




Yahoo Finance에서 URL 가져오기
644
작성한 질문수 3
이 강의를 듣고 나면 네이버금융 뿐만 아니라 다른 웹 스크래핑도 가능할 것이라 하셨는데, 처음부터 너무 막히니 속상하네요. 스크립트는 다음과 같습니다.
import pandas as pd
from bs4 import BeautifulSoup as bs
url = f"https://finance.yahoo.com/quote/YM%3DF/history?p=YM%3DF"
table = pd.read_html(url)
response = requests.get(url, headers = headers)
html = bs(response.text)
table = html.select("table")
temp = pd.read_html(str(table))
temp[0]
여기서 url부터 인식을 못하고 HTTPError가 뜹니다. 해결방법이 있을까요?
HTTPError: HTTP Error 404: Not Found
답변 1
0
import pandas as pd
from bs4 import BeautifulSoup as bs
url = f"https://finance.yahoo.com/quote/YM%3DF/history?p=YM%3DF"
table = pd.read_html(url) <= 이 부분 제거가 필요합니다.
response = requests.get(url, headers = headers)
html = bs(response.text)
table = html.select("table")
temp = pd.read_html(str(table))
temp[0]
1) headers 가 있는데 다른곳에서 선언해 준것인가요?
2) 오류가 나는 문장이 중간에 있으니 한 줄 한 줄 해보세요.
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
headers = {"user-agent": "Mozilla/5.0"}
url = f"https://finance.yahoo.com/quote/YM%3DF/history?p=YM%3DF"
response = requests.get(url, headers = headers)
html = bs(response.text)
table = html.select("table")
temp = pd.read_html(str(table))
temp[0]
잘 가져와집니다.
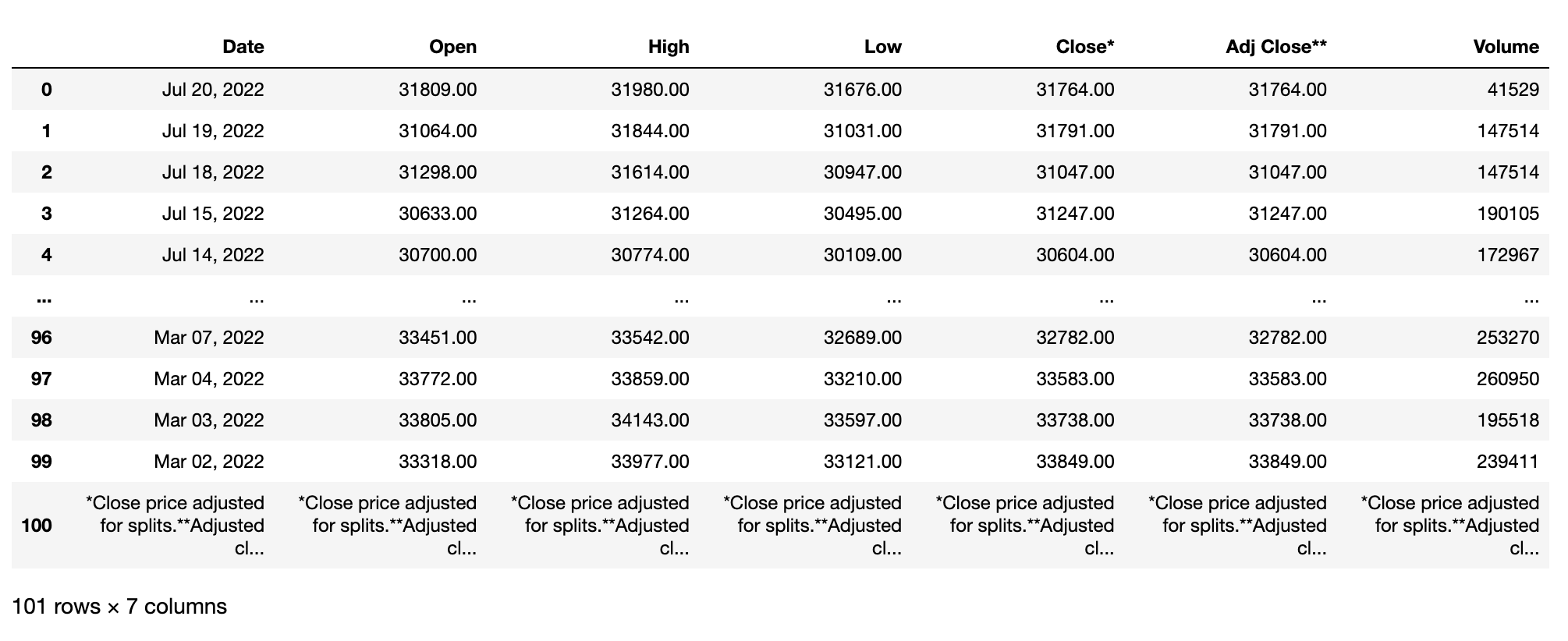
cufflinks 버전문제로 iplot() 미실행
0
60
2
[수정요청]직접 수집한 주가 데이터로 시각화해보기
0
73
2
pd.read_html(url, encoding='cp949') 에러
0
98
2
fdr.StockListing('KRX') 문제 발생
0
184
2
주식 자동매매 프로그램 제작 관련 조언 부탁드립니다
0
460
1
concat 을 통한 데이터 프레임 합치기 에러 문의
0
119
2
한글폰트 관련해서 문의드립니다.
0
251
2
데이터프레임 칼럼명 문의 드립니다.
0
254
3
금융데이터 수집의 모든것
0
160
2
녹화시점과 현재시점 컬럼명이 변경이 많이 되었을까요?
0
203
2
파이썬 증권 데이터 수집과 분석으로 신호와 소음 찾기 - 섹션1 [2/2]
0
182
1
Mac 환경에서 nbextensions 활성화 하는 방법
0
607
2
pd.concat(result.tolist()) 오류 문의
0
260
1
5.1 제약 데이터 수집 오류 해결
0
247
1
Table of contents 문의드립니다
0
224
2
concat을 통한 데이터프레임 합치기
0
562
2
Reindexing only valid with uniquely valued Index objects 오류 질문입니다.
0
500
1
데이터 비교시 데이터 불일치
0
425
1
dtype={"itemcode": np.object}) 을 dtype={"itemcode": object}) 으로 변경해야 하나요?
0
609
1
질문 : for문 풀어쓰기
0
503
1
파이참에서 Plotly 그래프 실행방법
0
1325
1
5.1 데이터프레임 병합(merge)
0
754
2
쥬피터노트북에서 실행파일 만들기
0
1462
1
주피터노트북 확장팩 설치가 안됩니다.
0
574
2