Practical Data Science Part 3. Understanding Machine Learning
The digital transformation (DT) and introduction of artificial intelligence (AI) in companies begin with the construction of machine learning models. However, the scope of machine learning technology is very broad, and in order to select the optimal method, it is necessary to clearly understand the basic concepts. In this lecture, we will introduce the core contents necessary to clearly understand the basic concepts of machine learning, focusing on five examples.
I liked the detailed explanation of data analysis and machine learning.
5.0
이우광
70% enrolled
great.
5.0
정원태
60% enrolled
The detailed explanation helped me understand the overall flow.
What you will gain after the course
Understand the basics of what machine learning is and how it works.
Understand how to implement machine learning models in Python and various performance metrics to evaluate the performance of the model.
Understand the difference between traditional statistical analysis and machine learning, and learn key statistical techniques such as probability distributions, independence tests, and chi-square tests through examples.
Only the essential points are included! Understanding Machine Learning Fundamentals for Model Building
What is Machine Learning? 👩💻
Machine learning refers to software that performs tasks such as predicting numbers (regression), classifying categories, and making optimal recommendations. It refers to software that gradually improves its performance by observing and learning from data.
Machine learning is currently the most common method for implementing artificial intelligence. The core function of machine learning is to create a machine learning "model" that performs intelligent actions .
Machine Learning Models 📖
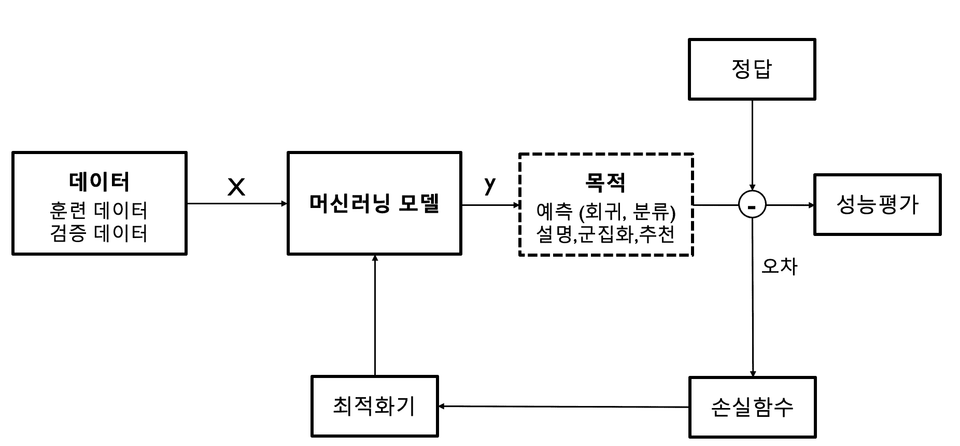
It refers to software that obtains the optimal output (y) from input data (X), and the optimal output means predicting the correct answer (label, target) well.
Model types include linear models, logistic regression, support vector machines (SVMs), decision trees, random forests, k-NN, Bayesian models, and deep learning models (MLPs, CNNs, and RNNs). While this lecture does not cover the specifics of these algorithms, it will teach you the basic and common methods for implementing machine learning models using linear models. The characteristics of each model will be covered in other lectures.
Machine Learning Model Components 🚦
1️⃣ Input data
To implement the optimal model, you must prepare the training data required to train the model and the validation data required to verify the operation of the trained model.
The process of creating appropriate training and validation data from raw data is data preprocessing , and data preprocessing greatly affects the performance of machine learning models.
2️⃣ Purpose of machine learning models
The purpose of using machine learning models is divided into four categories:
What you will learn in this course👨🏫
✅ Machine learning model
Learn an overview of machine learning and explore key concepts for understanding machine learning through five examples.
✅ Performance Evaluation
First, you will learn how to implement, train, and validate regression models, as well as model performance evaluation metrics such as R-squared, MAE, and RMSE.
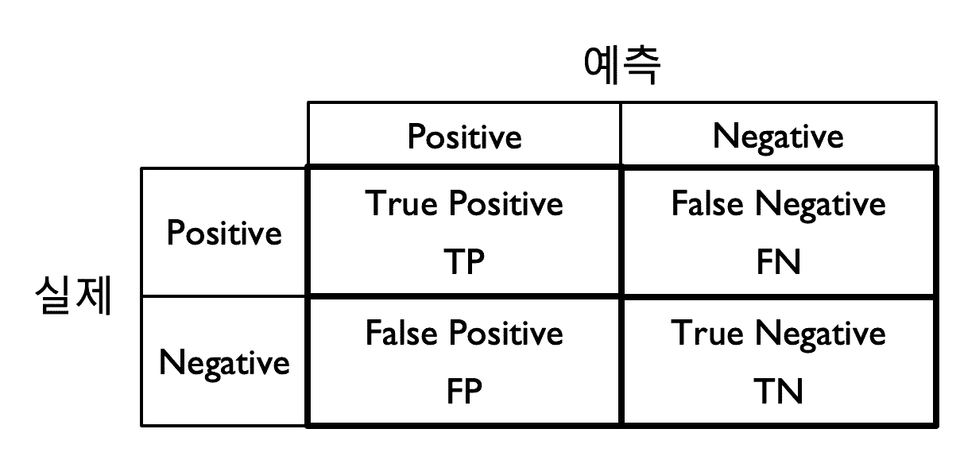
Next, we'll learn how to implement a classification model, as well as the concepts of decision boundaries, confusion matrices, accuracy, precision, recall, and the f-1 score. Evaluating classification performance requires a clear understanding of the confusion matrix, which we'll explain in detail through examples.
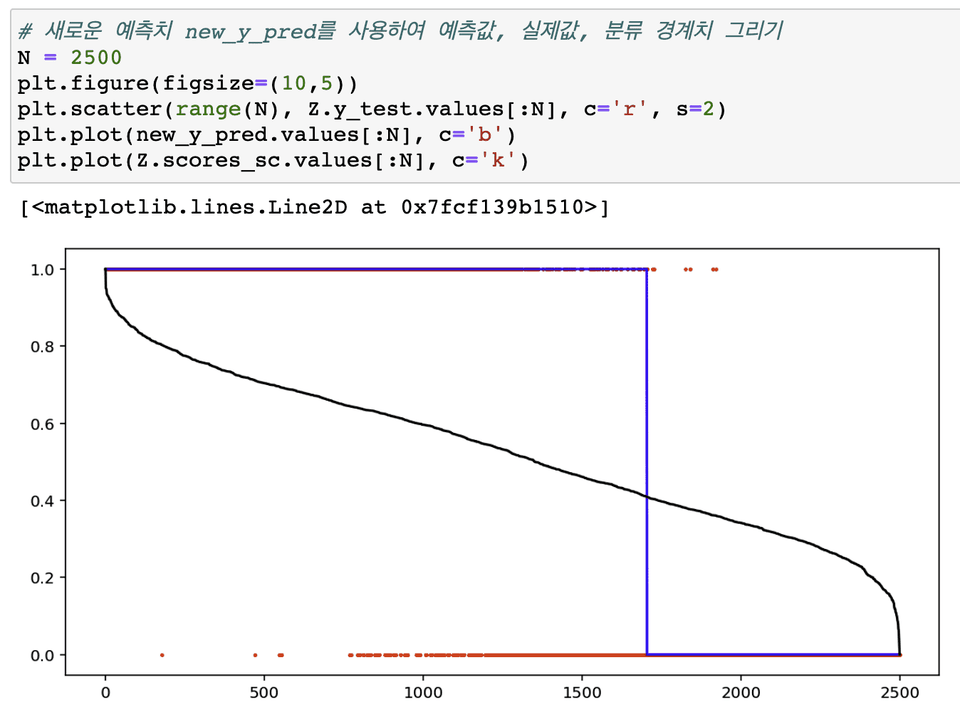
To comprehensively evaluate the performance of a classification model, the predicted ranking must be evaluated. To this end, we will explain how to use ROC-AUC and precision-recall curves.
✅ Finding classification thresholds
In real-world applications, classification models often have minimum precision or recall requirements, requiring selection of an optimal classification threshold that satisfies these requirements. This article details how to find the optimal threshold using the Precision-Recall curve.
✅ The Difference Between Statistical Analysis and Machine Learning
Machine learning While learning most Curious thing middle One With statistical analysis The difference Understanding Statistical analysis is divided into descriptive statistics, estimation , and hypothesis testing.
descriptive statistics
It refers to obtaining some meaning or insight contained in the data by understanding the average, standard deviation, probability distribution, correlation, etc. of the data.
estimation
There are point estimates that estimate specific numerical values such as the mean and standard deviation by looking at a sample and interval estimates that estimate confidence intervals.
testing hypothesis
This refers to testing whether the alternative hypothesis is correct by looking at sample data.
Statistics emphasizes explaining theoretical foundations, dealing with hypotheses, probabilities, confidence intervals, and margins of error. In contrast, machine learning focuses on creating software models that excel at prediction and classification, rather than providing theoretical foundations.
If the data to be analyzed is small, it is necessary to rely on statistical analysis for explanation, estimation, hypothesis testing, etc. However, if the data is sufficiently large, it is more useful to create a machine learning model that can be used in practice.
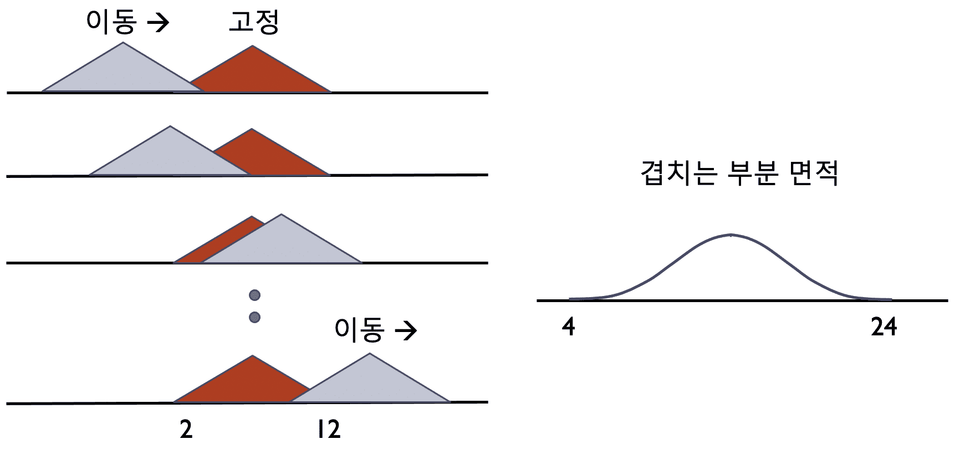
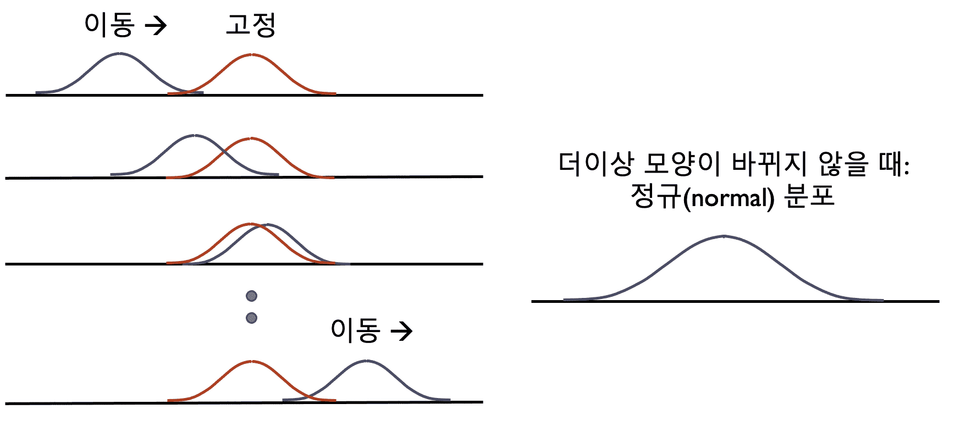
This lecture introduces the fundamentals of statistical analysis, including the characteristics of the normal distribution. For reference, the normal distribution is the probability distribution function of accumulated samples that converges and no longer changes (see figure below).
Python, the foundational language of data science. This course is designed to provide basic knowledge of Python. For those who do not have basic knowledge of the Python language,
Practical Data Science Part 1. Through an introductory Python lecture. I recommend learning player knowledge.
Practical Data Science Part 2: Data Preprocessing The most frequently used data analysis performance in businesses This is the lecture on data preprocessing that has the greatest impact. For those who want to learn more about data preprocessing, Practical Data Science Part 2. Data Preprocessing Lecture Learning I recommend it.
Recommended for these people
Who is this course right for?
For those who are learning the working principles of machine learning for the first time
If you need to apply machine learning to your work but find it difficult to invest a lot of time, this will be helpful for those who want to learn the core of machine learning in a short period of time.
This is a question a friend asked me after I entered the Department of Electronic Engineering. Well, I did answer. "In electronic engineering, we learn the principles of how to build a radio; fixing broken electronics isn't really what we do..."
There are more cases where a problem solver is needed rather than an expert armed with theory. I believe that solving real-world problems is more important.
Recently, I have been working on solving problems in various industrial sectors—such as finance, energy, electronics, heavy equipment, logistics, drug discovery, and food—using machine learning. It is a field with so much to learn and endless opportunities. Although my primary role is a professor (Department of Computer Science and Engineering at Kangwon National University), my deep interest in solving real-world problems has led me to hold several concurrent positions. I currently serve as the Director of the AI Drug Discovery Training Center, an Adjunct Professor at KAIST, and the CEO of Data Science Lab.
I believe that the most essential talent in the AI era is a data scientist who can solve real-world problems, and I hope all of you become highly sought-after data scientists.












![Deep Learning and PyTorch Bootcamp for Beginners (Easy! From Basics to ChatGPT's Core Transformer) [Data Analysis/Science Part 3]Course Thumbnail](https://cdn.inflearn.com/public/courses/329540/cover/1be7b8cb-800f-48cb-a30c-b7d78996c075/329540-eng.png?w=420)





![[ICT Archive] Big Data Core and Business ModelsCourse Thumbnail](https://cdn.inflearn.com/public/files/courses/338811/cover/01k44rs7zkwq0ehc8vqsy2mdtb?w=420)






![[Tensorflow2] Complete conquest of Python machine learning - Marathon record prediction projectCourse Thumbnail](https://cdn.inflearn.com/public/courses/324207/course_cover/1a79c7dc-1624-4d3a-95ff-79ba1e9c4025/python_machine_learning.png?w=420)
