




model.fit에러
작업형2 기출2회 풀다가 에러가 생겨서 문의드립니다.
원인이 뭘까요...ㅠ
from sklearn.ensemble import RandomForestClassifier
model= RandomForestClassifier(random_state=200)
model.fit(X_tr,y_tr)
pred=model.predict_proba(x_val)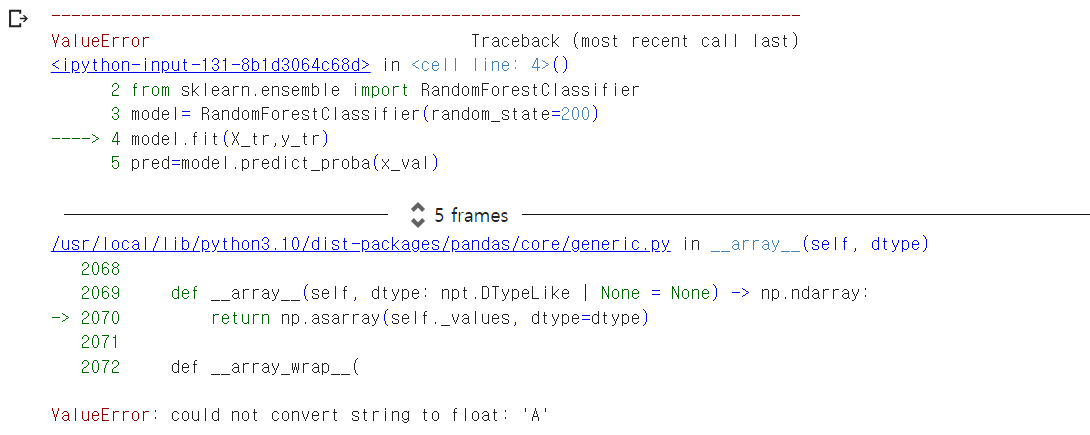
[전체코드]
import pandas as pd
X_train=pd.read_csv('X_train.csv')
y_train=pd.read_csv('y_train.csv')
X_test=pd.read_csv('X_test.csv')
X_train=X_train.drop(['ID'], axis=1)
IDX=X_test.pop('ID')
from sklearn.preprocessing import LabelEncoder
la=LabelEncoder()
cols=['Mode_of_Shipment','Product_importance','Gender']
for col in cols:
X_train[col]=la.fit_transform(X_train[col])
X_test[col]=la.transform(X_test[col])
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val=train_test_split(X_train,
y_train['Reached.on.Time_Y.N'],
test_size=0.2,
random_state=200)
# 모델링
from sklearn.ensemble import RandomForestClassifier
model= RandomForestClassifier(random_state=200)
model.fit(X_tr,y_tr)
pred=model.predict_proba(x_val)
답변 2
0
다시확인해보니 라벨인코딩할때, Warehouse_block 컬럼을 빠뜨려서 다시추가해주고 돌렸습니다.
그런데, 그래도 다음과 같은 에러가 뜹니다...
ValueError: could not convert string to float: 'D'
1
오 해결했습니다.
pred=model.predict_proba(x_val)에서 X_val으로 써야하는데 잘못썻네요...
시험장에서 model.fit 에러시에 기존 라벨인코딩에서 object 누락된것이 있는지 확인해 보겠습니다~
추가질문 합니다
0
7
1
시험환경 구름
0
8
1
2유형 질문드려요
0
7
1
RandomForest vs lgb
0
18
1
전처리 관련질문
0
12
2
작업형3 기출
0
12
1
유형2에서 데이터분할 생략 가능여부
0
20
2
9회 기출 유형3 질문
0
15
1
lgb 기초편
0
10
1
괄호 사용
0
15
1
작업형 2 데이터 전처리 질문
0
18
1
11회 기출 유형 작업형1 문제 3-1
0
13
0
예시문제 작업형2 (ver2023) 질문입니다
0
16
1
Data type에 따른 처리
0
15
2
데이터 전처리 관련
0
15
2
시험에서 문제 불러오기
0
18
2
2번문제 출력값 질문
0
20
2
pd.get_dummies()가 bool로 반환
0
18
2
대응표본검정 레빈
0
23
3
단일표본검정 문제 유형
0
23
2
[작업형 3] 6~7. 카이제곱 검정
0
22
2
9회 작업형3 문제 1-1
0
37
2
최종답안 계산 방식 질문
0
25
1
시험 치기 전 급하게 질문 사항
0
41
2