





Developing LLM Applications Using RAG (feat. LangChain)
jasonkang

RAG. Learn from Silicon Valley GenAI Hackathon Winner. Packed with real-world know-how.
Basic
LLM, RAG, LangChain


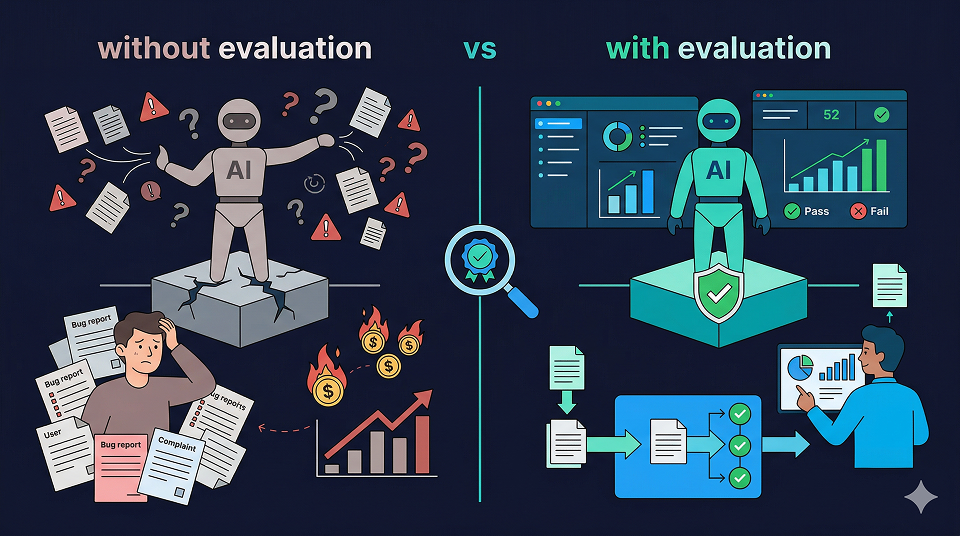
There is only one reason why we hesitate.
When we change prompts, models, or logic,
we lack the confidence that the overall performance will truly improve.



Ultimately,


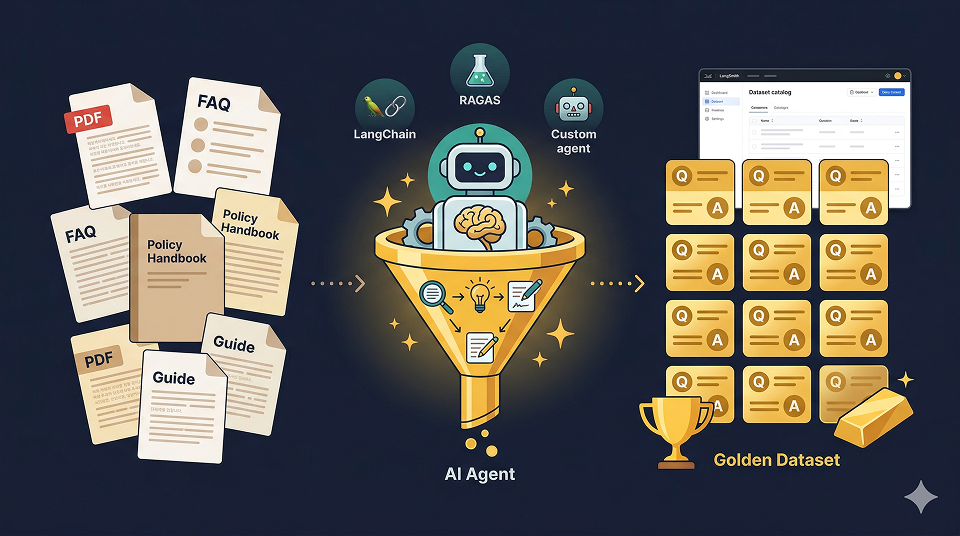
Automatically generate question-answer QA datasets

Generate domain-specific data with custom prompts and tools

Expanding small-scale data into large-scale datasets



FAANG Senior Software Engineer
(Former) GS Group AI Agent platform development/operations
(Former) GS Group DX BootCamp Mentor/Coach
(Former) FAANG Senior Software Engineer (Former) GS Group AI Agent Platform Development/Operations (Former) GS Group DX BootCamp Mentor/Coach
(Former) Tech Lead at a Series C AI Startup
Stanford University Code in Place Python Instructor
Naver Boostcamp Web/Mobile Mentor
Naver Cloud YouTube Channel presenter
Author of Building Autonomous AI Agents with LangChain & LangGraph

Wanted Pre-onboarding Frontend/Backend Challenge Instructor (6,000+ cumulative participants)
Hanghae AI Plus Course 1st Generation Coach
Jason's courses are ones I always trust and sign up for. I have taken all of the instructor's LangChain-related courses, and thanks to them, I am currently working as a junior AI Engineer. I had been worrying a lot about evaluation in my actual work, and since this course was released at the perfect time, I am planning to learn and apply it quickly. Thank you for always providing high-quality lectures. Additionally, this is a separate question, but I just found out that you recently published a book. I haven't purchased it yet, but I'd like to ask if it's worth studying with the book even though I've already taken all the courses. Your lectures feel like having a great mentor because you always explain and share things from the student's perspective. Once again, thank you for the great lectures as always. :)







![[Practical AIoT] Perfect Preparation for Smart Mirror Makerthon: LLM, CV, and Hardware DesignCourse Thumbnail](https://cdn.inflearn.com/public/files/courses/340196/cover/01kexgfr26whtfsmsqd2dj1x7x?w=420)

















![Just 1 hour! Creating 'My Own AI Senior Developer' to install on my computer (Antigravity Vibe Coding) [Source code provided]Course Thumbnail](https://cdn.inflearn.com/public/files/courses/340332/cover/ai/3/e87ee52b-1099-42db-a384-64ab8c725470.png?w=420)