









AI入門のためのLLMアーキテクチャの理解とGPU活用戦略
hyunjinkim

¥18,153
初級 / GPU, attention-model, AI, transformer, LLM
5.0
(10)
100+
Update
Update
頻繁な回答
頻繁な回答
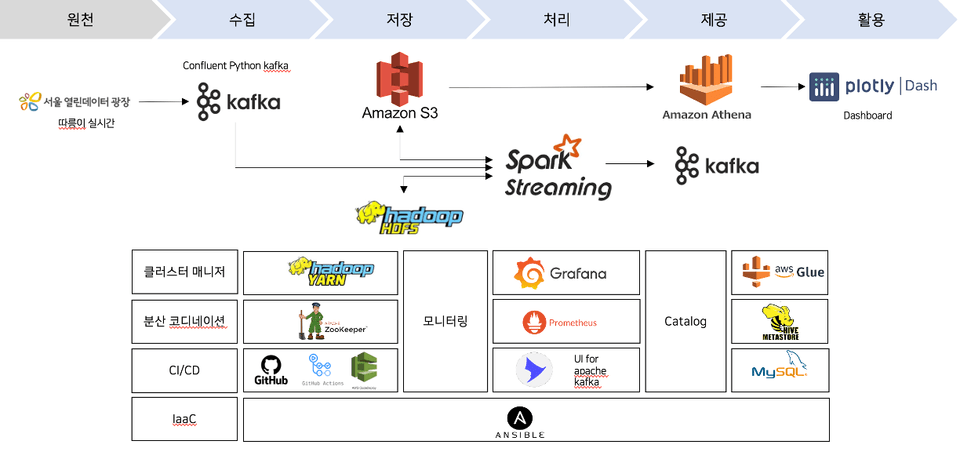
トランスフォーマーベースのLLMアーキテクチャとGPU活用戦略を理解し、vLLMを活用した実際のサービング過程まで直接実習します。 AIシステムパイプラインの構築からモニタリング、マルチGPUの活用まで実務フロー全体を扱い、 複雑な数式なしで図解と実習を中心に直感的に理解できるように構成された講義です。
初級
GPU, attention-model, AI




