




![[PyTorch] Học sâu một cách dễ dàng và nhanh chóngHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/324742/course_cover/96781b94-7bae-47f8-ab6f-42821f26f042/coco-pytorch.png?w=420)
[PyTorch] Học sâu một cách dễ dàng và nhanh chóng
coco
Hãy cùng học cách sử dụng MLP, CNN và RNN, những thành phần cơ bản của Deep Learning một cách dễ dàng và nhanh chóng.
Trung cấp trở lên
Deep Learning(DL), Artificial Neural Network, PyTorch
Lý thuyết và thực tế rất khác nhau. Chúng tôi sẽ giúp bạn nắm vững các khái niệm cơ bản về Machine Learning, đồng thời giới thiệu các lý thuyết và khái niệm cốt lõi của những mô hình quan trọng nhất. Bên cạnh đó, thông qua việc xử lý các loại dữ liệu đa dạng, chúng tôi sẽ chia sẻ những kỹ thuật và bí quyết hữu ích trong thực tiễn.
237 học viên
Độ khó Cơ bản
Thời gian Không giới hạn

Đánh giá từ những học viên đầu tiên
5.0
eastone0508
Buổi học rất thú vị.
5.0
김동현
Tôi nghĩ nó sẽ giúp ích rất nhiều cho công việc hiện tại của tôi.
5.0
blueday
Cảm ơn bạn vì bài giảng.
Các khái niệm cơ bản về học máy và trí tuệ nhân tạo
Phân tích hồi quy tuyến tính
Các khái niệm cốt lõi của các mô hình học máy cần biết
Các kỹ thuật giải quyết vấn đề mất cân bằng lớp
Khái niệm và lý thuyết về phân tích cụm
Cách phân tích dữ liệu đúng cách
Bước đi đầu tiên dành cho nhà khoa học dữ liệu mới bắt đầu!
Bạn muốn học các khái niệm cốt lõi cơ bản về học máy và trí tuệ nhân tạo? Khóa học này giới thiệu các khái niệm và lý thuyết cốt lõi thiết yếu để trở thành một nhà khoa học dữ liệu, cũng như các kỹ thuật khác nhau cần thiết trong thực tế.


Vì vậy, trong bài giảng này, thay vì giải thích bằng toán học, tôi tập trung giải thích các khái niệm cốt lõi để ngay cả những người mới bắt đầu cũng có thể dễ dàng thấu hiểu. Ngoài ra, tôi cũng chia sẻ những vấn đề thường gặp khi xử lý dữ liệu trong thực tế, cùng với nhiều phương pháp và bí quyết khác nhau để giải quyết những vấn đề đó.

Những ai muốn biết
khái niệm cốt lõi và lý thuyết
của các mô hình học máy

Những người muốn
phát triển nhanh chóng
với tư cách là một nhà khoa học dữ liệu

Những ai muốn học hỏi các
kỹ thuật và bí quyết học máy
cần thiết trong thực tế
Sau khi học xong tất cả nội dung, bài giảng được thiết kế để ít nhất bạn có thể phân tích dữ liệu một cách đúng đắn với tư cách là một nhà khoa học dữ liệu. Không chỉ vậy, bạn còn có thể thiết kế các thử nghiệm phù hợp với lĩnh vực dữ liệu, cũng như thực hiện lựa chọn biến và lập mô hình để nâng cao hiệu suất của mô hình.
Q. Để nghe bài giảng này có cần nhiều kiến thức toán học không?
Yêu cầu kiến thức thống kê ở cấp độ đại học, nhưng bạn không có kiến thức liên quan cũng không sao.
Q. Bạn có cần biết cách sử dụng R không?
Vâng, lớp học sẽ được tiến hành dựa trên giả định rằng bạn đã biết sử dụng R hoặc Python ở một mức độ nhất định. Tôi khuyên bạn nên tham gia khóa học <R프로그래밍 기초 다지기> (Củng cố kiến thức cơ bản về lập trình R) dưới đây.

Củng cố nền tảng lập trình R
Nếu bạn mới bắt đầu với phân tích dữ liệu và lập trình R? Bài giảng miễn phí

Truyền đạt
bí quyết cốt lõi
từ kinh nghiệm thực tế

Học
coding trực tiếp
một cách sinh động

Nâng cao cảm giác thực tế
với đa dạng
dữ liệu
Không chỉ dừng lại ở việc giảng dạy lý thuyết học máy đơn thuần và thực hành áp dụng vào dữ liệu. Tôi mong muốn truyền tải tối đa những bí quyết để phân tích dữ liệu hiệu quả, được đúc kết từ kinh nghiệm tham gia 7 cuộc thi dữ liệu lớn (7 lần lọt vào chung kết, 5 lần đoạt giải) và nhiều dự án đa dạng khác nhau.
Để cho các bạn thấy thực tế quá trình tôi phân tích dữ liệu, hầu hết các buổi thực hành sẽ được tiến hành dưới hình thức live coding. Tôi sẽ trình bày chi tiết từ việc khi gặp vấn đề chưa biết trong quá trình viết code thì sẽ tìm kiếm như thế nào và áp dụng ra sao, đồng thời chia sẻ cả những vấn đề phát sinh khi xử lý dữ liệu cùng các phương pháp được sử dụng để giải quyết chúng.
Chúng tôi sẽ xử lý nhiều loại dữ liệu khác nhau. Để rèn luyện kỹ năng thực tế, khóa học bao gồm các dữ liệu phổ biến như dự đoán giá nhà Boston House, dữ liệu mô phỏng có tính đa cộng tuyến mạnh, dữ liệu dự đoán cảm xúc tích cực/tiêu cực của đánh giá phim (tiếng Hàn), dữ liệu dự đoán giá thuê nhà Villa ở Seoul, và dữ liệu Otto từ Kaggle.
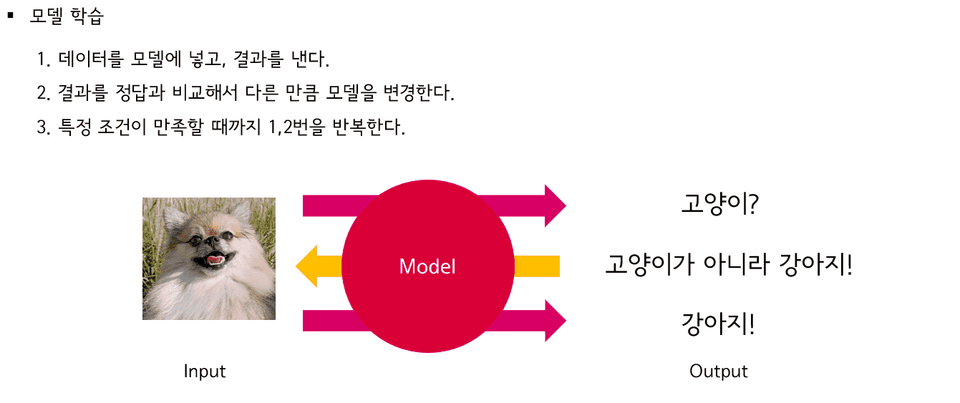
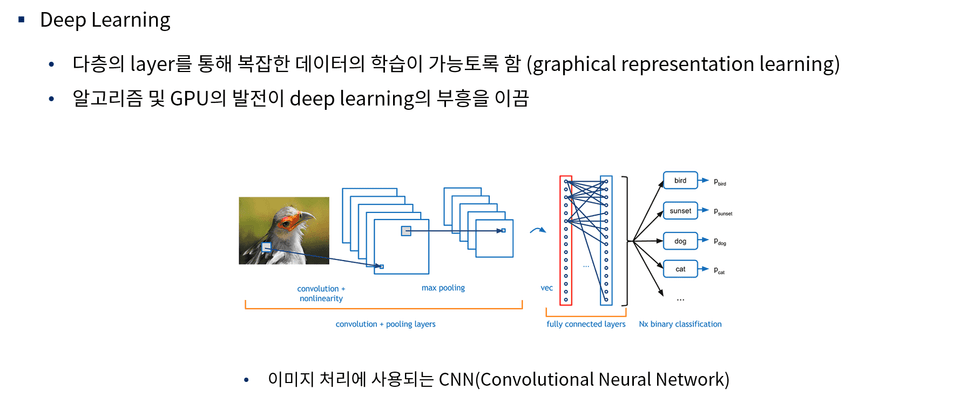
Chúng ta sẽ tìm hiểu về khái niệm học máy (machine learning) là gì và có thể làm được những gì với học máy. Ngoài ra, nội dung cũng sẽ giới thiệu ngắn gọn về sự khác biệt giữa học máy và học sâu (deep learning), cũng như các mô hình học máy và học sâu đa dạng khác nhau. Đồng thời, chúng ta cũng sẽ tìm hiểu về hiện tượng quá khớp (overfitting) thường xảy ra phổ biến trong cả lĩnh vực học máy và học sâu.

Mô hình hồi quy tuyến tính luôn là mô hình đầu tiên chúng ta được học khi bắt đầu tìm hiểu về Machine Learning. Tuy là một mô hình đơn giản và dễ hiểu, nhưng nó thường bị coi nhẹ vì cho rằng hiệu suất không cao. Tuy nhiên, mô hình hồi quy tuyến tính thực tế lại được sử dụng rất nhiều trong công việc thực tiễn và là một công cụ mạnh mẽ cho các bài toán hồi quy. Chúng ta sẽ tập trung tìm hiểu sâu vào những lý thuyết và khái niệm cơ bản nhất của mô hình này.

Chúng tôi sẽ đề cập đến các mô hình học máy thiết yếu mà bạn cần phải biết. Thay vì đi sâu vào nội dung toán học, bài giảng sẽ tập trung vào các khái niệm để giúp bạn dễ hiểu hơn. Các mô hình như Decision Tree, kNN tuy ít khi được sử dụng như một mô hình đơn lẻ, nhưng chúng lại được ứng dụng đa dạng trong các lĩnh vực hoặc mô hình khác. Vì vậy, tuyệt đối không nên xem nhẹ chúng. Bạn sẽ được học về khái niệm và cách sử dụng của nhiều mô hình khác nhau, đồng thời tôi cũng sẽ giới thiệu về ShapValue - một khái niệm đang được chú ý trong lĩnh vực AI có thể giải thích được (eXplainable AI).


Vấn đề mất cân bằng lớp xảy ra thường xuyên trong nhiều lĩnh vực hơn bạn nghĩ và gây ra nhiều vấn đề khác nhau. Điển hình là việc mô hình học tập thiên lệch về phía lớp đa số, dẫn đến hiệu suất dự đoán bị giảm sút. Chúng tôi xin giới thiệu các kỹ thuật khác nhau (phương pháp Resampling) để giải quyết những vấn đề này.

Việc phân tích dữ liệu không chỉ đơn thuần dừng lại ở quá trình đọc dữ liệu và khớp mô hình. Bạn cần phải trải qua các bước tiền xử lý dữ liệu cơ bản, tạo ra các biến phái sinh quan trọng để dự báo giá trị Y, và nhất thiết phải tiến hành thiết kế thử nghiệm phù hợp. Chúng tôi sẽ truyền tải những kiến thức thiết yếu mà một nhà khoa học dữ liệu cần biết cùng với các phương pháp thiết kế thử nghiệm phù hợp cho nhiều tình huống khác nhau.


"Có một sự khác biệt đáng kể giữa lý thuyết và thực hành trong học máy. Thế giới có vô vàn lĩnh vực và dữ liệu khác nhau, và để phân tích dữ liệu, chúng ta không thể chỉ dừng lại ở việc huấn luyện mô hình. Việc thiết kế thử nghiệm phù hợp với lĩnh vực, tạo các biến phái sinh để nâng cao hiệu suất mô hình và lựa chọn mô hình theo mục đích phân tích là những yếu tố hỗ trợ thiết yếu phải được thực hiện.
Trong khóa học này, chúng tôi sẽ giải thích các khái niệm và cốt lõi của khoa học dữ liệu và trí tuệ nhân tạo một cách dễ hiểu nhất có thể, đồng thời cung cấp nhiều mẹo và bí quyết khác nhau có thể áp dụng trong thực tế. Hy vọng rằng thông qua khóa học này, bạn có thể nâng cao kỹ năng của mình để cải thiện cảm quan thực tế trong phân tích dữ liệu."
Khóa học này dành cho ai?
Những người muốn tìm hiểu về các khái niệm cốt lõi và lý thuyết của các mô hình học máy
Những người muốn phát triển nhanh chóng với tư cách là một nhà khoa học dữ liệu (Data Scientist)
Cần biết trước khi bắt đầu?
Thống kê học cấp độ đại học
Cơ bản về lập trình R
8,491
Học viên
524
Đánh giá
136
Trả lời
4.4
Xếp hạng
20
Các khóa học
Tôi là một người thất nghiệp vẫn đang tiếp tục học tập, sau khi tốt nghiệp cử nhân chuyên ngành Thống kê và nhận bằng Tiến sĩ Kỹ thuật Công nghiệp (Trí tuệ nhân tạo).
Giải thưởng
ㆍ Cuộc thi Big Contest lần thứ 6: Phát triển thuật toán dự đoán người dùng rời bỏ trò chơi / Giải thưởng NCSOFT (2018)
ㆍ Cuộc thi Big Contest lần thứ 5 - Phát triển thuật toán dự đoán người nợ quá hạn khoản vay / Giải thưởng của Chủ tịch Hiệp hội Xúc tiến Công nghệ Thông tin và Truyền thông Hàn Quốc (2017)
ㆍ Cuộc thi Big Data Thời tiết 2016 / Giải thưởng của Viện trưởng Viện Thúc đẩy Công nghiệp Khí tượng (2016)
ㆍ Phát triển thuật toán dự đoán gian lận bảo hiểm tại Big Contest lần thứ 4 / Lọt vào vòng chung kết (2016)
ㆍ Cuộc thi Big Contest lần thứ 3: Phát triển thuật toán dự đoán trận đấu bóng chày / Giải thưởng của Bộ trưởng Bộ Khoa học, Công nghệ thông tin và Hoạch định tương lai (2015)
* blog : https://bluediary8.tistory.com
Lĩnh vực nghiên cứu chính của tôi là khoa học dữ liệu, học tăng cường và học sâu.
Hiện tại tôi đang thực hiện việc thu thập dữ liệu (crawling) và khai phá văn bản (text mining) như một sở thích :)
Tôi đã phát triển một ứng dụng có tên là Marong, sử dụng kỹ thuật crawling để thu thập và hiển thị những bài viết phổ biến từ các cộng đồng trực tuyến, và
Tôi cũng từng thu thập danh sách các quán ăn ngon và blog trên toàn quốc để tạo ra một ứng dụng gợi ý quán ăn :) (nhưng rồi cũng thất bại thảm hại..)
Hiện tại, tôi đang là nghiên cứu sinh tiến sĩ chuyên nghiên cứu về trí tuệ nhân tạo.
Tôi đã từng phát triển và tạo ra một ứng dụng gợi ý quán ăn ngon bằng cách thu thập danh sách các nhà hàng và blog ẩm thực trên toàn quốc :) (nhưng đã thất bại thảm hại..). Hiện tại, tôi đang là nghiên cứu sinh tiến sĩ chuyên ngành trí tuệ nhân tạo.
Tôi đã từng phát triển và tạo ra một ứng dụng gợi ý quán ăn ngon bằng cách thu thập danh sách các quán ăn và blog trên toàn quốc :) (nhưng đã thất bại thảm hại..). Hiện tại, tôi đang là nghiên cứu sinh tiến sĩ chuyên ngành trí tuệ nhân tạo.
Tôi đã từng phát triển và tạo ra một ứng dụng gợi ý quán ăn ngon bằng cách thu thập danh sách các quán ăn cũng như các bài blog trên toàn quốc :) (nhưng đã thất bại thảm hại..). Hiện tại, tôi đang là nghiên cứu sinh tiến sĩ chuyên ngành trí tuệ nhân tạo.
Tôi đã từng phát triển và tạo ra một ứng dụng gợi ý quán ăn ngon bằng cách thu thập danh sách các quán ăn và blog trên toàn quốc :) (nhưng đã thất bại thảm hại..). Hiện tại, tôi đang là nghiên cứu sinh tiến sĩ chuyên ngành trí tuệ nhân tạo.
Tất cả
71 bài giảng ∙ (14giờ 31phút)
Tài liệu khóa học:
Tất cả
30 đánh giá
4.8
30 đánh giá
Đánh giá 5
∙
Đánh giá trung bình 5.0
Đánh giá 1
∙
Đánh giá trung bình 5.0
Đánh giá 1
∙
Đánh giá trung bình 5.0
Đánh giá 1
∙
Đánh giá trung bình 5.0
Đánh giá 10
∙
Đánh giá trung bình 4.9
Hãy khám phá các khóa học khác của giảng viên!
Khám phá các khóa học khác trong cùng lĩnh vực!
Ưu đãi có thời hạn, kết thúc sau 3 ngày ngày
1.254.248 ₫
30%
1.791.783 ₫




![[Với R] Thống kê cơ bản cho học máyHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/325155/course_cover/d8120723-26f7-4fcc-a25c-a99eef4ea0f6/machine-learning-statistics-r-eng.png?w=420)
![[PyTorch] Học NLP dễ dàng và nhanh chóngHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)
![[R] Thu thập và quản lý dữ liệu tất cả các mã cổ phiếu KOSPI/KOSDAQHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/324972/course_cover/36468a43-de3b-461b-af55-f3c7b0e51637/kospi-kosdaq-data-eng-1.png?w=420)
![[PyTorch] Học GAN dễ dàng và nhanh chóngHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/324945/course_cover/9794a376-0e54-4745-8a1d-3c6fe72b8fe6/pytorch-gan-eng.png?w=420)














![[Hoàn thành trong 7 ngày] Chứng chỉ MS AI-900 đậu ngay lần đầuHình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/338854/cover/01k4caartf5v7x2e574pq0wnp8?w=420)

![[TensorFlow 2] Hoàn thành cuộc chinh phục Python machine learning - Dự án dự đoán kỷ lục MarathonHình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/324207/course_cover/1a79c7dc-1624-4d3a-95ff-79ba1e9c4025/python_machine_learning.png?w=420)


![[Đỉnh cao DX sản xuất] Master Class chiến lược ứng dụng AI thực tiễn cho 7 ngành công nghiệp trọng điểmHình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/342169/cover/ai/2/e0850074-3049-4f98-b6db-611d07ea5083.png?w=420)
![[ICT Archive] Cốt lõi Big Data và Mô hình Kinh doanhHình thu nhỏ khóa học](https://cdn.inflearn.com/public/files/courses/338811/cover/01k44rs7zkwq0ehc8vqsy2mdtb?w=420)




