




5.9 bike sharing demand에서 standardScaler
403
작성한 질문수 2
bike sharing demand예제에서 LinearRegression모델이 다른 모델에 비해 RMSLE가 큰 것이 Scaler문제는 아닌가 해서 StandardScaler를 다음과 같이 적용시켜 봤습니다만, 성능이 좋아지질 않는 것 같습니다.
X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log, test_size = 0.3, random_state = 0)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1 = False, sts = False):
if sts:
ct = ColumnTransformer([
('standard', StandardScaler(), ['temp', 'atemp', 'humidity', 'windspeed'])
], remainder = 'passthrough')
model = Pipeline([
('ct', ct),
('model', model)
])
model.fit(X_train, y_train)
pred = model.predict(X_test)
if is_expm1:
y_test = np.expm1(y_test)
pred = np.expm1(pred)
print(model.__class__.__name__)
evaluate_regr(y_test, pred)선형 모델임에도 불구하고 이게 통하지 않는것이 좀 의문입니다. 게다가 다른 모델에서는 성능이 나빠지기도 합니다.
그리고 StandardScaler를 적용하기 전과 후의 coef_가 많이 다릅니다. 다음 그래프는 StandardScaler를 적용했을 때 LinearRegression의 coef_입니다.
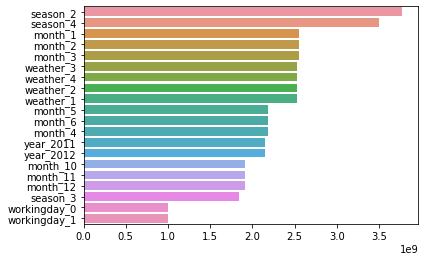
feature중요도 측면에서, StandardScaler를 적용한 후의 coef_가 더 믿을만 한지, 아니면 적용하지 않은게 더 믿을만 하다고 봐야하는지 궁금합니다.
그래프 출력하는 코드는 다음과 같습니다.
# X_features_ohe_sts
ct = ColumnTransformer([
('standard', StandardScaler(), ['temp', 'atemp', 'humidity', 'windspeed'])
], remainder = 'passthrough')
model = Pipeline([
('ct', ct),
('model', LinearRegression())
])
# model = LinearRegression()
model.fit(X_train, y_train)
series = pd.Series(np.abs(model[-1].coef_), index = X_features_ohe.columns)
series = series.sort_values(ascending = False)[:20]
sns.barplot(series.values, series.index)답변 1
0
안녕하십니까,
강의에서도 얼핏 말씀드리지만, 선형 모델에서 StandardScaler를 적용한다고, 무조건 성능이 좋아지지는 않습니다.
경험적으로 말씀하신대로 성능이 약간 떨어지는 경우도 있습니다. 충분한 학습 데이터와 테스트 데이터를 적용해 보면 성능이 약간 떨어지는 경우는 없을 것 같습니다만 정확한 원인은 저도 잘 모르겠습니다.
원칙적으로는 선형 모델에 StandardScaler이든 MinMaxScaler이든 데이터에 적용을 하는 것이 좋습니다. 하지만 적용하지 않고 모델 성능을 한번 판정해 보는 것도 방법입니다.
선형 모델의 경우 StandardScaler, MinMaxScaler, Scaler 미 적용등의 경우를 각각 적용해서 최적 모델을 판단하는 것도 방법입니다.
감사합니다.
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
55
2
안녕하세요 열심히 수강중인 학생입니다
0
91
2
정수 인덱싱
0
86
2
넘파이 오류
0
112
2
11강 numpy의 axis 축 질문 드립니다.
0
107
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
96
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
79
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
83
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
74
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
81
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
78
3
파이썬 다운그레이 후 사이킷런 재설치
0
131
2
좋은 강의 감사합니다.
0
80
2
scoring 함수 음수값
0
72
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
108
2
분류 평가 정확도 예측
0
89
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
114
1
카카오톡 채널 있나요
0
119
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
193
2
pca 스케일링 관련하여 질문드립니다.
0
109
2
주피터 대신 구글 코랩
0
184
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
156
2
실루엣 스코어..
0
93
2