in detail.
Recommended for these people
Who is this course right for?
Anyone who wants to understand the internal mechanisms of Kafka Connect and apply them in practice
Data engineers or architects who want to build a data pipeline and understand CDC-based data architecture
DBAs or system administrators who need to operate JDBC or Debezium CDC Connector
DW developer considering ETL and DB linkage through real-time synchronization of operational DB
Developers and architects considering CDC-based data linkage when configuring microservice-based architecture
Need to know before starting?
Basic knowledge of Kafka Broker, Producer, and Consumer
More than 3 months of RDBMS development or operation experience
It was a great lecture. I've gained a basic understanding of the overall connect mechanism, as well as DBMS Replication through MySQL and PostgreSQL. Thank you :)
Personally, I highly recommend reading "Kafka: The Definitive Guide" (the core part) before taking this lecture! There's a noticeable difference in the questions asked on the Q&A board between those who have read the core part and those who haven't.
I was working on a project that required me to synchronize a database with Kafka, and I was completely lost. But thanks to Kwon Cheol-min's lecture, which I used as a cheat code, I was able to successfully apply it to the project and complete it. Thank you so much.
MariaDB -> PostgreSQL PostgreSQL -> MariaDB
I've completed the Kafka core course followed by the Connect course. As expected, it was an excellent lecture. If there's one thing that's a bit disappointing, it's that in the latest version, some parameter values need to be modified to complete the hands-on exercises, but since the course includes explanations for all these parts, it's not a big problem. Thank you for creating such a great course and sharing your knowledge.
















![[Revised Edition] Deep Learning Computer Vision: The Complete GuideCourse Thumbnail](https://cdn.inflearn.com/public/courses/325035/cover/f4bbef4d-d9a9-4def-a3a5-738a9eed8245/325035-eng.jpg?w=420)










![[Revised Edition] The Complete Guide to Python Machine LearningCourse Thumbnail](https://cdn.inflearn.com/public/courses/324238/cover/7e380aa0-48ba-4ee7-a6b2-8da7900568d6/324238-eng.png?w=420)






![[Renewed] MongoDB and NoSQL (Big Data) Database Bootcamp for Beginners [From Introduction to Application] (Updated)Course Thumbnail](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)




![Learning Docker and CI Environments by Following Along [Updated 2023.11]Course Thumbnail](https://cdn.inflearn.com/public/course-325821-cover/e5a56b04-463b-410c-9b3a-d769cd192add?w=420)





