




파이프라인설계관련질문있습니다(8승파이프라인)
682
작성한 질문수 3
답변 2
1
안녕하세요 :)
어.. 제가 질문을 이해를 못하고 있는 상황입니다.
+ 어디를 어떻게 설명해야 할지 모르겠어요.
구체적으로 적어주시면 안될까요? ㅠㅠ
아래 글은 적다가 말았습니다. (뭔가 적고 싶었는데....... 못적겠어요.)
============================================
머신러닝 학습에서의 예시라.. 설명하기 어렵네요. (보통 학습이 아니고, Inference 할때 사용할텐데.. 어떤 상황을 원하시는 건가요? 자세히 적어주세요.)
우선 Pipeline 을 원리를 먼저 이해해 보시는 것이 좋을 것 같아요. 이해가 되었다면 나머지는 응용의 영역이라...
============================================
8승자체를 2승-2승-2승 모듈을 연결하여 OUTPUT이 8승이 되도록 2승모듈을 연결하고 각각의 모듈들이 2승씩 클락에 따라 병렬로 계속 연산이 되는것은 이해하였습니다.
제가 이해하고있는것은 목표한 계산(y)을 나누어 병렬적으로 수행할 수 있다..!
-> 이거는 Parallelize 관점이라, Pipeline 하고는 무관합니다.
다음 그림을 보시면, Cycle 1,2,3 은 시간 관점입니다.
Cycle 1,2,3 이 병렬로 존재하는 모듈이 아니구요.
Fetch / Decode / Excute ADD / SUB / CMP 부분을 2승 / 2승/ 2승 이렇게 치환해서 보시면
완벽하게 동일한 그림이 됩니다. 즉 다음 그림은 Pipeline 입니다.
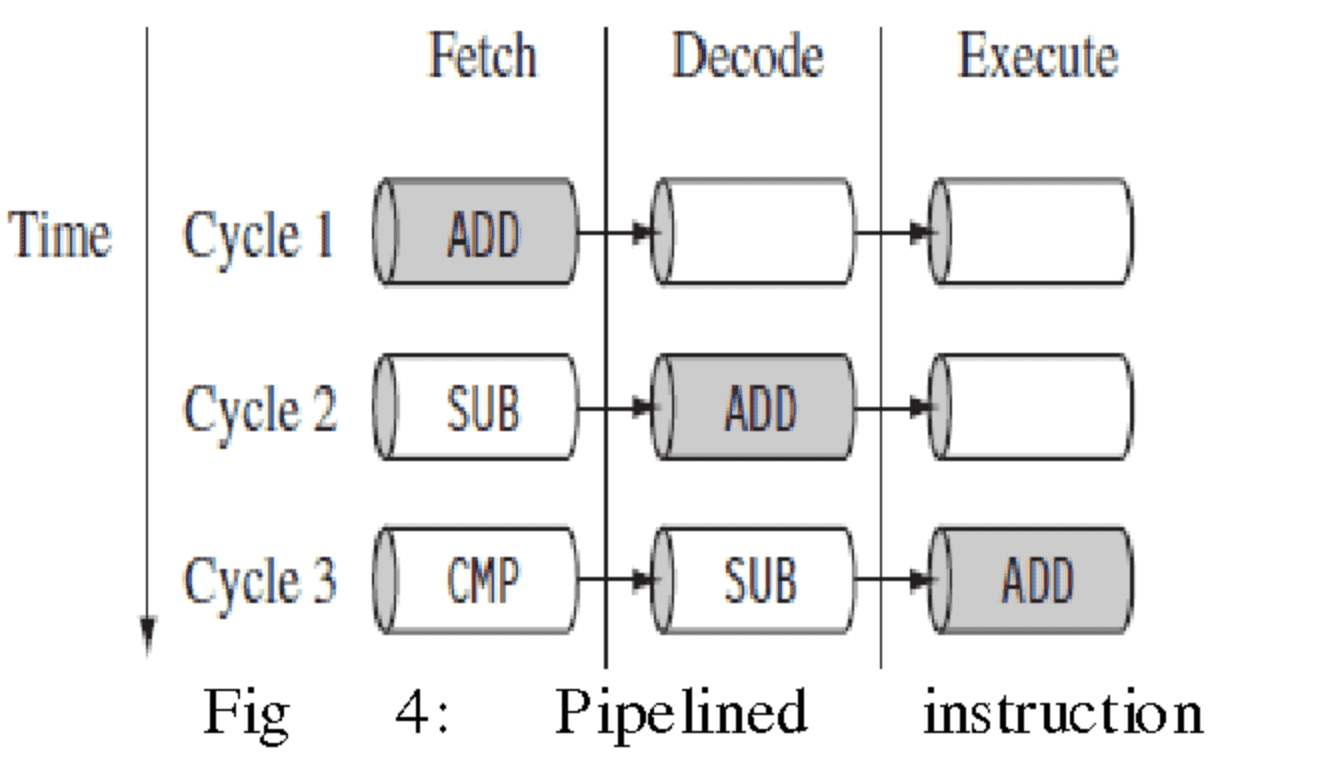
이게 무슨 장점이 있는가 하면, 8승을 계산한다고 가정해 보겠습니다.
2승 을 계산하는 시간은 10 ns 가 걸린다고 가정해볼께요. 그럼 8승을 계산하는 시간은 30 ns 겠죠?
Case 1.
원래 1 cycle 에 8 승을 한번에 계산하면 됩니다. 그럼 30 ns 마다 8 승의 결과 값이 나와요.
Case 2.
하지만 만약에 Pipeline 의 원리를 적용해서 계산한다고 해볼께요. (저의 영상처럼 2 승씩 나누면요)
그러면 (그리기 힘들었습니다.. ㅎㅎ)
2승 |10ns | 10 ns | 10 ns | 10 ns| 10 ns
2승 | 10 ns | 10 ns | 10 ns| 10 ns
2승 | 10 ns | 10 ns| 10 ns
결과 (8승) | 결과 | 결과 | 결과 |
첫번째 Data 는 30 ns 뒤부터 결과 값이 나옵니다. 대신 10ns 마다 8승의 결과를 얻을 수 있습니다.
자....!
Case 1 은 8승의 결과를 얻는데, 30ns 마다 1개씩
Case 2 는 8승의 결과를 얻는데, 10ns 마다 1개씩
Case 1 하고, Case 2 하고 연산기의 수가 다른가요? 동일합니다. 연산기의 수를 늘린다 is Parallelize
Case 2 가 바로 Pipeline 입니다. 이 원리로 Performance 가 향상이 됩니다.
원리는 중간에 10ns 단위로 값을 저장할 수 있는 F/F 이 존재했기 때문입니다. ( 실제 배수관을 생각해보세요. 집에서 물 틀자마자 나오자나요?)
결국 이 원리로 HW 를 구현하시면 됩니다.
어디다가? 모든 곳에다가
git hub 404 error 도움 부탁드립니다.
0
7
1
latency 개념 구현
1
127
3
비바도 all os버전
1
96
2
초기화를 reset_n 이 '1'일 때가 아닌 '0' 일 때 실행시키는 이유 질문
1
101
2
다운로드용량
1
82
2
비바도리눅스설치
1
100
2
전체path복사넣기
1
75
2
Vivado 2025.2 리눅스 설치 후 실행 에러와 솔루션 (libxv_commontasks.so)
1
192
2
explorer.exe오류
1
121
3
mobaxterm설치오류
1
103
2
./build시, waveform 'divide color' 사용
1
62
2
Latch와 관련하여 (Time borrowing, Latch-based design)
1
153
2
clean 명령어가 안되는데, 따로 저장해줘야 하는지 궁금합니다.
0
73
1
안녕하세요 설치 관련 질문 드립니다.
1
73
3
16장 mealy 설계.
1
83
2
14장 Cycle 관련, Testbench 코드.
1
75
2
21강(16장) 초기값 설정이 적용되는 시점 질문
1
68
1
20강(15장) - 밀리 머신 관련하여 질문 드립니다.
1
77
2
build에러 질문
0
63
2
1장 ./build에서 에러가 나요
1
83
2
FPGA 강의 보드 문의 드립니다.
1
122
2
5장 DFF특성에 대한 질문
1
88
3
vivado linux 사용 이유.
1
155
2
메모리의 형태가 전체설계에 미치는 영향이 궁금합니다.
1
114
2