




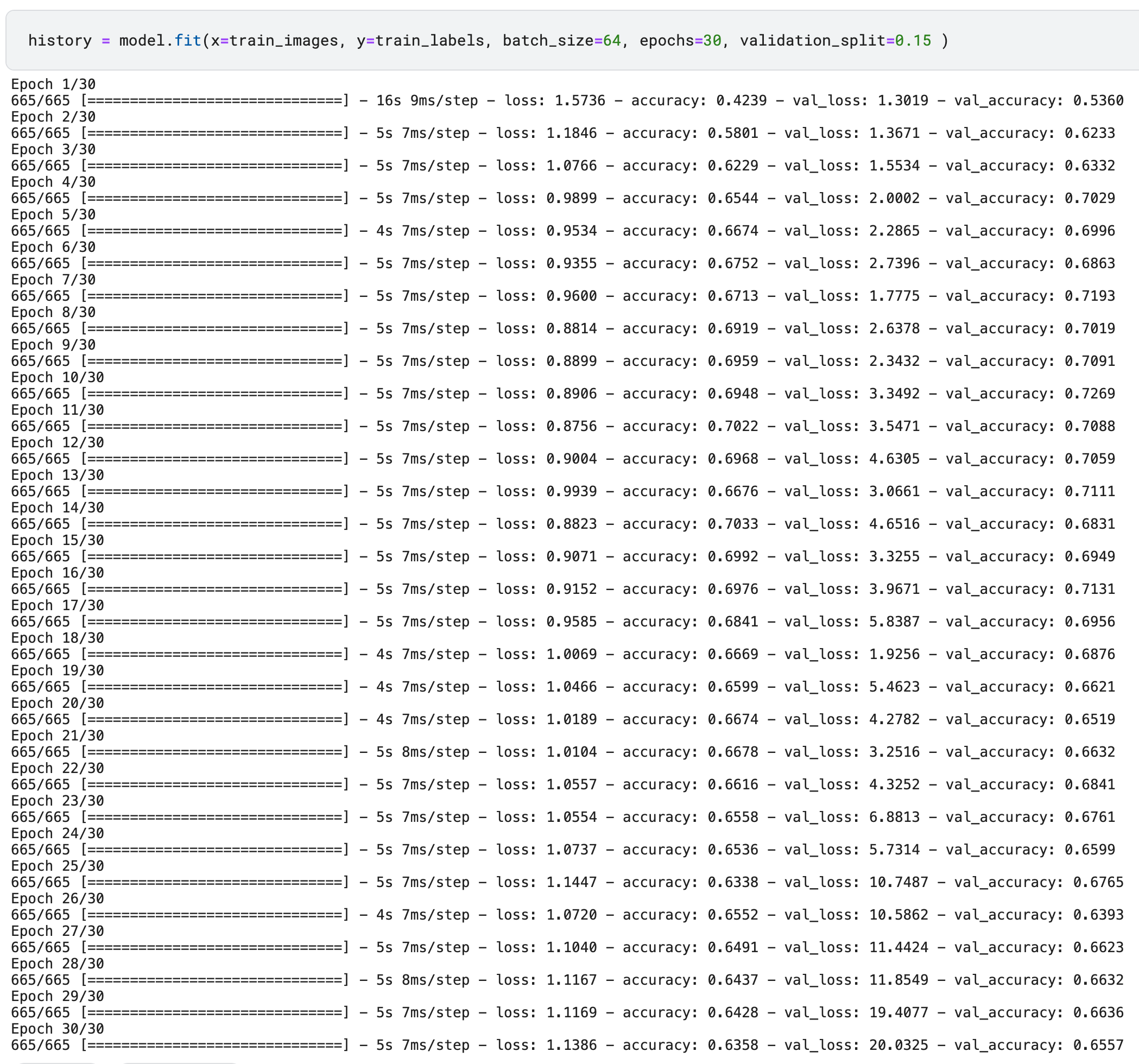
val_loss값이 계속 커지는 현상이 왜 나오나요?
830
작성한 질문수 5
안녕하세요.
코드를 타이핑하며 실행해 보는데, 강의 화면과는 달리 vla_loss값이 점점 커지는 결과가 나왔습니다.
처음에는 제가 타이핑을 잘못해서 그런가 했는데, 선생님이 제공해주신 코드를 그대로 실행해도 비슷한 결과가 나왔습니다.
여러 번 런타임을 재실행하고 해봐도 마찬가지입니다.
왜 이런 현상이 나타나나요?
(kaggle에서 실행했습니다)
답변 2
0
안녕하십니까,
저도 테스트를 해보는데, 현재 Tensorflow version 2.12로 해보면, 강의를 만들었을 때와 다르게 검증 데이터에서 오락가락(?)하는 부분이 있군요. 이건 좀 더 테스트가 필요할 것 같습니다.
좀 더 테스트 해보고 답변 드리도록 하겠습니다.
kjyn0124 님도 답변 감사합니다.
0
먼저 현재 tensorflow 2.12에서는 강의 실습 화면과 다르게 모델의 검증 데이터 평가 지표가 오락 가락합니다.
일단 kaggle에서 tensorflow 버전을 아래와 같이 2.8로 downgrade 해서
!pip install tensorflow==2.8.0
이후 아래와 같이 버전이 2.8로 나오는지 확인해 주십시요.
from tensorflow as tf
print(tf.__version__)
2.8에서는 성능이 괜찮게 나오는데 2.12에서는 왜 그런지 아직 원인을 찾지 못했습니다. 여러가지로 테스트 중인데, 원인 파악에 시간이 좀 더 필요할 것 같습니다. 일단은 2.8로 강의 수강을 진행 부탁드립니다.
0
y 값으로 one-hot encoding 된 label인 train_oh_labels를 넣으셔야 하는데 그냥 train_label을 넣으셔서 생긴 문제 같습니다. 그래서 val_loss 뿐만 아니라 loss 값도 커지고.... 제대로 학습이 이뤄지지 않고 있는 듯 합니다.
0
답변 감사합니다.
이번 코드는 원핫인코딩을 하지 않은 것이라 loss 함수로 sparse_categorical_crossentropy를 사용했습니다.
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
강의 중에
원핫인코딩 → categorical_crossentropy
인코딩 안하면 → sparse_categorical_crossentropy
사용하라고 하셨는데, 둘 간의 성능 차이가 있나요?
resize 질문
0
60
1
20251212 Kaggle 런타임에 scikit-learn 설치 실패 트러블 슈팅
0
86
1
Loss와 매트릭 관계
0
77
2
Boston 코랩 실습
0
171
2
배치 정규화의 이해와 적용 2 강의 질문
0
144
2
Augmentation원본에 적용해서 데이터 갯수 자체를 늘리는 행위는 의미가있나요?
0
151
2
Conv함수 안에 activation 을 넣지 않는 이유가 뭔지 궁금합니다.
0
213
2
소프트맥스 관련 질문입니다
0
215
1
강의 관련 질문입니다
0
161
2
residual block과 identity block의 차이
0
200
2
옵티마이저와 경사하강법의 차이가 궁금합니다.
1
251
1
실습 환경
0
171
2
입력 이미지 크기
0
256
2
데이터 증강
0
203
2
albumentations ShiftScaleRotate
0
211
1
Model Input Size 관련
0
294
1
마지막에 bird -> frog 말고도 deer -> frog 도 잘못된것 아닌가요??
0
206
1
일반적인 질문 (kaggle notebook사용)
0
276
2
실무에서 Augmentation 적용 시
0
347
2
안녕하세요 교수님
0
235
1
가중치 초기화(Weight Initialization) 질문입니다.
0
332
1
테스트 데이터셋 predict의 'NoneType' object has no attribute 'shape' 오류
0
412
1
학습이 이상하게 됩니다.
2
1041
2
boston import가 안됩니다
0
230
1