인프런 커뮤니티 질문&답변
작성한 질문수

모델 평가 후 result 데이터 생성 시 오류
해결된 질문
24.06.13 22:36 작성
·
107
0
작업형 2 모음집 하는 도중 마지막 데이터 제출 데이터 파일 생성시 다음과 같은 오류가 나는데 왜 그럴까용..?
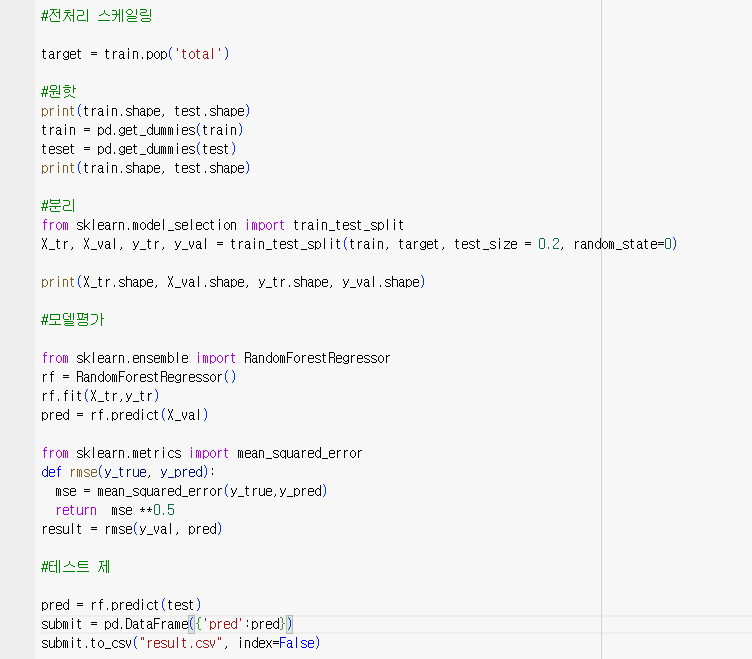 [코드]
[코드]
#전처리 스케일링
target = train.pop('total')
#원핫
print(train.shape, test.shape)
train = pd.get_dummies(train)
teset = pd.get_dummies(test)
print(train.shape, test.shape)
#분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train, target, test_size = 0.2, random_state=0)
print(X_tr.shape, X_val.shape, y_tr.shape, y_val.shape)
#모델평가
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_tr,y_tr)
pred = rf.predict(X_val)
from sklearn.metrics import mean_squared_error
def rmse(y_true, y_pred):
mse = mean_squared_error(y_true,y_pred)
return mse **0.5
result = rmse(y_val, pred)
#테스트 제
pred = rf.predict(test)
submit = pd.DataFrame({'pred':pred})
submit.to_csv("result.csv", index=False)
[오류내역]
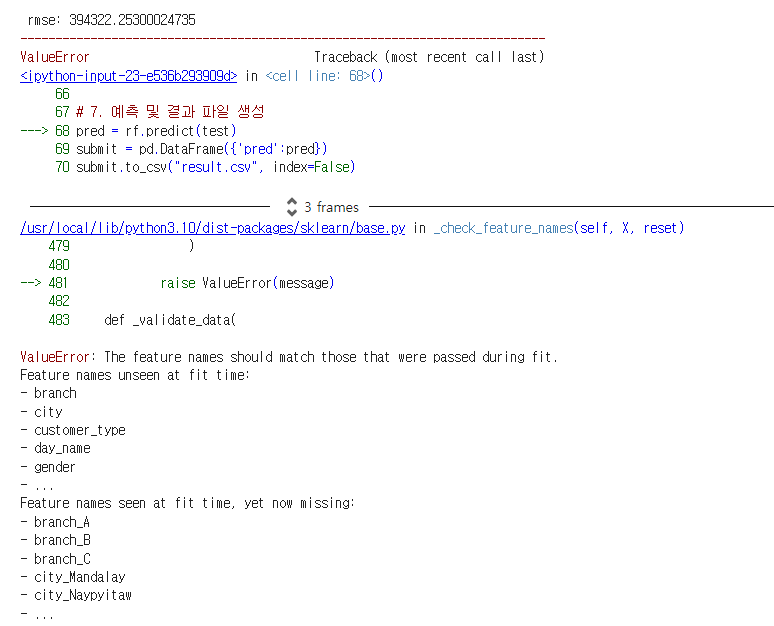 ---------------------------------------------------------------------------
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-23-e536b293909d> in <cell line: 68>()
66
67 # 7. 예측 및 결과 파일 생성
---> 68 pred = rf.predict(test)
69 submit = pd.DataFrame({'pred':pred})
70 submit.to_csv("result.csv", index=False)
3 frames
/usr/local/lib/python3.10/dist-packages/sklearn/base.py in _check_feature_names(self, X, reset)
479 )
480
--> 481 raise ValueError(message)
482
483 def _validate_data(
ValueError: The feature names should match those that were passed during fit.
Feature names unseen at fit time:
- branch
- city
- customer_type
- day_name
- gender
- ...
Feature names seen at fit time, yet now missing:
- branch_A
- branch_B
- branch_C
- city_Mandalay
- city_Naypyitaw
- ...
답변 2
0
2024. 06. 14. 09:30
테스트 데이터와 학습 데이터의 피처 이름이 일치하지 않아서 발생한 것입니다.
위에 코드를 잘 살펴보면 데이터를 test가 아닌 teset로 적었네요
대부분의 오류는 오타가 많아요!!
0
2024. 06. 13. 22:42
안녕하세요, 인프런 AI 인턴입니다.
jsr님의 질문에 대한 답변은 귀하가 직면한 상황과 매우 유사한 참고 자료를 찾았습니다. 이는 훈련 데이터셋과 테스트 데이터셋 간의 특성(컬럼) 이름 불일치로 인한 문제로 보입니다. 모델을 학습할 때 사용한 데이터와 예측할 때 사용한 데이터에서 특성 이름이 일치해야 합니다.
질문자가 겪고 있는 오류는 특성 이름이 학습 데이터셋에서 사용되었는지 여부와 관련이 있습니다. 예측 과정에서 모델은 예측을 수행하기 위해 학습 단계에서 본 것과 동일한 특성 이름을 기대합니다. 여기에 몇 가지 문제가 있을 수 있습니다:
- 원-핫 인코딩 시 pd.get_dummies()를 사용하여 훈련 데이터와 테스트 데이터를 변환할 때, 양쪽 데이터셋에 동일한 카테고리 값이 없으면 서로 다른 특성 집합이 생성될 수 있습니다. 이로 인해 훈련 데이터에는 있지만 테스트 데이터에는 없는 칼럼이 있거나 그 반대의 상황이 발생할 수 있습니다.
이 문제를 해결하기 위한 한 가지 방법은 원-핫 인코딩을 적용하기 전에 훈련 데이터와 테스트 데이터를 결합하여 모든 가능한 카테고리 값에 대해 동일한 특성 집합이 생성되도록 하는 것입니다. 그 후, 훈련과 테스트 데이터를 다시 분할합니다.
참고로 다음의 질문에서 비슷한 문제가 발생하였고, 이에 대한 답변이 제공되었습니다:
- 작업형2 빅데이터 분석기사 2회 실기 질문
- 이 상황에서는 특성 이름의 불일치로 인한 에러가 발생하였고, 코멘트에서 설명하는 해결책은 인코딩 절차의 확인과, 테스트 데이터 셋의 컬럼 이름을 정확히 조정하는 것입니다.
제공된 링크와 비교하여 직면한 상황을 검토하고 문제를 해결해 보시길 바랍니다.
저는 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다.
현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏
추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.