




split 옵션 문의.
333
작성한 질문수 53
안녕하세요 강사님.
원본데이터에는 공백이 하나인데, split 할때 공백울 2개씩 넣어줘야하는 이유가 있나요?
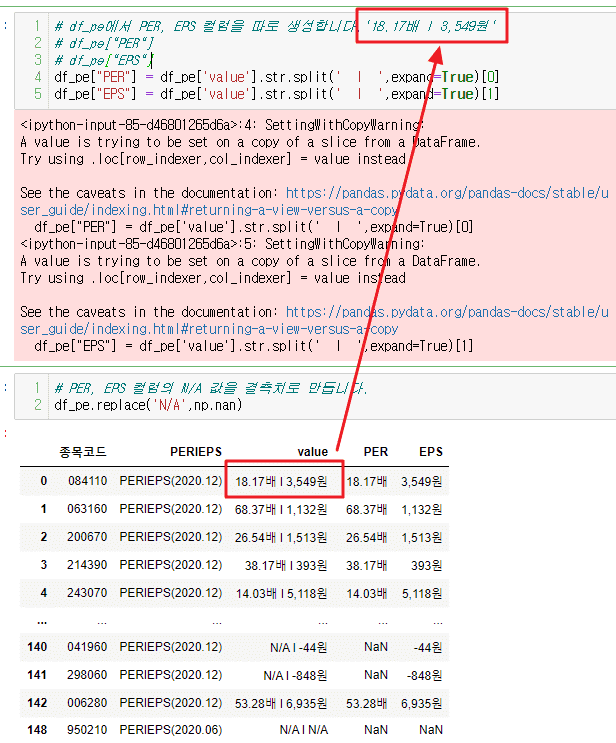
원본 데이터 '18.17배 l 3,549원'
df_pe["PER"] = df_pe['value'].str.split(' l ',expand=True)[0]제가 복사해서 텍스트 에디터에서 확인하면 공백이 하나입니다. 혹시 복사해서 보면 다르게 보이는건가요?
여기서 공백을 하나만 넣어도 분리는 되지만 다음 결측치 제거에서 공백때문에 공백처리를 한번더 해야합니다.
답변 2
1
빠른 답변 감사합니다.
원인을 찾았습니다. 원인이라기 보다는 현상이라고 생각됩니다. 시리얼로 출력하는것과 dataFrame 으로 출력하면 결과가 다릅니다.
다른 분들도 아시면 좋을거 같아서 공유합니다.
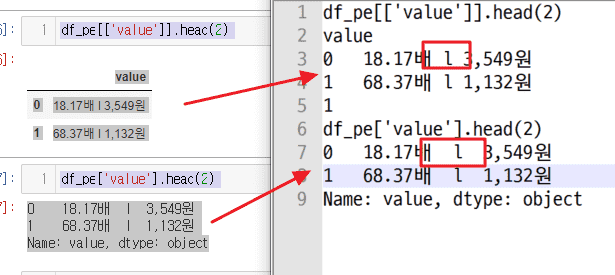
하나는 데이터프레임으로 출력하고 하나는 시리얼 로 출력해 보았습니다. 주피터 내용을 복사해서 텍스트 에디터에 붙여보니 공백이 차이납니다. 데이터 프레임은 공백이 1개로, 시리얼은 공백이 2개로 보여집니다. 그래서 원본 csv 파일을 열어보니, 원본 파일에는 공백이 2개 있는게 맞습니다.
제 환경의 문제일수도 있습니다만, 주피터에서 그렇게 보여주는거 같습니다.
0
안녕하세요. 공백 문자가 눈에 잘 보이지 않아 혼란이 될것 같아요.
데이터를 전처리 하다보면 이렇게 잘 보이지 않는 공백 문자 때문에 고생을 할 때가 종종 있는데요.
시리즈 형태이든 데이터프레임이든 내부의 공백이 변경되지는 않아요.
정확하게 확인해 보기 위해 "배" 라는 문자 기준으로 문자열을 잘라서 아래와 같이 확인해 보면 공백문자가 2개 들어 있습니다.

문자열을 가져와서 인덱싱 하는 방법으로 공백문자가 있는지를 알아봤습니다.
1
안녕하세요.
원본에 공백이 하나라면 공백을 하나만 넣어도 되지만 두 개라면 나중에 다시 공백을 제거해야 하는 수고가 있기 때문에 두 개를 넣어준다면 제거 되지 않은 공백을 다시 제거하지 않아도 되기 때문에 텍스트의 공백을 그대로 복사해서 사용했어요.
질문해 주신대로 공백을 하나만 사용하고 나중에 str.strip() 등으로 제거되지 않은 공백을 제거해도 됩니다.
공백문자는 눈으로 잘 보이지 않기 때문에 복사해서 그대로 사용하는걸 추천해요.
cufflinks 버전문제로 iplot() 미실행
0
70
2
[수정요청]직접 수집한 주가 데이터로 시각화해보기
0
80
2
pd.read_html(url, encoding='cp949') 에러
0
134
2
fdr.StockListing('KRX') 문제 발생
0
200
2
주식 자동매매 프로그램 제작 관련 조언 부탁드립니다
0
468
1
concat 을 통한 데이터 프레임 합치기 에러 문의
0
130
2
한글폰트 관련해서 문의드립니다.
0
269
2
데이터프레임 칼럼명 문의 드립니다.
0
266
3
금융데이터 수집의 모든것
0
174
2
녹화시점과 현재시점 컬럼명이 변경이 많이 되었을까요?
0
230
2
파이썬 증권 데이터 수집과 분석으로 신호와 소음 찾기 - 섹션1 [2/2]
0
191
1
Mac 환경에서 nbextensions 활성화 하는 방법
0
615
2
pd.concat(result.tolist()) 오류 문의
0
285
1
5.1 제약 데이터 수집 오류 해결
0
254
1
Table of contents 문의드립니다
0
227
2
concat을 통한 데이터프레임 합치기
0
577
2
Reindexing only valid with uniquely valued Index objects 오류 질문입니다.
0
510
1
데이터 비교시 데이터 불일치
0
437
1
dtype={"itemcode": np.object}) 을 dtype={"itemcode": object}) 으로 변경해야 하나요?
0
615
1
질문 : for문 풀어쓰기
0
513
1
파이참에서 Plotly 그래프 실행방법
0
1333
1
5.1 데이터프레임 병합(merge)
0
772
2
쥬피터노트북에서 실행파일 만들기
0
1467
1
주피터노트북 확장팩 설치가 안됩니다.
0
588
2