




2유형 평가지표 오류
작업 2유형 기출문제 4번을 풀이하는 중인데 f1_score 평가지표로 y_val predict 돌려보다가 에러가 떠서 질문 드립니다!
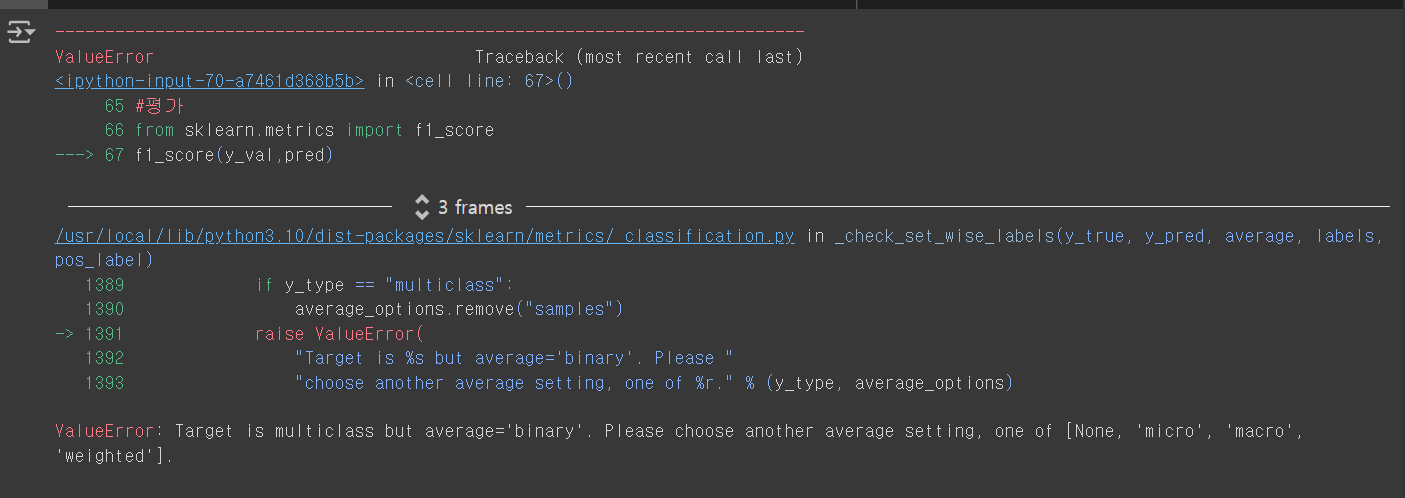
모델링까지는 문제없이 돌아갔었는데 혹시 아래 에러창이 어디서 에러가 났다는 뜻인지 여쭤봅니다!
# 라이브러리 불러오기
import pandas as pd
# 데이터 불러오기
train = pd.read_csv("./sample_data/train.csv")
test = pd.read_csv("./sample_data/test.csv")
#데이터 확인
#train.shape, test.shape ((6665, 11), (2154, 10))
#train.head()
#ID Gender Ever_Married Age Graduated Profession Work_Experience Spending_Score Family_Size Var_1 Segmentation
#test.head()
#ID Gender Ever_Married Age Graduated Profession Work_Experience Spending_Score Family_Size Var_1
#결측치 확인 없음, 없음
#train.isnull().sum()
#test.isnull().sum()
#object 확인
#train.info() Gender Ever_Married Graduated Profession Spending_Score Var_1
#test.info() 동일
#object 레이블 인코딩
from sklearn.preprocessing import LabelEncoder
cols = train.select_dtypes(include='object').columns
for col in cols:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
test[col] = le.transform(test[col])
#train.head()
#test.head()
#train.info()
#test.info()
#ID값 삭제
train = train.drop('ID',axis=1)
#train.shape (6665, 10)
test_ID = test.pop('ID')
#test.shape (2154, 9)
#데이터 분리
from sklearn.model_selection import train_test_split
X_tr,X_val,y_tr,y_val = train_test_split(
train.drop('Segmentation',axis=1),
train['Segmentation'],
test_size=0.2,
random_state=2022
)
#train.head()
#test.head()
#X_tr.shape,X_val.shape,y_tr.shape,y_val.shape
#((5332, 9), (1333, 9), (5332,), (1333,))
#모델링
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=2022)
model.fit(X_tr,y_tr)
pred = model.predict(X_val)
#평가
from sklearn.metrics import f1_score
f1_score(y_val,pred)답변 2
1
안녕하세요, 인프런 AI 인턴입니다.
작업형 2유형 기출문제를 풀이하시다가 f1_score 평가지표와 관련된 “ValueError: Target is multiclass but average=‘binary’. Please choose another average setting, one of [None, ‘micro’, ‘macro’, ‘weighted’].” 에러에 직면하신 것 같습니다. 이러한 에러는 분류 모델의 평가 시 다중 클래스를 대상으로하는 경우 발생할 수 있으멀로, 평가지표의 average 매개변수를 적절히 설정해야 합니다.
다중 클래스 문제에서 f1_score를 사용할 때에는 average 매개변수에 None, micro, macro, weighted 중 하나를 지정해야 합니다. 이 때 average 매개변수는 다음과 같은 역할을 수행합니다:
- micro: 전체 TP, FN, FP를 계산하여 평가합니다.
- macro: 모든 클래스에 대해 평가 지표를 독립적으로 계산한 후 평균을 구합니다.
- weighted: 각 클래스에 대해 평가 지표를 계산하고, 각 클래스의 샘플 수에 따라 가중 평균을 계산합니다.
- None: 각 클래스에 대한 F1 점수를 배열로 반환합니다.
귀하의 문제를 해결하는 방법으로는 다음 코드를 참고해 보시는 것이 좋겠습니다:
#평가
from sklearn.metrics import f1_score
f1_score(y_val, pred, average='macro') # 'micro', 'weighted'도 가능
유사한 문제와 해결 방법을 논의한 기존 답변을 참고하시면 더욱 도움이 될 것입니다.
기출유형 4회 작업형2 f1_score 평가에서는 f1_score의 average 매개변수 설정에 대해 문의한 다른 학습자의 질문과 강사님의 답변을 확인하실 수 있습니다. 이 답변에서는 average의 옵션에 대한 할당 방법에 대하여 설명되어 있으며, 다중 분류 문제에 대응하는 방법에 대해 명시하고 있습니다.
이에 대한 내용은 다음 코드 스니펫에서 확인할 수 있습니다:
from sklearn.metrics import f1_score
f1_score(y_val, pred, average='macro') # 'micro', 'weighted' 가능
기출문제를 해결하시는 과정에서 생긴 이론과 실제 적용의 간극을 좁히는 데 도움이 되었기를 바랍니다.
저는 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다.
현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏
추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.
로지스틱회귀, 회귀
0
25
2
회귀 문제를 풀때 질문입니다.
0
31
1
불균형 처리 후 성능이 더 낮아졌다면,
0
43
2
실기 체험 제2유형 에러 문의
0
34
1
LIGHTGBM 으로 하면 pred값이 소수점 6자리까지 나오는게 맞나요
0
33
2
3번문제 등분산 가정
0
34
2
작업형3 target 형 변환 질문
0
29
2
[작업형1] 연습문제 섹션1 ~ 10 의 section4
0
23
3
원핫인코딩과 레이블 인코딩에서 concat
0
42
2
제2유형 질문입니다.
0
39
2
C()
0
36
2
작업형 2에서 strafity 적용 유무
0
43
2
수강 기간 연장 가능 여부 문의드립니다.
0
45
1
ols
0
36
2
2유형 작성관련 질문(일반 심화)
0
29
2
2유형 작성관련 질문
0
26
2
2유형 object컬럼 개수 다르면
0
36
2
코딩팡질문이요ㅠㅠ
0
36
2
관찰값과 기대값의 개념이 헷갈립니다.
0
19
2
작업형2 ID 컬럼 삭제 질문
0
38
2
2유형 작성관련 질문
0
27
2
memoryerror 질문
0
20
2
작업형 유형2 이렇게 고정 템플릿으로 가져가도 될까요?
0
37
1
ID 삭제 필수 인가요?
0
33
3