
“저 사람과 같은 클로드 코드인데, 왜 나는 몇 번씩 계속 고쳐야만 할까..?"
- #하네스엔지니어링
- #HarnessEngineering
- #ClaudeCode
- #AI코딩
- #2026
클로드 코드를 쓴다면?
하네스 엔지니어링을 꼭 알아야 하는 이유!
AI 코딩을 일상적으로 쓰는 분이 한 단계 위로 올라가기 위한 멘탈 모델을 정리했습니다.
· 2026-05 기준 · 읽는 데 약 10분
안녕하세요, 인프런입니다.
최근 테크 컨퍼런스나, SNS에서 회자되는 주제가 바뀌었어요. 예전엔 “어떤 AI 툴을 써야 해요?”였다면, 요즘은 이렇게 묻습니다.
“대체 하네스 엔지니어링이 뭔데요?"
하네스 엔지니어링(Harness Engineering). Martin Fowler, Addy Osmani 같은 거물급 사람들이 2026년 들어 같은 시기에 글을 내며 새로운 분야로 자리잡는 중입니다. 모델을 쓰는 사람이 모델 주변에 무엇을 둘 것인가, 그 설계가 곧 성능을 가른다는 이야기예요.
이 글은 Claude Code, Codex CLI, Cursor를 매일 쓰지만 한 단계 위로 올라가고 싶은 중급 실무자를 위한 글입니다. 개념부터 풀고, 마지막에 “그래서 지금 시점에 어떤 도구가 가장 적합한가”까지 솔직하게 짚을게요.
① 같은 모델, 다른 결과 : 무엇이 격차를 만드는가
최근 공개된 Terminal Bench 2.0(터미널 환경에서 코딩 에이전트의 능력을 평가하는 벤치마크) 결과를 보면 흥미로운 지점이 있어요. 모델은 그대로인데, 그 모델을 감싸는 “기본 하네스”와 “커스텀 하네스”의 점수 차이가 무시할 수 없을 정도로 큽니다. 똑같은 두뇌인데 손발이 다르니 결과가 다른 거죠.
이 사실이 시사하는 바는 단순합니다. 우리가 흔히 “AI가 똑똑해졌다”라고 말할 때, 실제로 우리 손에 닿는 결과의 절반 이상은 모델이 아니라 모델 주변에서 만들어지고 있어요. 그리고 그 주변은, 지금 시점에서 사용자가 직접 설계할 수 있는 영역입니다.
지난 2년간 AI 코딩 활용법은 단계적으로 진화해왔습니다.
- 2024/프롬프트 엔지니어링: 어떻게 말해야 잘 알아듣지?
- 2025/컨텍스트 엔지니어링: 무엇을, 언제 컨텍스트 윈도우에 넣어야 하지?
- 2026/하네스 엔지니어링: 그 모든 걸 조립하는 시스템 자체를 어떻게 설계하지?
이번 글은 2026년, AI 코딩을 하는 사람이라면 한 번쯤 들어봤을 키워드인 하네스 엔지니어링 이야기입니다.
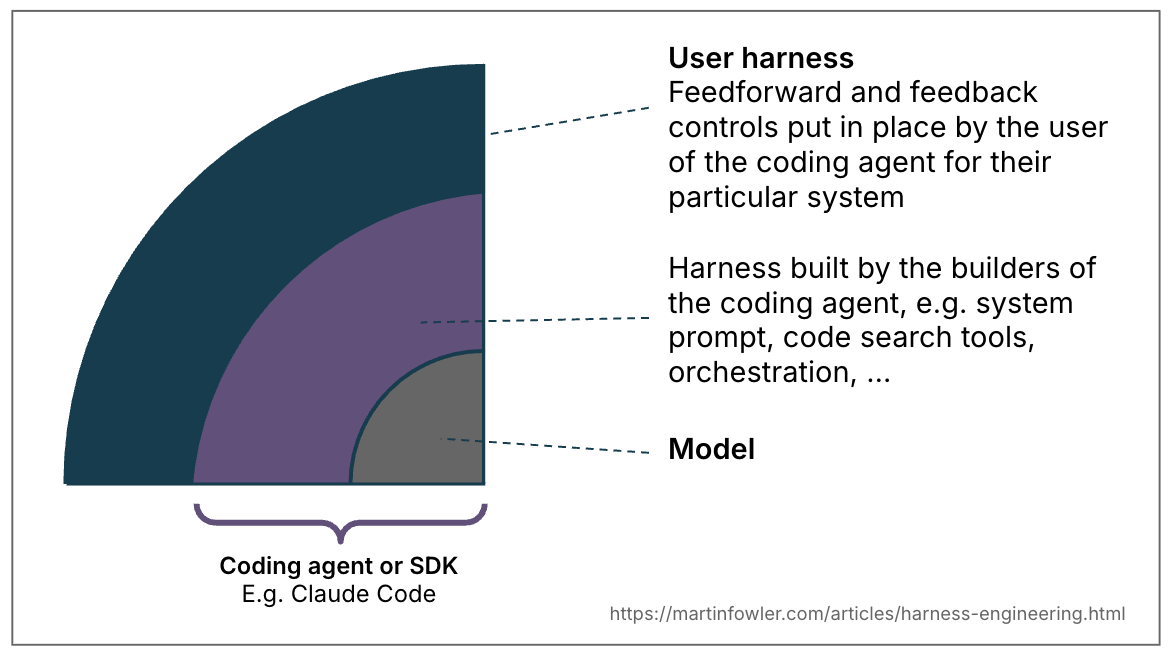
② 하네스란 무엇인가: Agent = Model + Harness
가장 깔끔한 정의는 한 줄짜리 공식입니다. AI 분야의 Viv Trivedy가 정리한 표현이에요.
Agent = Model + Harness.
모델이 아닌 것은 전부 하네스(harness)다.

여기서 하네스는 말 그대로 말이 마차를 끌게 해주는 가죽끈 세트를 떠올리시면 돼요. 모델은 그 자체로 코드를 작성하는 두뇌일 뿐이고, 그 두뇌가 실제로 파일을 읽고, 명령을 실행하고, 결과를 다음 차례 입력으로 돌려 받게 만들어주는 모든 코드와 설정이 바로 하네스입니다.
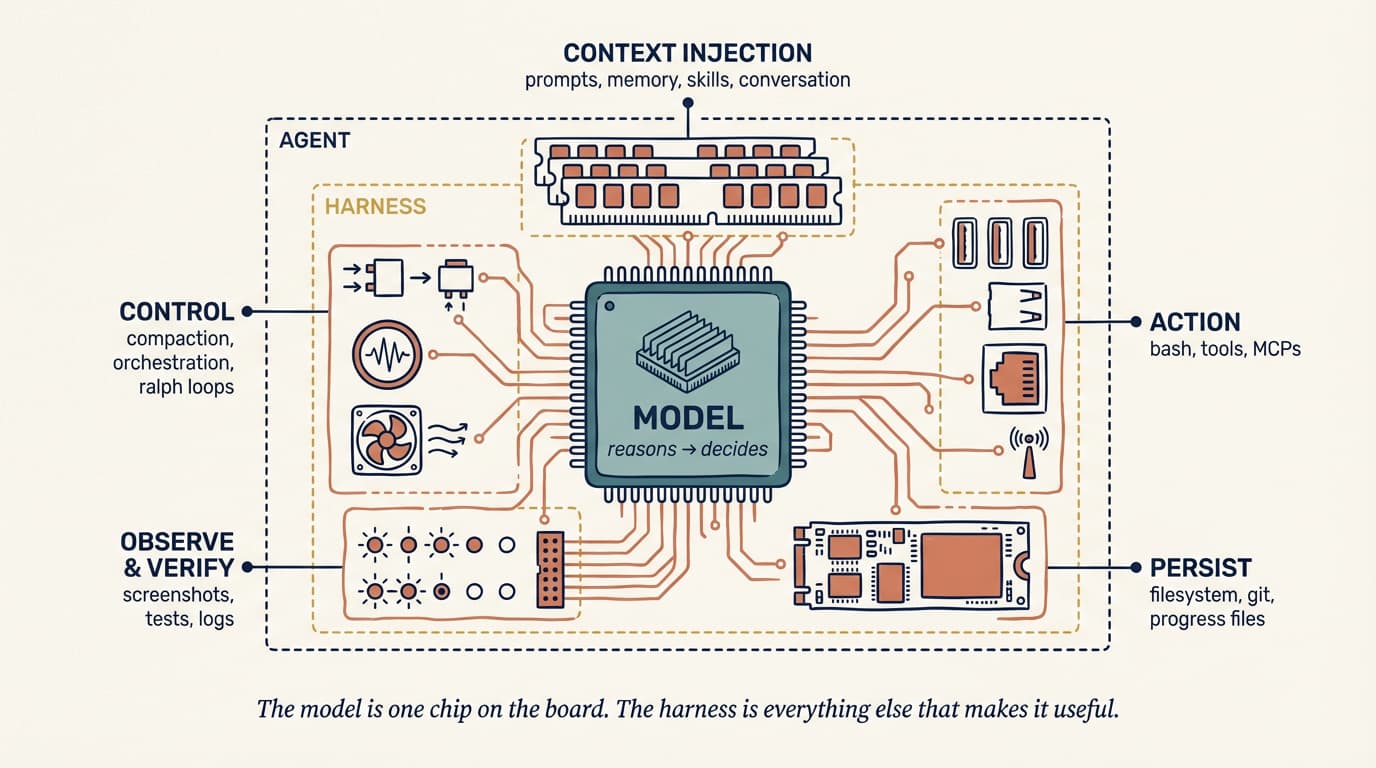
구체적으로는 이런 것들이에요.
- 시스템 프롬프트와 메모리 파일(
CLAUDE.md,AGENTS.md) - 모델이 호출할 수 있는 도구(Read, Write, Bash, Grep…)의 정의와 스키마
- 도구 실행을 감싸는 권한 모델과 샌드박스
- 각 턴마다 무엇을 컨텍스트에 넣고 무엇을 제거할지 결정하는 압축 로직
- 훅(hook), 서브에이전트(subagent), MCP 서버 같은 확장 메커니즘
- 실패한 출력에 대한 자가 수정 루프와 검증 신호
이 정의가 중요한 이유는 도구에 종속되지 않는다라는 점이에요. Claude Code, Codex, Gemini, Kimi, Qwen 등... 어떤 코딩 에이전트를 쓰든 모두 내가 미세 조정한 하네스를 사용할 수 있습니다. 그래서 하네스를 다루는 방법과 구현만 단단히 익혀두면 어떤 도구로 옮겨가도 그대로 따라갑니다.
Addy Osmani가 자신의 글에서 한 줄로 압축한 통찰이 인상적이에요.
좋은 모델 + 평범한 하네스보다, 평범한 모델 + 좋은 하네스가 낫다.
모델 업그레이드는 우리가 통제할 수 없는 영역이지만, 하네스는 지금 우리 손으로 만질 수 있는 영역이라는 뜻이기도 합니다.
③ 하네스의 해부학 : 5가지 핵심 구성 요소
오픈소스 커뮤니티의 정리(ai-boost/awesome-harness-engineering)는 하네스를 12가지 설계 원시(design primitive)로 분류해요. 처음 접하는 분께는 너무 많으니, 실무자 관점에서 5가지로 압축해 보겠습니다.
1) Agent Loop와 도구 설계 (Tool Design)
에이전트는 결국 생각 → 행동 → 관찰(Thought / Action / Observation) 루프를 돌립니다. 모델이 한 번 응답할 때 어떤 도구를 호출할 수 있는지, 그 도구가 어떤 인자를 받고 어떤 형태로 결과를 돌려주는지, 이 모든 게 도구 정의에 달려 있어요. 그래서 업계에서는 이런 표현을 씁니다.
Tool design is agent UX.
중요한 건 도구의 수가 아니라 초점이에요. 50개의 기능이 겹치는 도구보다, 10개의 잘 분리된 도구가 모델의 정확도를 훨씬 끌어올립니다.
2) 컨텍스트 전달과 압축 (Context Delivery & Compaction)
컨텍스트 윈도우는 아무리 길어져도 유한합니다. 그리고 모델은 컨텍스트가 부풀어 오를수록 집중력을 잃어요. 그래서 하네스는 끊임없이 무엇을 넣고 무엇을 뺄지를 결정합니다.
실무에서 이 영역에 해당하는 게 CLAUDE.md/AGENTS.md 같은 메모리 파일이에요. 잘 만들어진 하네스에서는 이 파일이 60줄 안쪽으로 유지됩니다. 그 안에 코딩 스타일, 금지 사항, 자주 쓰는 명령어, 중요한 사실만 압축적으로 담죠. 200줄 넘는 거대한 가이드를 만들면 그 자체가 노이즈가 됩니다.
3) 메모리와 상태 (Memory & State)
한 번의 대화를 넘어서는 정보가 필요할 때 하네스는 세 가지 계층의 메모리를 씁니다.
- In-context 메모리: 지금 대화창에 떠 있는 것
- External 메모리: 파일, DB, 벡터 스토어로 분리된 것 (Claude Code의 자동 메모리, MCP 서버 등)
- Procedural 메모리: 슬래시 명령(
/skill)이나 스킬처럼 “상황이 오면 펼쳐 보는” 절차적 지식
특히 Procedural 메모리는 최근 화두예요. Skill, Plugin 같은 메커니즘이 부상하는 이유가 여기 있습니다. 한 번에 다 펴 보여주지 않고, 필요할 때만 꺼내 쓰는 progressive disclosure(점진적 공개)가 컨텍스트 절약과 신뢰성을 동시에 잡습니다.
4) 권한과 샌드박스 (Permissions & Sandbox)
가장 간과되는 영역이지만, 실무에서 가장 사고가 잦은 영역이기도 해요. 도구를 모델에게 그냥 다 열어주면 rm -rf, 민감한 정보를 공개 푸시, 외부 API 무한 호출로 비용의 급격한 증가 같은 대형 사고가 납니다.
성숙한 하네스는 권한을 “프롬프트로 신뢰”하지 않습니다. 대신 구조화된 권한 패턴읽기/쓰기/실행을 분리하고, 위험 동작 직전에 사용자 승인을 받고, 샌드박스에서 격리해 실행을 따라요. Codex CLI는 macOS Seatbelt와 Linux Landlock으로 OS 단에서 막고, Claude Code는 매 위험 동작마다 승인 프롬프트를 띄우는 방식으로 풀고 있습니다.
5) 검증과 피드백 루프 (Verification & Feedback)
잘 만든 하네스는 에이전트가 만든 결과를 자기 자신이 다시 검증하게 만듭니다. 테스트, 린트, 타입체크, 심지어 다른 모델의 코드 리뷰까지, 이 모든 게 다음 턴의 입력으로 돌아옵니다.
④ 두 축: 피드포워드와 피드백, 그리고 래칫 패턴
이 섹션은 Martin Fowler의 “Harness engineering for coding agent users”에서 가져온 프레임이에요. 한 번 익히면 다음에 새 도구를 마주칠 때마다 같은 잣대로 분석할 수 있게 됩니다.
핵심 비유는 사이버네틱스의 거버너(governor)예요. 거버너는 두 가지로 시스템을 안정시킵니다.
- 피드포워드(Feed-forward) - Guides: 일이 일어나기 전에 방향을 정하는 신호.
CLAUDE.md, 시스템 프롬프트, 도구의 description, 잘 쓴 작업 지시문이 여기 속해요. “이 코드베이스에선 클래스 이름을 PascalCase로 써” 같은 사전 규칙. - 피드백(Feedback) - Sensors: 일이 일어난 후에 결과를 관찰하는 신호. 린트 에러, 타입체커 출력, 실패한 테스트, hook이 막아낸 동작, 심지어 다른 모델의 PR 리뷰. “방금 네가 만든 함수, 컴파일 안 돼”라고 알려주는 모든 것.
Fowler가 강조하는 핵심은 이거예요.
둘 중 하나만 있으면 충분하지 않다. 피드백만 있는 에이전트는 같은 실수를 반복하고, 피드포워드만 있는 에이전트는 자기가 규칙을 지켰는지조차 알지 못한다.
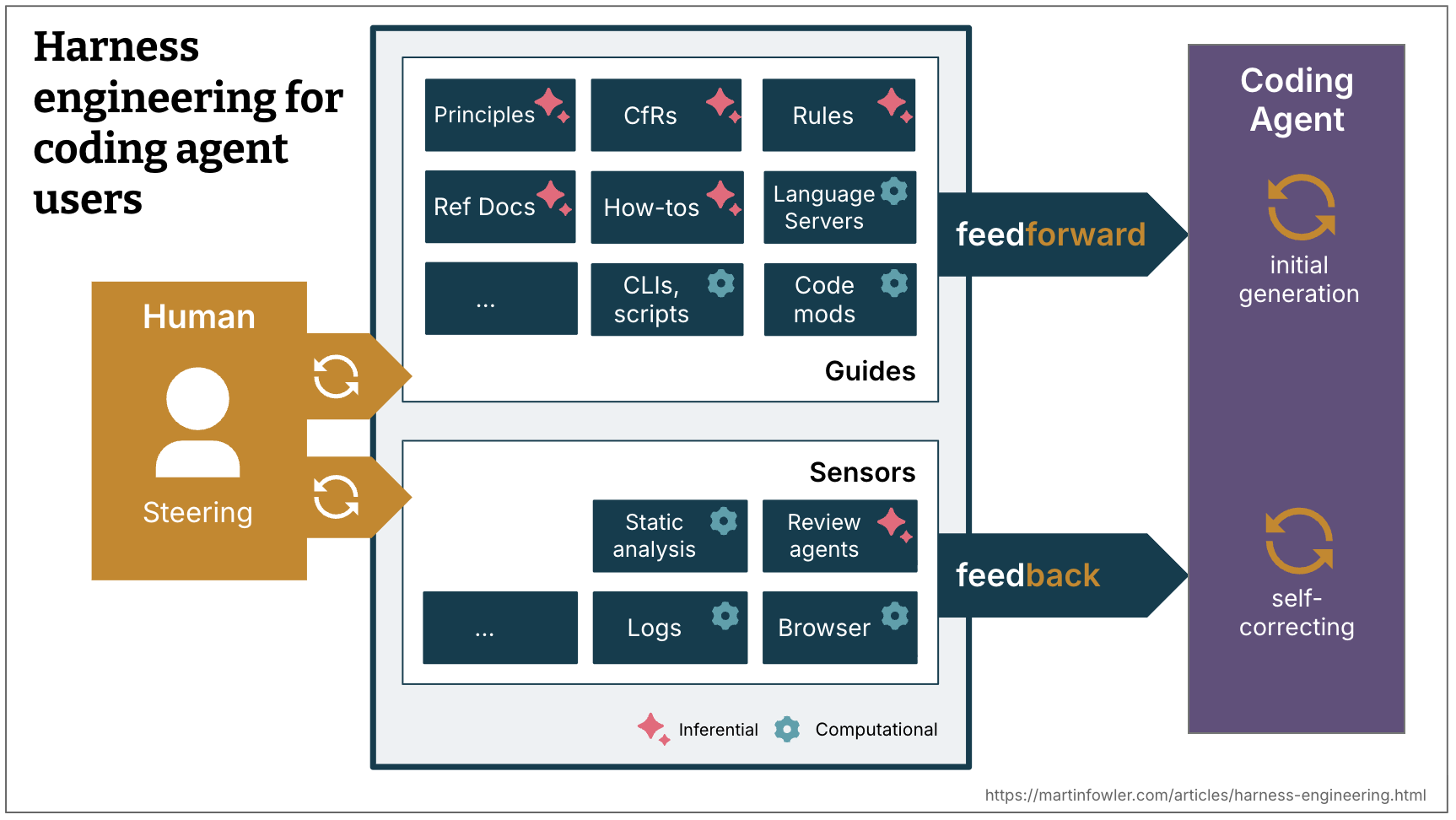
계산형(Computational) 센서 vs 추론형(Inferential) 센서
피드백 신호도 두 종류로 갈라집니다.
- 계산형 센서: 결정론적이고 빠릅니다. 밀리초~초 단위. 타입체커, 린터, 단위 테스트, 빌드 결과. 값이 같으면 항상 같은 답을 줍니다.
- 추론형 센서: AI 코드 리뷰, LLM-as-judge, 의미 기반 검증. 느리고 비결정론적이지만, 구조가 아닌 의도를 잡습니다.
실전에서는 둘을 섞어 씁니다. 빠른 신호로 거르고, 남은 모호한 영역만 비싼 추론형 센서로 마감하는 식이에요.
래칫(Ratchet) 패턴 : 하네스는 조이는 방향으로만 움직인다
Addy Osmani가 정리한 운영 원칙은 단순하지만 강력해요. 에이전트의 모든 실패를 신호로 취급하라.
- 에이전트가 같은 실수를 두 번 하면 →
CLAUDE.md에 규칙 한 줄을 추가한다. - 그래도 또 반복하면 → hook으로 자동 차단/검증을 건다.
- 외부 시스템을 잘못 호출하면 → MCP 서버에 가드 레일을 둔다.
래칫은 한쪽으로만 돌아가는 톱니바퀴예요. 한 번 조여놓으면 풀리지 않습니다. 하네스도 같은 방향으로만 자라나게 두면, 한 달, 두 달이 지났을 때 같은 모델이 같은 작업을 점점 더 잘 해내는 게 보입니다.
⑤ 실전: 하네스를 어떻게 키워나갈까
새 프로젝트에 Claude Code(혹은 다른 어떤 에이전트)를 처음 붙이는 날부터 시작합니다.
Day 0 : 시작점은 /init과 CLAUDE.md 작성부터
첫날에 만드는 건 단 하나, CLAUDE.md 한 장이에요. 60줄 이하, 다음 다섯 가지만 들어가면 충분합니다.
- 이 프로젝트의 한 줄 설명 (“Next.js 기반 인프런 강의 페이지 리뉴얼”)
- 코딩 스타일과 컨벤션(규칙) (들여쓰기, 네이밍, 함수 길이 등)
- 절대 하지 말 것 (“
main브랜치에 직접 푸시 금지”, “console.log남기지 말 것”) - 프로젝트에서 자주 쓰는 명령어 (테스트, 빌드, 마이그레이션)
- 중요한 도메인 사실
이게 첫 피드포워드 신호입니다.
Week 1 : 래칫 돌리기
며칠 써보면 에이전트가 같은 실수를 반복하는 패턴이 보입니다. 예를 들면
- “테스트를 임시로 주석 처리한다” →
CLAUDE.md에 한 줄 추가하고, 그래도 반복되면 git pre-commit hook으로 차단 - “새 라이브러리를 멋대로 설치한다” → 의존성 변경 시 사용자 승인을 받도록 규칙 추가
- “UI 컴포넌트 스타일을 자기 마음대로 짠다” → Storybook의 디자인 토큰 사용을 강제하는 규칙 추가
여기까지는 거의 텍스트 작업이에요. 코드를 쓰는 게 아니라, 에이전트의 행동 규칙을 글로 적는 작업입니다.
Week 2~4 : 도구·MCP·서브에이전트로 확장
그 다음 단계는 외부 세계로 확장입니다. 자주 마주치는 시나리오와 대응이에요.
- 최신 라이브러리 문서가 필요하다 → Context7 MCP 서버 연결. 모델 학습 시점 이후의 변경사항을 가져옵니다.
- 이슈/PR 관리가 들어간다 → GitHub MCP 또는 사내 이슈 트래커 MCP 연결.
- 같은 패턴의 멀티 스텝 작업을 반복한다 → Skill 또는 slash command로 묶기. 한 번에 다 펴 보여주지 말고 필요할 때만 펴게.
- 크고 독립적인 탐색 작업이 자주 있다 → 서브에이전트로 분리. 메인 컨텍스트를 깨끗하게 유지합니다.
피해야 할 안티패턴 세 가지
- 200줄 넘을 정도로 과도하게 큰
CLAUDE.md: 60줄을 마지노선으로 잡으세요. 실제 앤트로픽도 간결한 CLAUDE.md 를 권장합니다. - 50개의 겹치는 커스텀 도구: 모델이 어떤 걸 골라야 할지 혼란스러워합니다. 10개로 간추리세요.
- “프롬프트로만” 권한 통제하기: “
rm절대 쓰지 마”라고 적어두는 건 신뢰지 시스템이 아닙니다. hook이나 샌드박스로 막아야 신뢰가 돼요.
⑥ 어떤 도구를 쓸 것인가 : Claude Code를 추천하는 4가지 이유
지금 시점에 하네스 엔지니어링을 본격적으로 시작하려는 실무자에게는 Claude Code를 가장 먼저 권합니다. 네 가지 이유가 있어요.
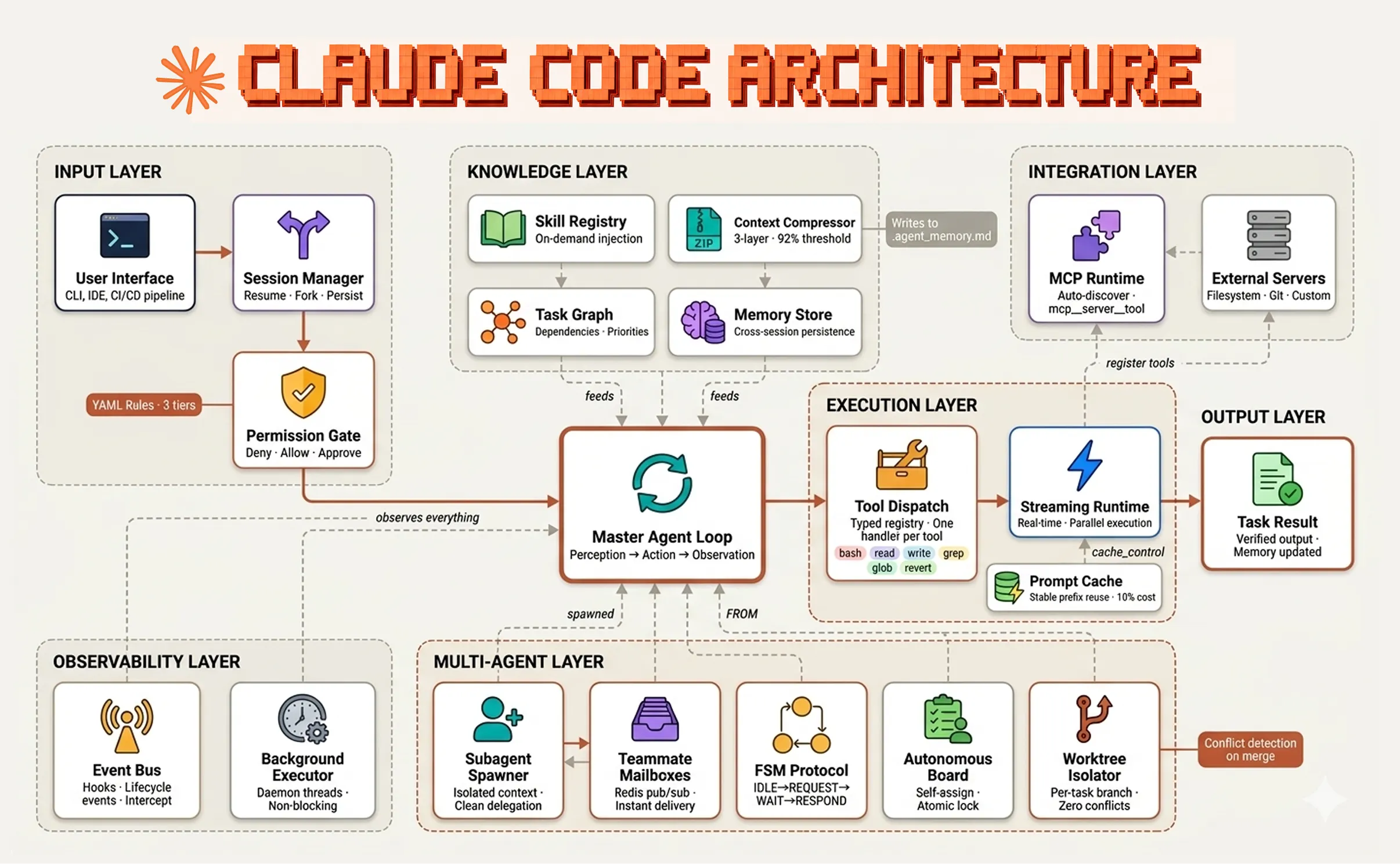
1) 확장성의 표면적이 가장 넓다
앞서 본 래칫 패턴의 모든 단계인 규칙 추가, 자동 차단, 외부 시스템 연결, 절차적 메모리, 병렬 작업 등에 대응하는 빌딩 블록이 모두 공식 기능으로 준비돼 있습니다. Skills(절차적 메모리), Hooks(피드백 센서), Plugins(번들 배포), Subagents(병렬 분리). 다른 도구들이 부분적으로 갖춘 기능을 이쪽은 한 묶음으로 제공해요.
2) MCP 생태계의 근원지, 가장 정교한 권한 모델
Model Context Protocol(MCP)을 만든 곳이 Anthropic입니다. 그래서 Claude Code의 MCP 통합은 가장 자연스럽고, 등장하는 새 MCP 서버들이 보통 Claude Code 기준으로 먼저 검증돼요.
권한 모델도 그 연장선이에요. 읽기/쓰기/실행이 분리되어 있고, 위험 동작마다 승인 요청 프롬프트가 뜨고, MCP 서버 단위로 권한을 묶어 관리할 수 있습니다. 이 부분이 정교한 만큼 사고를 막기에도 좋아요.
3) 엔지니어링 워크플로와의 통합 깊이
하네스의 피드백 측면(테스트, 린트, 빌드, PR 리뷰) 이 일상 워크플로 안에 자연스럽게 녹는지가 실제 만족도를 가릅니다. Claude Code는 git, IDE(VS Code/JetBrains 익스텐션), 터미널, CI 사이를 잇는 통합이 가장 매끄러워요. 같은 도구를 터미널에서 쓰다 IDE에서 이어 쓰고, hook을 통해 CI 단계와 연결할 수 있는 정도가 다릅니다.
4) 모델과 하네스가 한 회사에서 함께 진화한다
마지막이 가장 중요한 이유예요. Anthropic은 모델(Claude)과 하네스(Claude Code)를 동시에 설계합니다. 새 모델이 나오면 시스템 프롬프트, 도구 정의, 기본 권한 정책이 모델 특성에 맞춰 함께 업데이트돼요. 별개 회사가 만든 모델과 별개 회사가 만든 하네스를 조합할 때 발생하는 “모델-하네스 정렬 갭”이 가장 적습니다.
이건 한두 달의 차이가 아니라 1~2년에 걸쳐 누적되는 차이예요. 모델이 빠르게 변하는 시기일수록 더 그렇고요.
오늘 할 수 있는 한 가지
지금 쓰시는 코딩 에이전트의 CLAUDE.md(또는 AGENTS.md)를 열어, 어제 에이전트가 했던 가장 사소한 실수를 한 줄로 적어보세요. 그 한 줄이 가장 쉬운 하네스 엔지니어링이고, 첫 시작이 될 거예요. 두 달 뒤 같은 모델로 같은 작업을 시켰을 때, 결과가 어떻게 달라져 있는지 직접 확인해보시면 좋겠어요.
👇 하네스 엔지니어링, 강의로 배워보세요! 👇
생소한 개념일수록, 제대로 배우고 실행해야만 내 것으로 만들 수 있어요.
